spark集群--elasticsearch
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark集群--elasticsearch相关的知识,希望对你有一定的参考价值。
- spark集群搭建
- elasticsearch读写数据
====================================================
- spark集群搭建
- spark官网:http://spark.apache.org
- 各个版本:spark-2.1.0, java 1.8.0_121以及elasticsearch-5.2.0
- 本集群利用的是spark的独立集群管理器
- 准备N台服务器(1台主节点,n-1台工作节点)
- 分别将N台机器装上java 1.8.0_121以及将spark-2.1.0-bin-hadoop2.7.tgz解压到相同目录下
- 设置好从主节点机器到其他机器的SSH无密码登录(本事例采用的dsa)
- 编辑主节点的 SPARK_HOME/config/slavers文件并填上所有工作节点的ip(1.此处可随个人爱好填写主机名。2.多工作节点用空格分割)
- 在主节点上启动集群 SPARK_HOME/sbin/start-all.sh
- 访问 http://主节点:8080 来查看集群状态
- 提交应用 SPARK_HOME/bin/spark-submit --master spark://XXX:7077 yourapp
- 访问 http://主节点:8080 来查看您的应用是否正常运行(1.Running Applications 有你的appname。2.列出了所使用的核心和内存均大于0)
- 事例如下
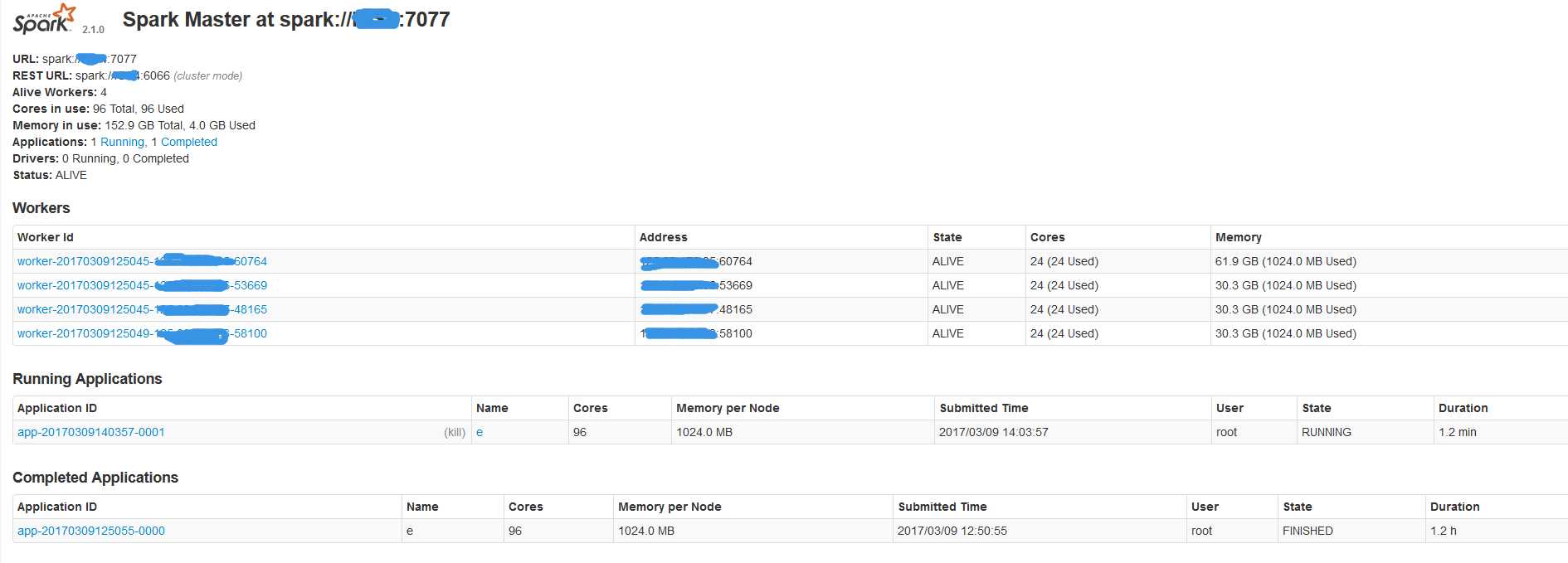
- 备注:不知道什么原因,集群的时候 需要在SPARK_HOME/conf/spark-env.sh 再次设置下JAVA_HOME,工作节点读取不到JAVA_HOME的环境变量
- elasticsearch读写数据
- 引用的jar包
-
<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.10</artifactId> <version>2.1.0</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive_2.10</artifactId> <version>2.1.0</version> </dependency> <dependency> <groupId>org.elasticsearch</groupId> <artifactId>elasticsearch-spark-20_2.11</artifactId> <version>5.1.2</version> </dependency>
- 读取数据
-
SparkConf conf = new SparkConf().setAppName("e").setMaster("spark://主节点:7077");
conf.set("es.nodes", "elasticsearchIP");
conf.set("es.port", "9200");
JavaSparkContext jsc = new JavaSparkContext(conf); JavaRDD<Map<String, Object>> esRDD = JavaEsSpark.esRDD(jsc, "logstash-spark_test/spark_test", "?q=selpwd").values(); - 写数据
-
JavaEsSpark.saveToEs(inJPRDD.values(), "logstash-spark_test/spark_test");
以上是关于spark集群--elasticsearch的主要内容,如果未能解决你的问题,请参考以下文章
org.elasticsearch.spark.rdd.api.java.javaesspark哪个包
Spark 与 Elasticsearch交互的一些配置和问题解决