中文分词的常见项目
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了中文分词的常见项目相关的知识,希望对你有一定的参考价值。
参考技术A 功能性能 功能描述:1.新词自动识别
对词典中不存在的词,可以自动识别,对词典的依赖较小;
2.词性输出
分词结果中带有丰富的词性;
3.动态词性输出
分词结果中的词性并非固定,会根据不同的语境,赋予不同的词性;
4.特殊词识别
比如化学、药品等行业词汇,地名、品牌、媒体名等;
5.智能歧义解决
根据内部规则,智能解决常见分词歧义问题;
6.多种编码识别
自动识别各种单一编码,并支持混合编码;
7.数词量词优化
自动识别数量词; 性能介绍:处理器:AMD Athlon II x2 250 3GHZ
单线程大于833KB/s,多线程安全。 一个php函数实现中文分词。使分词更容易,使用如下图:
Paoding(庖丁解牛分词)基于Java的开源中文分词组件,提供lucene和solr 接口,具有极 高效率和 高扩展性。引入隐喻,采用完全的面向对象设计,构思先进。
高效率:在PIII 1G内存个人机器上,1秒可准确分词 100万汉字。
采用基于 不限制个数的词典文件对文章进行有效切分,使能够将对词汇分类定义。
能够对未知的词汇进行合理解析。
仅支持Java语言。 MMSEG4J基于Java的开源中文分词组件,提供lucene和solr 接口:
1.mmseg4j 用 Chih-Hao Tsai 的 MMSeg 算法实现的中文分词器,并实现 lucene 的 analyzer 和 solr 的TokenizerFactory 以方便在Lucene和Solr中使用。
2.MMSeg 算法有两种分词方法:Simple和Complex,都是基于正向最大匹配。Complex 加了四个规则过虑。官方说:词语的正确识别率达到了 98.41%。mmseg4j 已经实现了这两种分词算法。 盘古分词是一个基于.net 平台的开源中文分词组件,提供lucene(.net 版本) 和HubbleDotNet的接口
高效:Core Duo 1.8 GHz 下单线程 分词速度为 390K 字符每秒
准确:盘古分词采用字典和统计结合的分词算法,分词准确率较高。
功能:盘古分词提供中文人名识别,简繁混合分词,多元分词,英文词根化,强制一元分词,词频优先分词,停用词过滤,英文专名提取等一系列功能。 jcseg是使用Java开发的一个中文分词器,使用流行的mmseg算法实现。
1。mmseg四种过滤算法,分词准确率达到了98.4%以上。
2。支持自定义词库。在lexicon文件夹下,可以随便添加/删除/更改词库和词库内容,并且对词库进行了分类,词库整合了《现代汉语词典》和cc-cedict辞典。
3。词条拼音和同义词支持,jcseg为所有词条标注了拼音,并且词条可以添加同义词集合,jcseg会自动将拼音和同义词加入到分词结果中。
4。中文数字和分数识别,例如:"四五十个人都来了,三十分之一。"中的"四五十"和"三十分之一",并且jcseg会自动将其转换为对应的阿拉伯数字。
5。支持中英混合词的识别。例如:B超,x射线。
6。支持基本单字单位的识别,例如2012年。
7。良好的英文支持,自动识别电子邮件,网址,分数,小数,百分数……。
8。智能圆角半角转换处理。
9。特殊字母识别:例如:Ⅰ,Ⅱ
10。特殊数字识别:例如:①,⑩
11。配对标点内容提取:例如:最好的Java书《java编程思想》,‘畅想杯黑客技术大赛’,被《,‘,“,『标点标记的内容。
12。智能中文人名识别。中文人名识别正确率达94%以上。
jcseg佩带了jcseg.properties配置文档,使用文本编辑器就可以自主的编辑其选项,配置适合不同应用场合的分词应用。例如:最大匹配分词数,是否开启中文人名识别,是否载入词条拼音,是否载入词条同义词……。 friso是使用c语言开发的一个中文分词器,使用流行的mmseg算法实现。完全基于模块化设计和实现,可以很方便的植入到其他程序中,例如:mysql,PHP等。并且提供了一个php中文分词扩展robbe。
1。只支持UTF-8编码。【源码无需修改就能在各种平台下编译使用,加载完20万的词条,内存占用稳定为14M。】。
2。mmseg四种过滤算法,分词准确率达到了98.41%。
3。支持自定义词库。在dict文件夹下,可以随便添加/删除/更改词库和词库词条,并且对词库进行了分类。
4。词库使用了friso的Java版本jcseg的简化词库。
5。支持中英混合词的识别。例如:c语言,IC卡。
7。很好的英文支持,电子邮件,网址,小数,分数,百分数。
8。支持阿拉伯数字基本单字单位的识别,例如2012年,5吨,120斤。
9。自动英文圆角/半角,大写/小写转换。
并且具有很高的分词速度:简单模式:3.7M/秒,复杂模式:1.8M/秒。

项目应用自然语言处理-python实现jieba中文分词
自然语言处理-python实现中文分词


jieba分词器介绍

自然语言处理中,英文中,词与词之间有空格进行分割,但是中文中的词需要进行分析,切分操作。
jieba分词器支持三种分词模式:
1.精确模式,试图将句子最精确地切开,适合文本分析;
2.全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
3.搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
支持繁体分词
下面使用jieba官方的demo例子做简单的应用。

输出后的3中模式的效果
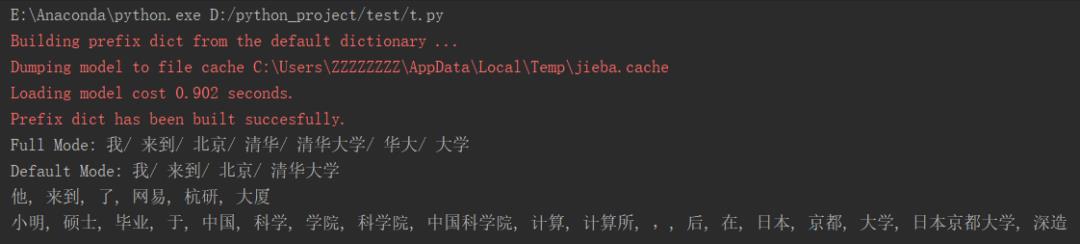
jieba自定义词典
jieba自己已经有词典,但是你还可以自己向词典中增加。比如一些人名、地名、机构名,词典中未收录,为了避免分词分错,可以自行增加。
1.构造txt文档增加词
自己写一个txt文档,然后通过调用txt文档使用新加入的词,txt文档书写时,词典的格式和jieba分词器本身的分词器中的词典格式必须保持一致,一个词占一行,每一行分成三部分,一部分为词语,一部分为词频,最后为词性(可以省略),用空格隔开。
2.程序中动态修改词典
调用jieba的函数add_word(word, freq=None, tag=None) 和 del_word(word) 可以在词典中增加删除单词。
下面时使用增加新词和未增加新词的对比分词结果输出。
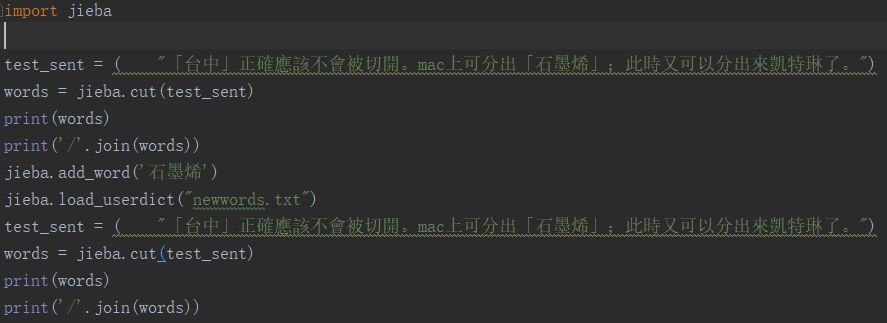
输出结果如下,可以看到石墨烯 本来被分成两个词,经过添加后,正确的划分为了1个词。

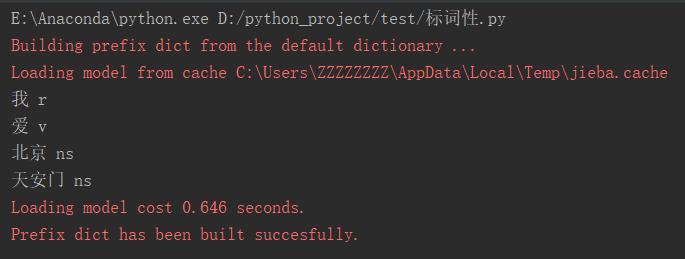
jieba分词后标注词性
接着上例,分好的词,我们继续对词进行标注词性。
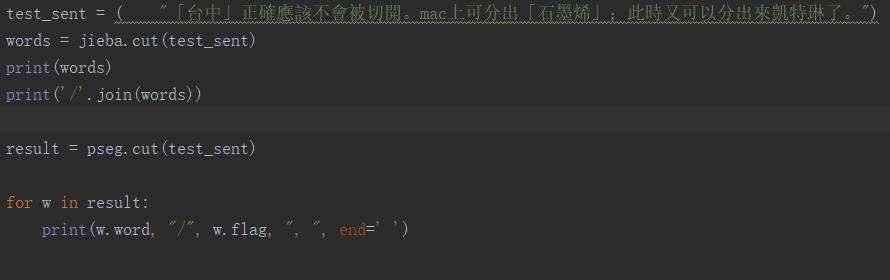
输出结果:

词性标注
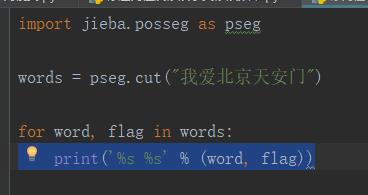
输出结果:
jieba更改原有的词频统计
因为,前面我们自定义了加减了词典,所有会出现原有jieba默认的词频会受影响发生改变,有两种情况。
1.本该分,但系统没分的例子。
加入自定义的该分词后,原来词频 会减少。
例子如下:
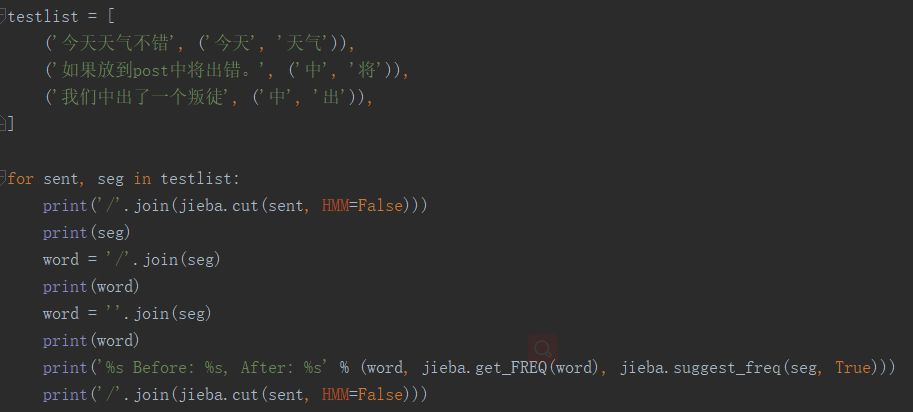
输出结果
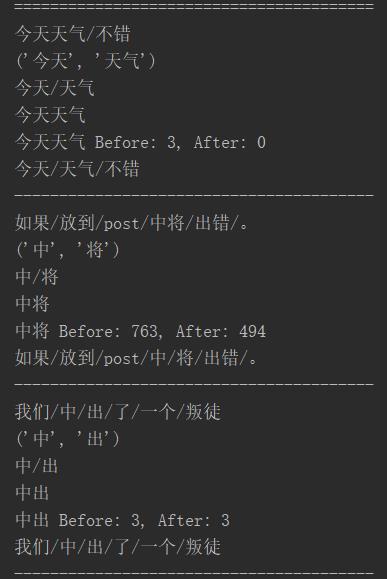
相反的,另一种情况。
2.本不该分,但系统分了的例子。
加入自定义的该合并的词后,原来词频 会增加(生成)。
例子如下:

输出结果:

更多精彩内容,尽在阅读原文
以上是关于中文分词的常见项目的主要内容,如果未能解决你的问题,请参考以下文章