Spark整合kafka0.10.0新特性
Posted javartisan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark整合kafka0.10.0新特性相关的知识,希望对你有一定的参考价值。
接着Spark整合kafka0.10.0新特性(一)开始
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "localhost:9092,anotherhost:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "use_a_separate_group_id_for_each_stream",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topics = Array("topicA", "topicB")
val stream = KafkaUtils.createDirectStream[String, String](
streamingContext,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
stream.map(record => (record.key, record.value))分析完位置策略和消费策略,接下来先看看org.apache.spark.streaming.kafka010.KafkaUtils$#createDirectStream的具体实现:
@Experimental
def createDirectStream[K, V](
ssc: StreamingContext,
locationStrategy: LocationStrategy,
consumerStrategy: ConsumerStrategy[K, V]): InputDStream[ConsumerRecord[K, V]] = {
val ppc = new DefaultPerPartitionConfig(ssc.sparkContext.getConf)
createDirectStream[K, V](ssc, locationStrategy, consumerStrategy, ppc)
}返回的是InputDStream[ConsumerRecord[K,V]]类型,查看一下ConsumerRecord类型:
/**
* A key/value pair to be received from Kafka. This consists of a topic name and a partition number, from which the
* record is being received and an offset that points to the record in a Kafka partition.
* 从Kafka接受到的消息对key/value,包含topic名字、分区编号、以及消息在分区的offset
*/
public final class ConsumerRecord<K, V> {
public static final long NO_TIMESTAMP = Record.NO_TIMESTAMP;
public static final int NULL_SIZE = -1;
public static final int NULL_CHECKSUM = -1;
private final String topic;
private final int partition;
private final long offset;
private final long timestamp;
private final TimestampType timestampType;
private final long checksum;
private final int serializedKeySize;
private final int serializedValueSize;
private final K key;
private final V value;
等等省略
}关于InputDStream具体细节略,看一下类继承结构:
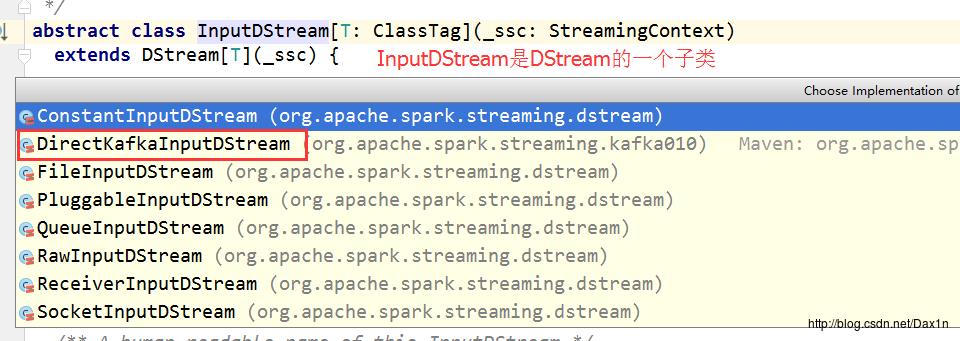
所以createDirectStream返回的具体类型是DirectKafkaInputDStream。
接着在createDirectStream中创建DefaultPerPartitionConfig,DefaultPerPartitionConfig就是一个设置每一个分区获取消息的组大数率,设置参数为spark.streaming.kafka.maxRatePerPartition.源码如下:
package org.apache.spark.streaming.kafka010
import org.apache.kafka.common.TopicPartition
import org.apache.spark.SparkConf
import org.apache.spark.annotation.Experimental
/**
* :: Experimental ::
* Interface for user-supplied configurations that can't otherwise be set via Spark properties,
* because they need tweaking on a per-partition basis,
*
* 为用户提供的一个配置接口,但是这些参数不可以使用spark配置文件进行配置,因为spark配置文件配置,因为他们需要
* 对每一个分区的比率进行调整。可以使用SparkConf进行设置数率
*/
@Experimental
abstract class PerPartitionConfig extends Serializable {
/**
* Maximum rate (number of records per second) at which data will be read
* from each Kafka partition.
*
*从Kafka分区中读取数据的最大比率(每秒最大记录数)
*/
def maxRatePerPartition(topicPartition: TopicPartition): Long
}
/**
* Default per-partition configuration
*/
private class DefaultPerPartitionConfig(conf: SparkConf)
extends PerPartitionConfig {
val maxRate = conf.getLong("spark.streaming.kafka.maxRatePerPartition", 0)
//从Kafka分区中读取数据的最大比率(每秒最大记录数)
def maxRatePerPartition(topicPartition: TopicPartition): Long = maxRate
}创建完毕PerPartitionConfig之后再次调用createDirectStream的重载方法:
def createDirectStream[K, V](
ssc: StreamingContext,
locationStrategy: LocationStrategy,
consumerStrategy: ConsumerStrategy[K, V],
perPartitionConfig: PerPartitionConfig
): InputDStream[ConsumerRecord[K, V]] = {
new DirectKafkaInputDStream[K, V](ssc, locationStrategy, consumerStrategy, perPartitionConfig)
}接下来重点查看DirectKafkaInputDStream的构造器(注意:Scala类的构造器是从类定义的左{开始到右}结束都是主构造器):
package org.apache.spark.streaming.kafka010 import java.{util => ju} import java.util.concurrent.ConcurrentLinkedQueue import java.util.concurrent.atomic.AtomicReference import scala.annotation.tailrec import scala.collection.JavaConverters._ import scala.collection.mutable import org.apache.kafka.clients.consumer._ import org.apache.kafka.common.{PartitionInfo, TopicPartition} import org.apache.spark.SparkException import org.apache.spark.internal.Logging import org.apache.spark.storage.StorageLevel import org.apache.spark.streaming.{StreamingContext, Time} import org.apache.spark.streaming.dstream._ import org.apache.spark.streaming.scheduler.{RateController, StreamInputInfo} import org.apache.spark.streaming.scheduler.rate.RateEstimator /** * * each given Kafka topic/partition corresponds to an RDD partition. * The spark configuration spark.streaming.kafka.maxRatePerPartition gives the maximum number * of messages * per second that each '''partition''' will accept. * * 每个topic的每一个分区对应一个RDD分区 * spark的spark.streaming.kafka.maxRatePerPartition参数配置指定了每秒每一个topic的每一个分区获取的最大消息数 * * @param locationStrategy In most cases, pass in [[PreferConsistent]], * see [[LocationStrategy]] for more details. * @param executorKafkaParams Kafka * <a href="http://kafka.apache.org/documentation.html#newconsumerconfigs"> * configuration parameters</a>. * Requires "bootstrap.servers" to be set with Kafka broker(s), * NOT zookeeper servers, specified in host1:port1,host2:port2 form. * @param consumerStrategy In most cases, pass in [[Subscribe]], * see [[ConsumerStrategy]] for more details * @tparam K type of Kafka message key Kafka消息的Key * @tparam V type of Kafka message value Kafka消息的Value */ private[spark] class DirectKafkaInputDStream[K, V]( _ssc: StreamingContext, locationStrategy: LocationStrategy, consumerStrategy: ConsumerStrategy[K, V], ppc: PerPartitionConfig ) extends InputDStream[ConsumerRecord[K, V]](_ssc) with Logging with CanCommitOffsets { val executorKafkaParams = { val ekp = new ju.HashMap[String, Object](consumerStrategy.executorKafkaParams) //根据具体的executor调整参数,防止在executor上出问题 KafkaUtils.fixKafkaParams(ekp) ekp } //存入当前偏移的 protected var currentOffsets = Map[TopicPartition, Long]() //如果偏移量为1的话,则设置偏移为1 @transient private var kc: Consumer[K, V] = null def consumer(): Consumer[K, V] = this.synchronized { if (null == kc) { kc = consumerStrategy.onStart(currentOffsets.mapValues(l => new java.lang.Long(l)).asJava) } kc } override def persist(newLevel: StorageLevel): DStream[ConsumerRecord[K, V]] = { logError("Kafka ConsumerRecord is not serializable. " + "Use .map to extract fields before calling .persist or .window") super.persist(newLevel) } // protected def getBrokers = { val c = consumer val result = new ju.HashMap[TopicPartition, String]() val hosts = new ju.HashMap[TopicPartition, String]() //assignment()获取该Consumer的TopicPartition,返回Set<TopicPartition>集合 val assignments = c.assignment().iterator() //两层while循环实现获取 while (assignments.hasNext()) { val tp: TopicPartition = assignments.next() //当前的TopicPartition的主机地址没有的话,需要根据去kafka集群查找该TopicPartition的主机地址 if (null == hosts.get(tp)) { //partitionsFor获取给定topic和partition的元数据,如果本地没有会发起rpc val infos = c.partitionsFor(tp.topic).iterator() while (infos.hasNext()) { val i = infos.next() //TopicPartition重写了equals方法 hosts.put(new TopicPartition(i.topic(), i.partition()), i.leader.host()) } } //TopicPartition重写了equals方法,所以可以hosts.get(tp) //到此处就获取到了分区和分区的地址 result.put(tp, hosts.get(tp)) } result } protected def getPreferredHosts: ju.Map[TopicPartition, String] = { locationStrategy match { case PreferBrokers => getBrokers case PreferConsistent => ju.Collections.emptyMap[TopicPartition, String]() case PreferFixed(hostMap) => hostMap } } // Keep this consistent with how other streams are named (e.g. "Flume polling stream [2]") private[streaming] override def name: String = s"Kafka 0.10 direct stream [$id]" protected[streaming] override val checkpointData = new DirectKafkaInputDStreamCheckpointData /** * Asynchronously maintains & sends new rate limits to the receiver through the receiver tracker. */ override protected[streaming] val rateController: Option[RateController] = { if (RateController.isBackPressureEnabled(ssc.conf)) { Some(new DirectKafkaRateController(id, RateEstimator.create(ssc.conf, context.graph.batchDuration))) } else { None } } protected[streaming] def maxMessagesPerPartition( offsets: Map[TopicPartition, Long]): Option[Map[TopicPartition, Long]] = { val estimatedRateLimit = rateController.map(_.getLatestRate()) // calculate a per-partition rate limit based on current lag val effectiveRateLimitPerPartition = estimatedRateLimit.filter(_ > 0) match { case Some(rate) => val lagPerPartition = offsets.map { case (tp, offset) => tp -> Math.max(offset - currentOffsets(tp), 0) } val totalLag = lagPerPartition.values.sum lagPerPartition.map { case (tp, lag) => val maxRateLimitPerPartition = ppc.maxRatePerPartition(tp) val backpressureRate = Math.round(lag / totalLag.toFloat * rate) tp -> (if (maxRateLimitPerPartition > 0) { Math.min(backpressureRate, maxRateLimitPerPartition) } else backpressureRate) } case None => offsets.map { case (tp, offset) => tp -> ppc.maxRatePerPartition(tp) } } if (effectiveRateLimitPerPartition.values.sum > 0) { val secsPerBatch = context.graph.batchDuration.milliseconds.toDouble / 1000 Some(effectiveRateLimitPerPartition.map { case (tp, limit) => tp -> (secsPerBatch * limit).toLong }) } else { None } } /** * The concern here is that poll might consume messages despite being paused, * which would throw off consumer position. Fix position if this happens. */ private def paranoidPoll(c: Consumer[K, V]): Unit = { val msgs = c.poll(0) if (!msgs.isEmpty) { // position should be minimum offset per topicpartition msgs.asScala.foldLeft(Map[TopicPartition, Long]()) { (acc, m) => val tp = new TopicPartition(m.topic, m.partition) val off = acc.get(tp).map(o => Math.min(o, m.offset)).getOrElse(m.offset) acc + (tp -> off) }.foreach { case (tp, off) => logInfo(s"poll(0) returned messages, seeking $tp to $off to compensate") c.seek(tp, off) } } } /** * Returns the latest (highest) available offsets, taking new partitions into account. */ protected def latestOffsets(): Map[TopicPartition, Long] = { val c = consumer paranoidPoll(c) val parts = c.assignment().asScala // make sure new partitions are reflected in currentOffsets val newPartitions = parts.diff(currentOffsets.keySet) // position for new partitions determined by auto.offset.reset if no commit currentOffsets = currentOffsets ++ newPartitions.map(tp => tp -> c.position(tp)).toMap // don't want to consume messages, so pause c.pause(newPartitions.asJava) // find latest available offsets c.seekToEnd(currentOffsets.keySet.asJava) parts.map(tp => tp -> c.position(tp)).toMap } // limits the maximum number of messages per partition protected def clamp( offsets: Map[TopicPartition, Long]): Map[TopicPartition, Long] = { maxMessagesPerPartition(offsets).map { mmp => mmp.map { case (tp, messages) => val uo = offsets(tp) tp -> Math.min(currentOffsets(tp) + messages, uo) } }.getOrElse(offsets) } override def compute(validTime: Time): Option[KafkaRDD[K, V]] = { val untilOffsets = clamp(latestOffsets()) val offsetRanges = untilOffsets.map { case (tp, uo) => val fo = currentOffsets(tp) OffsetRange(tp.topic, tp.partition, fo, uo) } val rdd = new KafkaRDD[K, V]( context.sparkContext, executorKafkaParams, offsetRanges.toArray, getPreferredHosts, true) // Report the record number and metadata of this batch interval to InputInfoTracker. val description = offsetRanges.filter { offsetRange => // Don't display empty ranges. offsetRange.fromOffset != offsetRange.untilOffset }.map { offsetRange => s"topic: ${offsetRange.topic}\\tpartition: ${offsetRange.partition}\\t" + s"offsets: ${offsetRange.fromOffset} to ${offsetRange.untilOffset}" }.mkString("\\n") // Copy offsetRanges to immutable.List to prevent from being modified by the user val metadata = Map( "offsets" -> offsetRanges.toList, StreamInputInfo.METADATA_KEY_DESCRIPTION -> description) val inputInfo = StreamInputInfo(id, rdd.count, metadata) ssc.scheduler.inputInfoTracker.reportInfo(validTime, inputInfo) currentOffsets = untilOffsets commitAll() Some(rdd) } override def start(): Unit = { val c = consumer paranoidPoll(c) if (currentOffsets.isEmpty) { currentOffsets = c.assignment().asScala.map { tp => tp -> c.position(tp) }.toMap } // don't actually want to consume any messages, so pause all partitions c.pause(currentOffsets.keySet.asJava) } override def stop(): Unit = this.synchronized { if (kc != null) { kc.close() } } protected val commitQueue = new ConcurrentLinkedQueue[OffsetRange] protected val commitCallback = new AtomicReference[OffsetCommitCallback] /** * Queue up offset ranges for commit to Kafka at a future time. Threadsafe. * * @param offsetRanges The maximum untilOffset for a given partition will be used at commit. */ def commitAsync(offsetRanges: Array[OffsetRange]): Unit = { commitAsync(offsetRanges, null) } /** * Queue up offset ranges for commit to Kafka at a future time. Threadsafe. * * @param offsetRanges The maximum untilOffset for a given partition will be used at commit. * @param callback Only the most recently provided callback will be used at commit. */ def commitAsync(offsetRanges: Array[OffsetRange], callback: OffsetCommitCallback): Unit = { commitCallback.set(callback) commitQueue.addAll(ju.Arrays.asList(offsetRanges: _*)) } protected def commitAll(): Unit = { val m = new ju.HashMap[TopicPartition, OffsetAndMetadata]() var osr = commitQueue.poll() while (null != osr) { val tp = osr.topicPartition val x = m.get(tp) val offset = if (null == x) { osr.untilOffset } else { Math.max(x.offset, osr.untilOffset) } m.put(tp, new OffsetAndMetadata(offset)) osr = commitQueue.poll() } if (!m.isEmpty) { consumer.commitAsync(m, commitCallback.get) } } private[streaming] class DirectKafkaInputDStreamCheckpointData extends DStreamCheckpointData(this) { def batchForTime: mutable.HashMap[Time, Array[(String, Int, Long, Long)]] = { data.asInstanceOf[mutable.HashMap[Time, Array[OffsetRange.OffsetRangeTuple]]] } override def update(time: Time): Unit = { batchForTime.clear() generatedRDDs.foreach { kv => val a = kv._2.asInstanceOf[KafkaRDD[K, V]].offsetRanges.map(_.toTuple).toArray batchForTime += kv._1 -> a } } override def cleanup(time: Time): Unit = {} override def restore(): Unit = { batchForTime.toSeq.sortBy(_._1)(Time.ordering).foreach { case (t, b) => logInfo(s"Restoring KafkaRDD for time $t ${b.mkString("[", ", ", "]")}") generatedRDDs += t -> new KafkaRDD[K, V]( context.sparkContext, executorKafkaParams, b.map(OffsetRange(_)), getPreferredHosts, // during restore, it's possible same partition will be consumed from multiple // threads, so dont use cache false ) } } } /** * A RateController to retrieve the rate from RateEstimator. */ private[streaming] class DirectKafkaRateController(id: Int, estimator: RateEstimator) extends RateController(id, estimator) { override def publish(rate: Long): Unit = () } }
完成DirectKafkaInputDStream的创建,到此处都是transformation过程,此时还没有遇到action算子开始执行。
其中DirectKafkaInputDStream的compute方法就是有StreamingContext的start方法间接最终调用的。compute方法负责生成KafkaRDD的:
override def compute(validTime: Time): Option[KafkaRDD[K, V]] = { val untilOffsets = clamp(latestOffsets()) val offsetRanges = untilOffsets.map { case (tp, uo) => val fo = currentOffsets(tp) OffsetRange(tp.topic, tp.partition, fo, uo) } val rdd = new KafkaRDD[K, V]( context.sparkContext, executorKafkaParams, offsetRanges.toArray, getPreferredHosts, true)//重点方法,位置策略 // Report the record number and metadata of this batch interval to InputInfoTracker. val description = offsetRanges.filter { offsetRange => // Don't display empty ranges. offsetRange.fromOffset != offsetRange.untilOffset }.map { offsetRange => s"topic: ${offsetRange.topic}\\tpartition: ${offsetRange.partition}\\t" + s"offsets: ${offsetRange.fromOffset} to ${offsetRange.untilOffset}" }.mkString("\\n") // Copy offsetRanges to immutable.List to prevent from being modified by the user val metadata = Map( "offsets" -> offsetRanges.toList, StreamInputInfo.METADATA_KEY_DESCRIPTION -> description) val inputInfo = StreamInputInfo(id, rdd.count, metadata) ssc.scheduler.inputInfoTracker.reportInfo(validTime, inputInfo) currentOffsets = untilOffsets commitAll() Some(rdd) }
关于位置策略的看的还不是很透彻,改天再研究一下:
org.apache.spark.streaming.kafka010.DirectKafkaInputDStream#getPreferredHosts方法。
补充:Streaming作业的产生和执行都是由StreamingContext的start方法开始的。
以上是关于Spark整合kafka0.10.0新特性的主要内容,如果未能解决你的问题,请参考以下文章