难得二逼的协程,事件驱动和异步IO
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了难得二逼的协程,事件驱动和异步IO相关的知识,希望对你有一定的参考价值。
先来回顾一下多线程和多进程把。多线程像是在一个国家内,由A点往B点搬运东西,一条线程就是一条路,多条线程就是开启多条路,然后每条路上可以运输东西。多进程就像多个国家,每个国家里面在执行自己的事情。
然后轮到今天的主角:协程出场
1.携程
corotine, 是一种用户态的轻量级线程,被称为微线程。是自己控制的,cpu不知道其存在。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈。
协程的好处:
? 无需线程上下文切换的开销
? 无需原子操作锁定及同步的开销
? "原子操作(atomic operation)是不需要synchronized",所谓原子操作是指不会被线程调度机制打断的操作;这种操作一旦开始,就一直运行到结束,中间不会有任何 context switch (切换到另一个线程)。原子操作可以是一个步骤,也可以是多个操作步骤,但是其顺序是不可以被打乱,或者切割掉只执行部分。视作整体是原子性的核心。
? 方便切换控制流,简化编程模型
? 高并发+高扩展性+低成本:一个CPU支持上万的协程都不是问题。所以很适合用于高并发处理。
缺点:
? 无法利用多核资源:协程的本质是个单线程,它不能同时将 单个CPU 的多个核用上,协程需要和进程配合才能运行在多CPU上.当然我们日常所编写的绝大部分应用都没有这个必要,除非是cpu密集型应用。 (多个进程占用多个CPU,在进程中启用线程,然后在线程中启用协程)
? 进行阻塞(Blocking)操作(如IO时)会阻塞掉整个程序
协程是单线程的,是串行的,但是要让他看起来像是并行,需要CPU进行不断的切换。
但是什么时候进程切换呢?是在遇到IO操作的时候。
那什么时候在切回去呢? 在IO操作结束后,自动切回去。那系统是怎么实现检测的呢?,python中有一个封装好的模块:gevent可以帮助实现切换
greenlet 是封装好了的协程,可以手动执行切换,是手动挡
gevent 是自动挡,自动挡(genent)封装了手动挡(greenlet)。
import gevent
def foo():
print(‘Running in foo‘)
gevent.sleep(2)
print(‘Explicit context switch to foo again‘)
def bar():
print(‘Explict context to bar‘)
gevent.sleep(1)
print(‘Implicit context switch to bar‘)
gevent.joinall([
gevent.spawn(foo), #生成,产生,发起
gevent.spawn(bar),
])
注意在foo中切到了bar中,然后在bar中切回到foo中,但这时候foo中还是sleep,所以会卡住1秒。
Alex的博客上有一个图很经典,清晰地描述了单线程,多线程,还有携程之间的关系。http://www.cnblogs.com/alex3714/articles/5248247.html
2.事件驱动
生活中很多微小的事情,其背后可能用到的思路会很复杂;而我们觉得它简单是因为我们不知道复杂的思路,但是我们一旦发现了,就会觉得原来这么微小的事情中居然包含着这么复杂的道理。
那就从微小的:鼠标点击事件开始讲起。当鼠标点下word图标,那么系统就会启动打开word这个命令,但是在这当中,鼠标是不是就不能活动了呢?当然不是,鼠标还可以点击excel图标,打开excel. 那鼠标是怎么做到能时刻待命,等待我们的信息的呢?难道是创造一个线程,然后时刻检查鼠标有没有按下吗?这样这个线程一直都在工作,会占用很大资源。为了解决这个问题,牛人们就设计了“事件驱动模型”。 简单说就是有一个消息队列,然后每次来的消息,都放到消息队列中,然后系统每次都从队列中取出事件,调用不同的函数。因为事件一般都保留有自己的指针,所以每个消息都有独立处理的函数。
事件驱动模型比多线程更加方便(不用加锁),比单线程更加高效(不用占用过多的资源)。
3.IO
IO 是什么?Input 和Output,相当于是门户。其实有两种IO, 磁盘的IO,网络的IO。我们这里讨论一下网络的IO。
经常会听到”IO阻塞“这个词,那这是什么意思呢?是指进程因为期待的一些事情没有发生,或者请求没有得到回复,而自己进入等待模式,相当于IO就阻塞了。
缓存IO: Linux的缓存IO机制中,操作系统会先把IO的数据缓存在文件系统的缓存页中。也就是说数据会先被拷贝到内核的缓冲区,然后再拷贝到应用程序的内存。数据会从内核态——>用户态。
数据在传输过程中,需要在自己的内存空间和内核之间进行多次拷贝。所以数据拷贝过程中对CPU和内存的消耗是很大的。
IO 模式: 1.数据准备,2.将数据从内核拷贝到程序的内存空间。因为这两个步骤,所以Linux生成了3种通信方式。
- 阻塞IO: blocking I/O model. IO执行的两个阶段都被阻塞了。
- 非阻塞IO:non blocking I/O model. 数据准备阶段,如果数据没有准备好,那么就返回一个error给客户端,客户端再次请求。直到内核空间把数据准备好了,那么客户再次来访问的时候,进入内核将数据考入程序的内存中。
- I/O多路复用:select, poll, epoll会轮流循环socket,当某个socket有数据到达的时候,那么就会通知用户。当用户进程调用了select, 那么整个进程就会被卡住。(I/O多路复用,适用于多个socket)
其中第3种模式就是协程中的一种。Python中有select和selctors两个模块,可以实现IO多路复用。
select 是比较好理解。需要3个参数 readable, writeable,exceptional = select.select(inputs,outputs,inputs)。
import select
import socket
import queue
server = socket.socket()
server.bind((‘localhost‘,9999))
server.listen(1000)
#在接受之前,得设置为非阻塞模式
server.setblocking(False) #False是非阻塞
inputs = [server,]#用户存放socket链接的列表
outputs = []
#每一个连接都要单独有一个队列
msg_dic = {}
#注意是用户发一次数据,那么就激活了readabld,readable一激活,就会接收数据;将链接放到outputs.remove(i),就会激活writeable, writeable一激活,就会开始从存放的队列中取出数据,然后发送数据(或者不发送)
while True:
readable, writeable,exceptional = select.select(inputs,outputs,inputs)
# 第一个参数是传100个socket,要是有一个活动,那么select就会返回有活动,可读;
# 第二个参数是outputs...可写;
# 第三个参数inputs是出现异常报错,检测的还是100个socket链接
print(‘readable is‘,readable)
print(‘writeable is‘,writeable)
print(‘exceptional is‘,exceptional)
for i in readable:
if i is server: #代表来了一个新链接
conn,addr = server.accept()
print(conn,addr)
print("来了一个新链接",conn)
inputs.append(conn) #因为这个新建立的链接还没有发数据,所以如果接受,那么就会报错。所有需要实现这个客户端发数据来server时,就需要让select再检测这个链接。
# inputs = [server,conn],但是select会内部做循环,所以inputs = [conn].如果返回时server那么就代表来新连接,如果返回的是conn那么就直接接受数据。
msg_dic[conn] = queue.Queue() #初始化一个队列,后面存 要返回给这个客户端的数据
else:
try:
data = i.recv(1024) #注意,如果有两个client,那么client1连了之后,client2也连了,conn这时候其实是conn2是client2的,所以这时候client1给server传的时候就会出错。所以要用i来查看是哪个conn发的
print("收到数据",data)
#然后把要给这个连接的数据放到它的队列中, 那些链接需要返回数据的,那就先放到output中。
msg_dic[i].put(data)
outputs.append(i) #放入返回的链接队列中。注意output是在下次循环时候才会有数据outputs = [‘conn1‘,‘conn2‘]
except Exception as e:
print("{0}链接出错了{1}".format(i,e)) #如果链接断开,那么需要清理链接
if i in outputs:
outputs.remove(i) #清理已经断开的链接
inputs.remove(i)
del msg_dic[i]
for w in writeable: #要返回给客户端的列表
try:
next_msg = msg_dic[w].get_nowait()
except queue.Empty:
print("client {0} queue is empty".format(w))
outputs.remove(w) #确保下次循环的时候,writable不再返回已经处理完毕的链接
else:
print("sending message {0} to {1}".format(next_msg,w))
w.send(next_msg.upper())
for e in exceptional:#如果客户端断开,那么就把这个实例从input和output中删除
print("handling exception for",e.getpeername())
if e in outputs:
outputs.remove(e)
inputs.remove(e)
del msg_dic[e]
selectors 涉及到了回调函数,比较简洁,但是理解起来有点困难(至少我现在还是不会单独使用,每次使用之前还得看一下代码)
import selectors
import socket
sel = selectors.DefaultSelector()
def accept(sock, mask):
conn,addr = sock.accept()
print("accepted",conn,"from",addr)
conn.setblocking(False)
sel.register(conn,selectors.EVENT_READ,read) #把链接再次注册到连接中,但是调用的回调函数是read.如果客户端的数据发过来了,就调用read
def read(conn,mask):
data = conn.recv(1024)
if data:
print("echoing",repr(data),‘to‘,conn)
conn.send(data)
else:
print("closing",conn)
sel.unregister(conn)
conn.close()
sock=socket.socket()
sock.bind((‘localhost‘,9999))
sock.listen(100)
sock.setblocking(False) #设置为非阻塞模式
sel.register(sock,selectors.EVENT_READ,accept) #注册了新链接,那么就调用accept
while True:
events = sel.select()#默认是阻塞,有互动链接就返回活动的链接列表
print(‘event is‘,events)
for key,mask in events:
callback = key.data #相当于调用回调函数,
callback(key.fileobj,mask) #socket链接, fileobj = conn
第十周的作业,是基于完全理解select的基础上。由于我理解得不是很好,所以就花了很长的时间,主要是因为没有拎清楚。附上我理解的流程图,在python学习的长河中垫一块小石头。
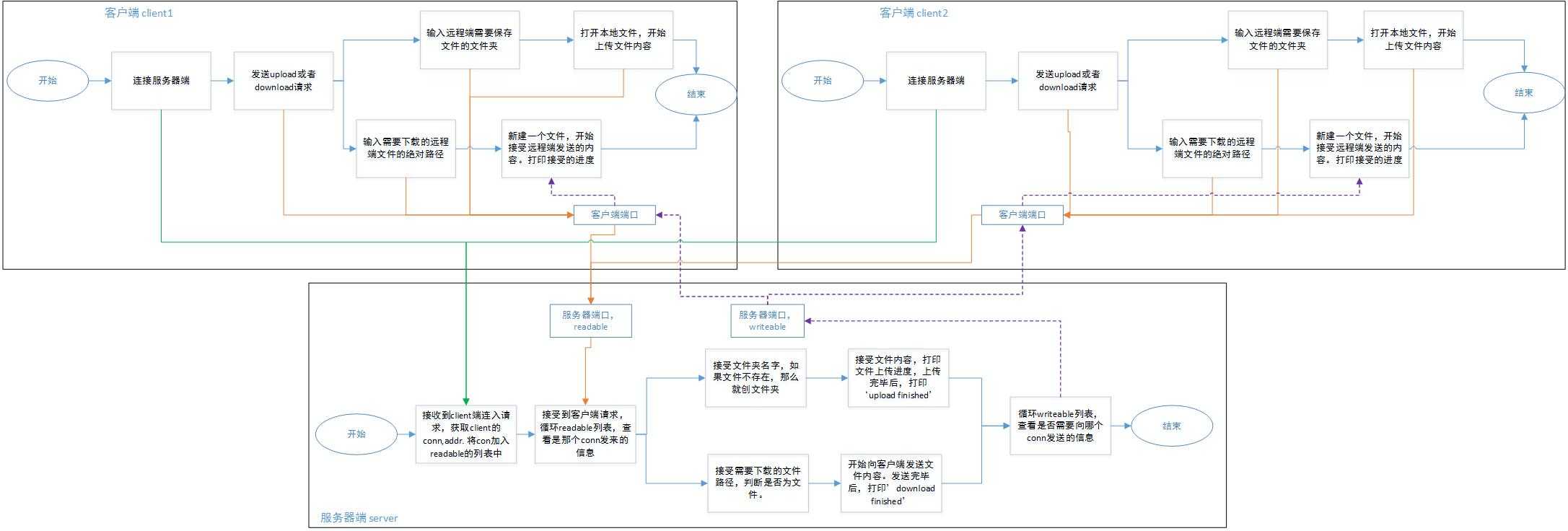
以上是关于难得二逼的协程,事件驱动和异步IO的主要内容,如果未能解决你的问题,请参考以下文章