Hadoop-Scala-Spark环境安装
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop-Scala-Spark环境安装相关的知识,希望对你有一定的参考价值。
参考技术A持续更新 请关注: https://zorkelvll.cn/blogs/zorkelvll/articles/2018/11/02/1541172452468
本文主要是介绍大数据基础设施软件Hadoop-Scala-Spark的安装过程,以macOS、linux等系统环境为例进行实践!
一、背景
二、实践-环境安装(macOS)
后添加
(4)配置core-site.xml【hdfs地址和端口】:vim /usr/local/Cellar/hadoop/3.0.0/libexec/etc/hadoop/core-site.xml => 添加配置
并且建立文件夹 mkdir /usr/local/Cellar/hadoop/hdfs & mkdir /usr/local/Cellar/hadoop/hdfs/tmp
先备份:cp /usr/local/Cellar/hadoop/3.0.0/libexec/etc/hadoop/mapred-site.xml mapred-site-bak.xml
再编辑:vim /usr/local/Cellar/hadoop/3.0.0/libexec/etc/hadoop/mapred-site.xml => 添加配置
(7)格式化hdfs文件系统格式:hdfs namenode -format
(8)启动及关闭hadoop服务:
/usr/local/Cellar/hadoop/3.0.0/libexec/start-dfs.sh => 守护进程:namenodes、datanodes、secondary namenodes,浏览器中访问 http://localhost:9870 ,注意端口号是9870而不是50070
/usr/local/Cellar/hadoop/3.0.0/libexec/start-yarn.sh => yarn服务进程:resourcemanager、nodemanagers,浏览器中访问 http://localhost:8088 和 http://localhost:8042
/usr/local/Cellar/hadoop/3.0.0/libexec/stop-yarn.sh
/usr/local/Cellar/hadoop/3.0.0/libexec/stop-dfs.sh
注意:brew方式安装的hadoop3.0.0,需要配置的hadoop路径是libexec下的,否则start-dfs.sh命令会报错“error:cannot execute hdfs-config”
以上是hadoop-scala-spark在mac下的安装过程,为昨天在mac下首次实践,一次性成功 => 希望能够对各位同学有所帮助,和得到各位同学的后续关注,如果疑问或者遇到的坑,欢迎在文章下面留言!!
spark开启之路 : https://spark.apache.org/docs/latest/quick-start.html
Flask 安装环境(虚拟环境安装)
Flask 安装环境
使用虚拟环境安装Flask,可以避免包的混乱和冲突,虚拟环境是python解释器的副本,在虚拟环境中你可以安装扩展包,为每个程序
单独创建虚拟环境,可以保证程序只能访问虚拟环境中的包。
第一步
下载virtualenv库
pip install virtualenv -i https://pypi.tuna.tsinghua.edu.cn/simple
第二步
为项目搭建虚拟环境
virtualenv flask_env
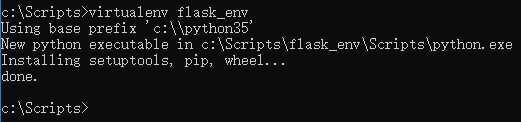
创建成功后,会在当前文件夹中创建关于虚拟环境配置的的文件夹:

第三步
进入创建的虚拟环境文件,在Scripts文件夹中,使用命令:activate:
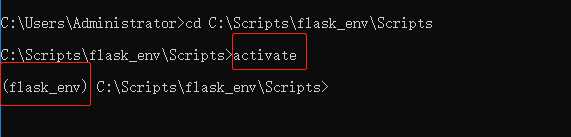
默认情况下,virtualenv已经安装好了pip。
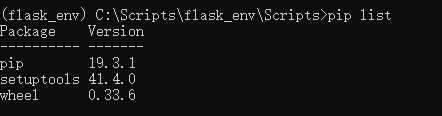
第四步
在启动虚拟环境后直接使用pip install 命令就可以为该虚拟环境安装类库:
pip install flask==0.10.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
第五步
在Pycharm中使用配置好的虚拟环境
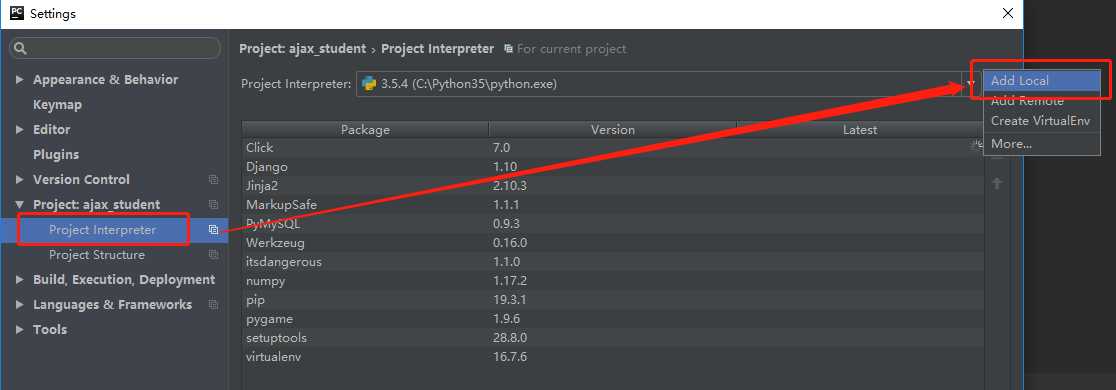
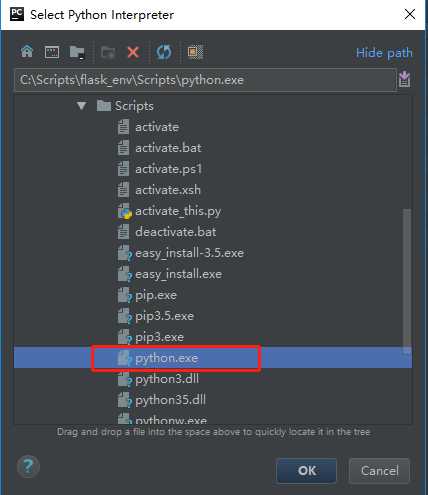
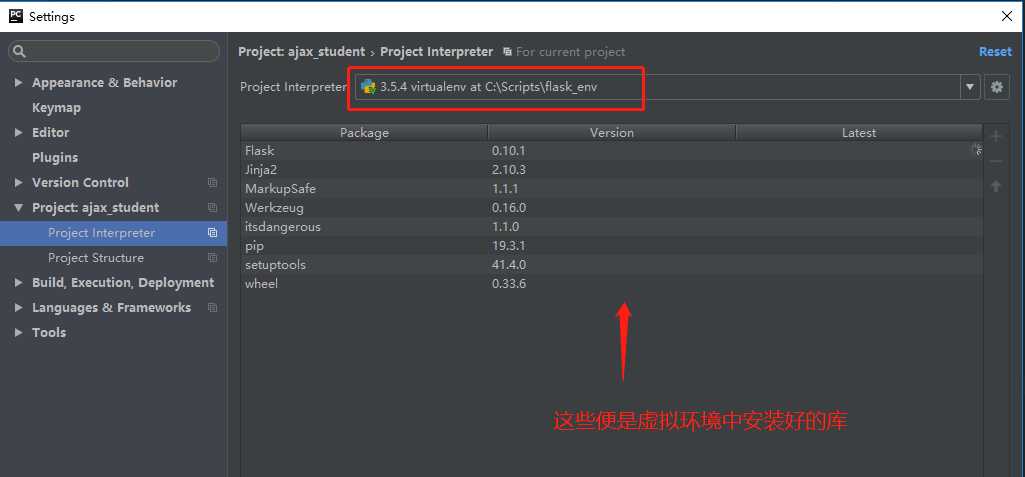
第六步
可以离开虚拟环境,使用deactivate命令

以上是关于Hadoop-Scala-Spark环境安装的主要内容,如果未能解决你的问题,请参考以下文章