开启线程池和进程池
Posted 科幻vs现实
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了开启线程池和进程池相关的知识,希望对你有一定的参考价值。
线程与进程的应用场合很多,主要处理并发与多任务。然而,当开启的线程与进程过多时,系统的开销过多会造成性能低下甚至崩溃。这时,希望出现一种方法能规定只能执行指定数量线程与进程的策略。特别是针对不知道要开启多少线程或进程,而有可能出现线程或进程过多的情况。于是,线程池与进程池出现了。python3以后增加了concurrent.futures模块,为异步执行提供了高级的接口。
线程池
concurrent.futures.ThreadPoolExecutor(max_workers=None, thread_name_prefix=\'\'): 线程池,提供能异步地执行任务的线程。
参数max_workers为最大的能提供线程的个数,默认为CPU的核数乘5,如果CPU为四核那么能开启的最大线程数为20。
参数thread_name_prefix为线程名前缀,为了方便控制线程和调试线程。
ThreadPoolExecutor下面有submit,map,shutdown方法:
submit(fn, *args, **kwargs)方法将返回一个futurn对象,代表将要执行或未完成的任务的结果。map(func, *iterables, timeout=None, chunksize=1)将返回一个迭代器iter,没弄next方法执行iter一次,将并发max_workers个线程。shutdown(wait=True)将释放完成任务的线程池所占的所有资源,参数wait如果为True,则等待未完成的任务。如果使用with,则不用显示地调用。
注意: shutdown方法的wait不管是True或是False,解释器都会把剩余的任务执行完。区别就是一个是等待(阻塞),一个是不等待。
Future对象
Future对象为Executor.submit()执行后的结果,代表将要执行或未完成的任务的结果。注意,不用手动调用concurrent.futures.Future生成Future对象。 它有以下多种方法:
cancel(): 试图取消任务。如果当前任务正在被执行而且不能取消,返回False,否则此任务被取消并返回True。cancelled(): 如果任务成功地取消,返回Truerunning(): 如果当前任务正在被执行而且不能取消,返回Truedone(): 如果任务被完成或成功地被取消则返回Trueresult(timeout=None): 返回任务的结果,如果任务未完成则等待timeout秒。exception(timeout=None):在timeout秒内返回任务的异常add_done_callback(fn): 添加回调函数。并且futurnd对象最为回调函数的唯一参数,无论任务被取消或完成。
import requests, time from bs4 import BeautifulSoup from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor, as_completed URLS = [ \'http://www.baidu.com\', \'http://www.bing.com\', \'http://wwww.sougou.com\', \'http://www.soso.com\' ] def get_page_title(url, timeout): \'\'\'得到页面的标题\'\'\' html = requests.get( # 使用requests发送get请求 url=url, timeout=timeout, headers = { \'User-Agent\': \'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:51.0) Gecko/20100101 Firefox/51.0\' } ) # print(html.text) soup = BeautifulSoup(html.text, "html.parser") # 解析文档 title = soup.find(\'title\') # 得到页面的标题 return title.text with ThreadPoolExecutor(max_workers=4) as excutor: # 使用with得到一个最大线程数为4的线程池 start = time.time() future_and_url = {excutor.submit(get_page_title, url, 10):url for url in URLS} # 提交任务 for future in as_completed(future_and_url): # 使用as_completed返回一个已完成任务的迭代器 url = future_and_url[future] try: data = future.result() # 得到任务的结果 except Exception as e: print("has occured exception:", e) else: cost_time = time.time() - start print("got title:%s"%data, \'spend %ss\'%cost_time)
输出为:
got title:百度一下,你就知道 spend 0.28019237518310547s got title:搜狗搜索引擎 - 上网从搜狗开始 spend 0.3059103488922119s got title:搜狗®宠物 | 热门论谈 spend 1.7201545238494873s got title:微软必应搜索 - 全球搜索,有问必应 (Bing) spend 10.456863164901733s
进程池
进程池同样也提供能异步执行任务的进程,不同的是它能有效地回避全局解释锁的限制。一个进程会开辟独立的空间,所以进程运行着自己的解释器,互不影响。
concurrent.futures.ProcessPoolExecutor(max_workers=None): 进程池,max_workers与线程不同的是默认为CPU的核数。
先用线程试试看,在比较。def is_perfect_number(number): \'\'\'判断是否为完美数\'\'\' sum = 0 for i in range(1,number): if number%i == 0: sum += i if sum == number: return True return False def find_perfect_number_t(number): \'\'\'利用线程寻找这个数字范围内所有的完美数\'\'\' perfect_number = [] start_time = time.time() with ThreadPoolExecutor() as executor: future_dict = {executor.submit(is_perfect_number, i): i for i in range(1, number)} for future in as_completed(future_dict): if future.result(): perfect_number.append(future_dict[future]) print(\'The perfect number of %s is:\'%number, perfect_number) print(\'has spend %ss\'%(time.time()-start_time))
执行:
find_perfect_number_t(25000)
输出为:
The perfect number of 25000 is: [6, 28, 496, 8128] has spend 134.63016271591187s
现在我们改换进程:
def find_perfect_number_p(number): \'\'\'利用进程寻找这个数字范围内所有的完美数\'\'\' perfect_number = [] start_time = time.time() with ProcessPoolExecutor() as executor: future_dict = {executor.submit(is_perfect_number, i): i for i in range(1, number)} for future in as_completed(future_dict): if future.result(): perfect_number.append(future_dict[future]) print(\'The perfect number of %s is:\'%number, perf
再执行:
find_perfect_number_p(25000)
输出为:
The perfect number of 25000 is: [6, 496, 28, 8128] has spend 45.46505379676819s
这是运行线程代码的cpu负载图:
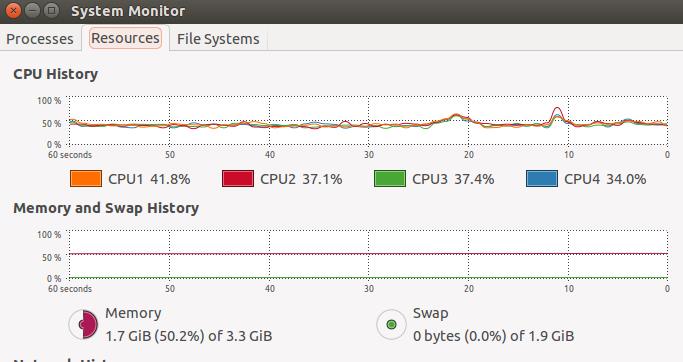
这是进程的负载图:
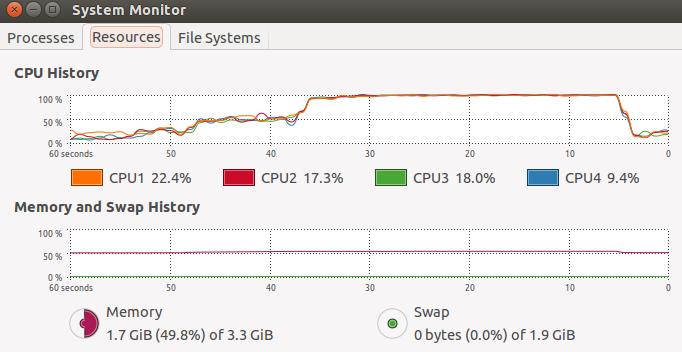
结论:
上面的例子很好地展示了线程与进程的区别。我的CPU为四核,python的多线程只使用了CPU一个核,CPU使用率只有35%。多进程充分利用了全部CPU,使用率达到100%。但进程的创建和销毁所消耗的资源比线程大得多,所以在运算量不大的情况下,使用线程其实还是要比进程快。python中多进程适用解决大运算量问题并且充分利用CPU的情况。
以上是关于开启线程池和进程池的主要内容,如果未能解决你的问题,请参考以下文章