可以将TCP BBR算法模块化到低版本内核取代锐速吗
Posted dog250
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了可以将TCP BBR算法模块化到低版本内核取代锐速吗相关的知识,希望对你有一定的参考价值。
上周的文章引发了比较火爆的争论并带来了争议,我比较满意或者遗憾,尽管如此,如果有人真的能明白在文章的背后我真正想表达的意思,我也就深感欣慰了。还像往常一样,我花周末的时间来总结技术,写点技术散文,同时我希望能在技术上引发同样的争论。在跟温州皮鞋厂老板聊天时,老板让我从非技术角度重新思考了Google的BBR算法。
很多测试似乎表明BBR的表现非常不错,虽不能保证包打天下,至少相比锐速而言,它是免费的啊,那么疑问也就随之而来了,既然BBR是免费的,且效果不错,那么那些搞单边加速的产品还有意义吗?毕竟单边加速的空间有天花板,且卖的还真不便宜。
从技术上讲,商业化的单边加速产品确实不再需要了,用BBR差不多就行了,但是单边加速产品相比BBR有一个优势,那就是不需要改动内核,基本都是模块化的,都可以online一键安装,这是BBR做不到的。
网上很多人都给出了BBR的升级方案,越做越简单,基本都将下载内核,编译内核,安装内核,启用BBR封装成了一个脚本,一键安装。但是目前还没有人能做到不改内核,仅仅用一个低版本内核的模块就能安装BBR算法,哪怕一个阉割版都没有。我是不是又想做第一人?
这个先不论。现在的问题是,难道企业用户不能升级内核到4.9+吗?温州老板分析了原因。
其实很容易理解,企业用户的OS都是依托某个发行版的,比如RH,Suse,至少也要是个Debian吧,无论是厂商的技术支持,还是足够的社区资源,企业用户都是需要的,企业用户一般不会直接折腾内核,他们没有精力或者没有能力去升级内核,另外,升级到最新版的内核意味着你要独自承担技术风险,然而企业并不缺钱,所以宁愿花钱买现成的产品,也不想自己折腾内核。
题目中说的BBR是否可以代替锐速,非技术层面的已经说过了,答案很显然,不能替代。那么从技术上来讲呢?先说答案吧,很难。我来简单说一下难点在哪,然后才可以讨论如何突破。
要想在任意版本上使用BBR,就需要将BBR在任何内核版本上模块化,以2.6.32和3.10为例,其实这两个版本对于TCP拥塞控制这个子系统而言差别并不大,但是为了支持BBR,Linux 4.9版本的内核对基础设施做了比较大的改动。主要涉及三个方面。
1.罪与罚框架的重构
这个我就不再说了,已经说的够多了。总结成一句话就是,4.9之前拥塞模块可以在cong_avoid回调中犯罪,然后在PRR中被惩罚,在4.9之后,cong_control统一接管了罪与罚。2.即时速率的测量和采集
问个问题,如何在一个TCP连接中,精确测量该连接的即时速率?要回答这个问题,先要知道什么是即时速率。如果你用wget或者curl下载一个文件,进度条后面不断变化的那个速率是即时速率吗?并不是。虽然那个速率看起来比较“即时”,但实际上只是把时间区间的一端不断推进的平均速率而已,计算方法不外乎“当前已经传输的数据大小”除以“连接开始到当前的时间”此类。那么到底什么才是即时速率呢?
即时速率的计算由ACK时钟来驱动,它也是一个分子除以分母的商,分子依然是数据量,分母依然是时间段,其中分子的定义如下:从当前ACK确认的数据发出时到现在为止一共被确认的数据量;而分母的定义则是:从当前ACK确认的数据被发出时到现在的时间差。具体的测量手段可以用下图表示,为了清晰可见,下图没有包括SACK和重传的情形,但实际上,重传的数据段和被SACK的数据段也是要包含在内的:
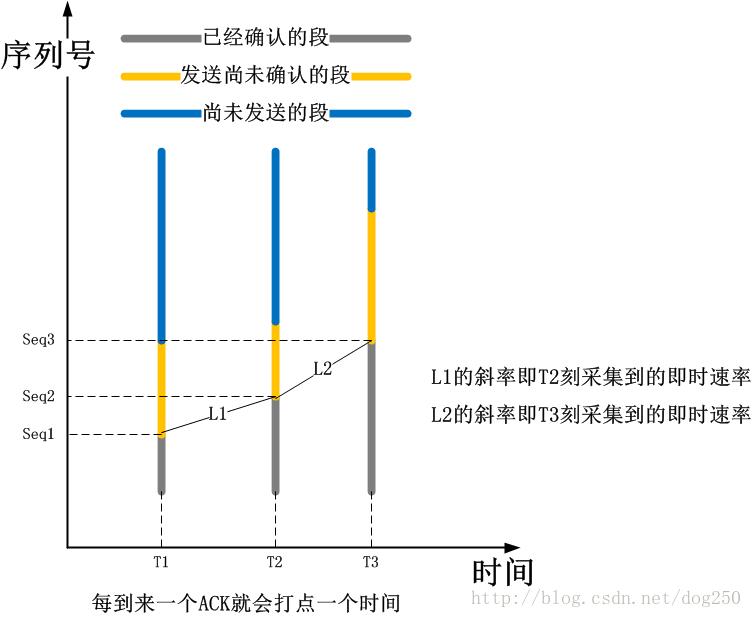
即时速率和TCP的传输速率是有区别的,举个例子来讲,1秒内成功发送10个一模一样的大小为2000字节数据包,那么TCP的传输速率就是2000B/s,而即时速率则是20000B/s,差了10倍。
也就是说,即时速率度量的是网络状态,即网络管道有多大的传输能力,而TCP传输速率则度量的是TCP协议本身的传输能力,与网络无关。
BBR计算即时速率,是把重传的数据包也算进去的,只要是发送出去的数据包,不管是新传输的,还是重传的,都会纳入计数。所以说,BBR会在发送每一个数据包的时候,在该数据包上打上当时的传输快照,等到该数据包被ACK或者SACK的时候,用当前的快照与数据包发送时的快照作差,即时速率就算出来了。因此,每收到一个ACK,都可以这么计算一下,因此这个计算出来的速率是光滑前移的,计算完全靠ACK来驱动。BBR严重依赖连接中这个即时速率序列的全量值,而不是采样值,所以说这个即时速率计算设施是非常重要的。
每收到一个ACK时,都能拿到被这个ACK确认的数据包在发出的时候是什么情形,然而在老版本的内核,以3.10为例,这是不可能做到的。之前的内核只能自己记录时间点,然后在两个时间点之间数被确认的数据包的数量,而不能仅仅靠ACK时钟流来驱动计算。这种计算方式相比平滑的BBR计算方式粒度难免太粗了,以多长的时间间隔计算合适呢?100ms?200ms?1s?对于rtt是800ms的连接来讲,100ms可能是合适的,但rtt是80ms的连接,100ms又显得太长了...这就是问题。
这个问题被我认为是移植BBR到低版本的大障碍。但我觉得既然认清了问题的根源,至少这是可以忍受的,迟到总比不来好。既然我不能修改内核为TCP增加任何基础设施,我也只能用稍微蹩脚的方式来模拟了。模拟真的好吗?
3.CA rtt与Seq rtt
既然在速率的计算上存在即时速率与TCP传输速率的差别,分别反应网络状况和TCP本身的状况,那么对于RTT是不是也有类似的差别呢?答案显然是肯定的。为了避免再次长篇大论,我先列一下3.10内核在采集RTT时采用的办法。通过tcp_clean_rtx_queue函数,很容易看到以下的逻辑:
s32 seq_rtt = -1;
s32 ca_seq_rtt = -1;
while ((skb = tcp_write_queue_head(sk)) && skb != tcp_send_head(sk)) {
struct tcp_skb_cb *scb = TCP_SKB_CB(skb);
ca_seq_rtt = now - scb->when;
if (seq_rtt < 0) {
seq_rtt = ca_seq_rtt;
}
}
if (flag & FLAG_ACKED) {
tcp_ack_update_rtt(sk, flag, seq_rtt);
ca_ops->pkts_acked(sk, pkts_acked, ca_seq_rtt);
}你会看到,有两个rtt,分别是seq_rtt和ca_seq_rtt,它们是什么呢?其实它们分别的意义就是Seq TCP和CA rtt:
CA rtt:一个ACK确认的最后一个数据段的RTT。一般表示网络上真实测的的RTT,由以下三部分组成:传输延时,排队延时,处理延时。
Seq rtt:一个ACK确认的第一个数据段的RTT。受到TCP Delay ACK的影响,因此会引入接收端的Delay延时,由以下四部分组成:传输延时,排队延时,处理延时,Delay延时。
你会发现,CA rtt主要注入给拥塞控制模块的pkts_acked回调,供拥塞算法来使用以及计算与RACK相关的定时器超时时间,,这也正合拥塞控制之本意,拥塞控制本来就是关注网络状况的,它不会关心TCP协议本身。而Seq rtt则主要用于计算RTO。
现在回到BBR向低版本移植的话题。
以3.10为例,该版本的内核仅仅将CA rtt导出给了pkts_acked回调,而我们知道BBR是自己维护内部状态,不受TCP本身的拥塞状态转换的影响,也就是说即便在Recovery状态也会无条件按照自己的内部逻辑计算即时速率,该计算过程以CA rtt作为窗口,一旦越界便会进入PROBE RTT状态,所以说CA rtt的采集是必须的,即便在一个ACK并没有推进UNA的情况下(这意味着它只是携带了SACK或者在不支持SACK的情况下仅仅是一个重复的ACK),也是需要CA rtt的。
可惜,3.10版本的内核并无次基础设施无条件采集CA rtt。如果一个ACK没有推进UNA,即没有顺序确认新数据,那么CA rtt便不会被采集。这是移植的一大难点。我们来看一下4.9版本的内核是怎么做到的,同样是上述代码逻辑,4.9版本是这么写的:
s32 seq_rtt = -1;
s32 ca_seq_rtt = -1;
while ((skb = tcp_write_queue_head(sk)) && skb != tcp_send_head(sk)) {
struct tcp_skb_cb *scb = TCP_SKB_CB(skb);
ca_seq_rtt = now - scb->when;
if (seq_rtt < 0) {
seq_rtt = ca_seq_rtt;
}
}
// 我修改了命名,但无伤本质。
if (likely(first_ackt.v64) && !(flag & FLAG_RETRANS_DATA_ACKED)) {
seq_rtt = skb_mstamp_us_delta(now, &first_ackt);
ca_rtt = skb_mstamp_us_delta(now, &last_ackt);
}
// 即便在只有SACK的情况下,也会更新CA rtt
if (sack->first_sackt.v64) {
sack_rtt = skb_mstamp_us_delta(now, &sack->first_sackt);
ca_rtt = skb_mstamp_us_delta(now, &sack->last_sackt);
}
// CA rtt导出给调用者,进而注入拥塞控制模块
sack->rate->rtt_us = ca_rtt; /* RTT of last (S)ACKed packet, or -1 */
// 即便是没有推进UNA,也会用seq_rtt作为测量的Seq rtt样本进行移动指数平均。
// 这就是说,即使在Recovery等“异常”状态,Seq rtt(就是传统意义上的rtt)也是会被更新的。
rtt_update = tcp_ack_update_rtt(sk, flag, seq_rtt, sack_rtt, ca_rtt);
if (flag & FLAG_ACKED) {
ca_ops->pkts_acked(sk, pkts_acked, ca_seq_rtt);
}由于以上3点涉及到针对TCP拥塞控制基础设施比较大的重构和改进,所以说移植BBR算法到低版本是一件几乎不可能的事情,各CDN厂商又没有足够的动力(其实是因为拥有太多的阻力)去更新自己的内核到最新的4.9,4.10,所以说短时间内,BBR无法大规模用于国内CDN。
当然,很多人声称自己已经在公网以及数据中心间测试了BBR,但这实属小众群体。要么你是自己玩,这种情况怎么折腾都行,要么就是你有足够的自由度定制自己产品的内核版本,这也无话可说。试想大多数使用系统厂商提供的RH企业版的用户,怎么可能随意更新自己的内核并继续获得厂商的技术支持呢?以RH为例,它自身就有成百上千个Patch,即便你更新了内核到4.9,那你至少必须将这成百上千个Patch也一并打上,然而这几乎是不可能的,RH公司不会为你做针对4.9内核的对应Patch。
那该怎么办?如果非要移植,又不能改内核,那该怎么办?温州老板说可以使用Netfiter,我说太麻烦,工作量也不小。或者说使用jprobe机制钩住tcp_v4_rcv,然后在其pre handler中接管整个处理逻辑,将其换成4.9内核的逻辑,涉及到数据结构的修改就需要自己malloc,在pre handler处理完毕之前,将skb的pkt_type改成PACKET_OTHERHOST,这样就可以保证在jprobe_return之后进入原始tcp_v4_rcv后,在第一时间返回,从而做到完全接管TCP收包处理逻辑。
看似不错的选择,但却不能大规模使用,我一直觉得这只是一种Hack手段...
另外,我认为,千万不要移植一个实现了“一半”的BBR算法。比如你会说,既然无法测量即时速率,那就自己设置timer自己测量平均速率来模拟,既然无法采到CA rtt,那就是用Seq rtt来近似...我之前也是这么打算的,但是后来就认输了,千万不要这样,因为BBR之所以可行,完全就是依赖与其精准的测量。
依赖于精准的测量
曾经的Reno时代,TCP依靠数学模型来收敛到平衡,现在BBR依靠精准的测量来收敛到平衡,孰好孰坏?来做一个类比,这两者的差别不会大于推导出的模型与数据训练出的模型之间的差异。一个典型的例子就是吴军在《 智能时代》里关于人工智能的阐述。在上世纪50,60年代,人们普遍相信可以通过“算法”来让计算机获得智能。然后在经历了持续的失败后,人们把目光集中在数据上。
既然已经有了足够多的全量数据-而不是采样数据,既然这些数据都是实实在在真实的,那么这些数据表现出的模式一定就是真实的,问题是如何提炼出这些模式。在这个大数据的背景下,一开始没有什么公式,也没有什么算法,有的只有数据,前提是数据必须是真实的。
那么如果数据是不真实的,会怎样?后果会很严重,会把计算引入歧途,最终的模型也会与真实的情况大相径庭。
BBR如今也不再依赖既有的“数学公式”,比如它不是从一个AIMD控制论模型开始的,而是完全基于一系列的精确测量,测量即时带宽,测量CA rtt,测量Seq rtt...然后根据一个非常简单的网络管道模型,基于“最大实测带宽”与“最小实测CA rtt”来计算“不排队时”的速率和BDP,这个过程本身就是收敛的,关键点在于“不排队”,只要不主动占用队列,连接就不会崩溃,所有的连接就能公平共享带宽,这正是TCP收敛的重要目标。
所以说,对于想优化BRR的来讲,不要随意去修改那些参数值。你会发现,稍微修改一点,结果就会谬之千里。
结论:
不修改内核,在低版本内核模块化BBR算法没有意义。PS:这本《智能时代》已经寄到了上海送给了温州皮鞋厂老板。我大致评价几句,这本书前面的部分写的比较精彩,后面就越来越拖沓冗余了。
补遗:
胡老师(blog:http://blog.csdn.net/hu_zhenghui):-)看了本文后,觉得有些地方不妥,比较有道理,本来想直接改正文的,后来觉得这样可能湮没我们这次简单交流的思路,所以就单独写一个小节了。
在文中,我提到企业级用户,然而如今企业级系统的瓶颈极少会出现在TCP这个环节,优化网络的往往都是互联网公司。也就是说,企业级系统并非本文描述的TCP单边加速的显著应用场景。
企业系统优化包含多方面的内容,直接瓶颈往往不在网络。那么CDN服务呢?只能说之前的瓶颈在网络,但是随着基础设施的完善,目前对CDN服务要求ACL较多,ACL的瓶颈比较明显。
其实我觉得“随着基础设施的完善”的意思是说,各CDN服务提供商要相信底层提供的基础设施,把军备竞赛的精力更多的放在调度,回源优化,路由(指的是应用层的概念,非IP路由)等方面,直接修改基础设施的收益将会非常有限。另外,对于互联网企业,所有的机器,OS,协议栈全部都是自己的,那么优化基础设施就显得比较重要了。对于TCP而言,这里还有一个单边还是双边的问题,之前跟华为的人交流,华为这种公司认为单边加速的收益非常有限,真正的红利在双边优化,然而能像华为这样做的了协议栈层级双边优化的公司(其端,管,云战略)又有几家呢?
不过对于非协议栈层面的双边优化,有客户端或者浏览器的公司都可以做到,比如Google,BAT等公司都可以。以腾讯的QQ浏览器为例,如果你访问非腾讯的资源,那么它就是一个普通的浏览器,但是如果你访问腾讯的资源,那么是不是可以封装成UDT流进行交互呢?当然,我不知道QQ浏览器的细节,但这几乎是一个很常规的思路。
以上是关于可以将TCP BBR算法模块化到低版本内核取代锐速吗的主要内容,如果未能解决你的问题,请参考以下文章