Zookeeper原理和应用
Posted 一笑之奈何
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Zookeeper原理和应用相关的知识,希望对你有一定的参考价值。
ZooKeeper基本原理
数据模型
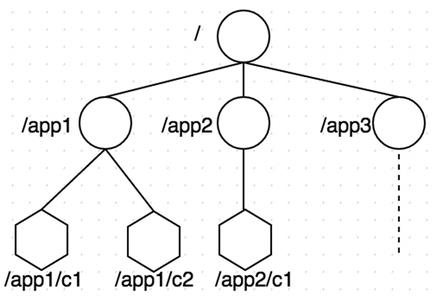
如上图所示,ZooKeeper数据模型的结构与Unix文件系统很类似,整体上可以看作是一棵树,每个节点称做一个ZNode。每个ZNode都可以通过其路径唯一标识,比如上图中第三层的第一个ZNode, 它的路径是/app1/c1。在每个ZNode上可存储少量数据(默认是1M, 可以通过配置修改, 通常不建议在ZNode上存储大量的数据),这个特性非常有用,在后面的典型应用场景中会介绍到。另外,每个ZNode上还存储了其Acl信息,这里需要注意,虽说ZNode的树形结构跟Unix文件系统很类似,但是其Acl与Unix文件系统是完全不同的,每个ZNode的Acl的独立的,子结点不会继承父结点的。
重要概念
ZNode
前文已介绍了ZNode, ZNode根据其本身的特性,可以分为下面两类:
Regular ZNode: 常规型ZNode, 用户需要显式的创建、删除
Ephemeral ZNode: 临时型ZNode, 用户创建它之后,可以显式的删除,也可以在创建它的Session结束后,由ZooKeeper Server自动删除
ZNode还有一个Sequential的特性,如果创建的时候指定的话,该ZNode的名字后面会自动Append一个不断增加的SequenceNo。
Session
Client与ZooKeeper之间的通信,需要创建一个Session,这个Session会有一个超时时间。因为ZooKeeper集群会把Client的Session信息持久化,所以在Session没超时之前,Client与ZooKeeper Server的连接可以在各个ZooKeeper Server之间透明地移动。
在实际的应用中,如果Client与Server之间的通信足够频繁,Session的维护就不需要其它额外的消息了。否则,ZooKeeper Client会每t/3 ms发一次心跳给Server,如果Client 2t/3 ms没收到来自Server的心跳回应,就会换到一个新的ZooKeeper Server上。这里t是用户配置的Session的超时时间。
Watcher
ZooKeeper支持一种Watch操作,Client可以在某个ZNode上设置一个Watcher,来Watch该ZNode上的变化。如果该ZNode上有相应的变化,就会触发这个Watcher,把相应的事件通知给设置Watcher的Client。需要注意的是,ZooKeeper中的Watcher是一次性的,即触发一次就会被取消,如果想继续Watch的话,需要客户端重新设置Watcher。这个跟epoll里的oneshot模式有点类似。
ZooKeeper特性
读、写(更新)模式
在ZooKeeper集群中,读可以从任意一个ZooKeeper Server读,这一点是保证ZooKeeper比较好的读性能的关键;写的请求会先Forwarder到Leader,然后由Leader来通过ZooKeeper中的原子广播协议,将请求广播给所有的Follower,Leader收到一半以上的写成功的Ack后,就认为该写成功了,就会将该写进行持久化,并告诉客户端写成功了。
WAL和Snapshot
和大多数分布式系统一样,ZooKeeper也有WAL(Write-Ahead-Log),对于每一个更新操作,ZooKeeper都会先写WAL, 然后再对内存中的数据做更新,然后向Client通知更新结果。另外,ZooKeeper还会定期将内存中的目录树进行Snapshot,落地到磁盘上,这个跟HDFS中的FSImage是比较类似的。这么做的主要目的,一当然是数据的持久化,二是加快重启之后的恢复速度,如果全部通过Replay WAL的形式恢复的话,会比较慢。
FIFO
对于每一个ZooKeeper客户端而言,所有的操作都是遵循FIFO顺序的,这一特性是由下面两个基本特性来保证的:一是ZooKeeper Client与Server之间的网络通信是基于TCP,TCP保证了Client/Server之间传输包的顺序;二是ZooKeeper Server执行客户端请求也是严格按照FIFO顺序的。
Linearizability
在ZooKeeper中,所有的更新操作都有严格的偏序关系,更新操作都是串行执行的,这一点是保证ZooKeeper功能正确性的关键。
ZooKeeper Client API
原生API
ZooKeeper Client Library提供了丰富直观的API供用户程序使用,下面是一些常用的API:
create(path, data, flags): 创建一个ZNode, path是其路径,data是要存储在该ZNode上的数据,flags常用的有: PERSISTEN, PERSISTENT_SEQUENTAIL, EPHEMERAL, EPHEMERAL_SEQUENTAIL
delete(path, version): 删除一个ZNode,可以通过version删除指定的版本, 如果version是-1的话,表示删除所有的版本
exists(path, watch): 判断指定ZNode是否存在,并设置是否Watch这个ZNode。
getData(path, watch): 读取指定ZNode上的数据,并设置是否watch这个ZNode
setData(path, watch): 更新指定ZNode的数据,并设置是否Watch这个ZNode
getChildren(path, watch): 获取指定ZNode的所有子ZNode的名字,并设置是否Watch这个ZNode
sync(path): 把所有在sync之前的更新操作都进行同步,达到每个请求都在半数以上的ZooKeeper Server上生效。
setAcl(path, acl): 设置指定ZNode的Acl信息
getAcl(path): 获取指定ZNode的Acl信息
Curator(推荐)
Curator是Netflix公司开源的一个Zookeeper客户端,与Zookeeper提供的原生客户端相比,Curator的抽象层次更高,简化了Zookeeper客户端的开发量。
Curator的Maven依赖如下,一般直接使用curator-recipes就行了,如果需要自己封装一些底层些的功能的话,例如增加连接管理重试机制等,则可以引入curator-framework包。
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>2.7.1</version>
</dependency>
利用Curator提供的客户端API,可以完全实现上面原生客户端的功能。值得注意的是,Curator采用流式风格API
监听器
Curator提供了三种Watcher(Cache)来监听结点的变化:
Path Cache:监视一个路径下1)孩子结点的创建、2)删除,3)以及结点数据的更新。产生的事件会传递给注册的PathChildrenCacheListener。
Node Cache:监视一个结点的创建、更新、删除,并将结点的数据缓存在本地。
Tree Cache:Path Cache和Node Cache的“合体”,监视路径下的创建、更新、删除事件,并缓存路径下所有孩子结点的数据。
Curator有它独特的“菜谱”:
锁:包括共享锁、共享可重入锁、读写锁等。
选举:Leader选举算法。
Barrier:阻止分布式计算直至某个条件被满足的“栅栏”,可以看做JDK Concurrent包中Barrier的分布式实现。
缓存:前面提到过的三种Cache及监听机制。
持久化结点:连接或Session终止后仍然在Zookeeper中存在的结点。
队列:分布式队列、分布式优先级队列等。
ZooKeeper典型应用场景
1. 名字服务(NameService)
分布式应用中,通常需要一套完备的命令机制,既能产生唯一的标识,又方便人识别和记忆。 我们知道,每个ZNode都可以由其路径唯一标识,路径本身也比较简洁直观,另外ZNode上还可以存储少量数据,这些都是实现统一的NameService的基础。下面以在HDFS中实现NameService为例,来说明实现NameService的基本布骤:
目标:通过简单的名字来访问指定的HDFS机群
定义命名规则:这里要做到简洁易记忆。下面是一种可选的方案: [serviceScheme://][zkCluster]-[clusterName],比如hdfs://lgprc-example/表示基于lgprc ZooKeeper集群的用来做example的HDFS集群
配置DNS映射: 将zkCluster的标识lgprc通过DNS解析到对应的ZooKeeper集群的地址
创建ZNode: 在对应的ZooKeeper上创建/NameService/hdfs/lgprc-example结点,将HDFS的配置文件存储于该结点下
用户程序要访问hdfs://lgprc-example/的HDFS集群,首先通过DNS找到lgprc的ZooKeeper机群的地址,然后在ZooKeeper的/NameService/hdfs/lgprc-example结点中读取到HDFS的配置,进而根据得到的配置,得到HDFS的实际访问入口
2. 配置管理(Configuration Management)
在分布式系统中,常会遇到这样的场景: 某个Job的很多个实例在运行,它们在运行时大多数配置项是相同的,如果想要统一改某个配置,一个个实例去改,是比较低效,也是比较容易出错的方式。通过ZooKeeper可以很好的解决这样的问题,下面的基本的步骤:
将公共的配置内容放到ZooKeeper中某个ZNode上,比如/service/common-conf
所有的实例在启动时都会传入ZooKeeper集群的入口地址,并且在运行过程中Watch /service/common-conf这个ZNode
如果集群管理员修改了了common-conf,所有的实例都会被通知到,根据收到的通知更新自己的配置,并继续Watch /service/common-conf
3. 组员管理(Group Membership)
在典型的Master-Slave结构的分布式系统中,Master需要作为“总管”来管理所有的Slave, 当有Slave加入,或者有Slave宕机,Master都需要感知到这个事情,然后作出对应的调整,以便不影响整个集群对外提供服务。以HBase为例,HMaster管理了所有的RegionServer,当有新的RegionServer加入的时候,HMaster需要分配一些Region到该RegionServer上去,让其提供服务;当有RegionServer宕机时,HMaster需要将该RegionServer之前服务的Region都重新分配到当前正在提供服务的其它RegionServer上,以便不影响客户端的正常访问。下面是这种场景下使用ZooKeeper的基本步骤:
Master在ZooKeeper上创建/service/slaves结点,并设置对该结点的Watcher
每个Slave在启动成功后,创建唯一标识自己的临时性(Ephemeral)结点/service/slaves/${slave_id},并将自己地址(ip/port)等相关信息写入该结点
Master收到有新子结点加入的通知后,做相应的处理
如果有Slave宕机,由于它所对应的结点是临时性结点,在它的Session超时后,ZooKeeper会自动删除该结点
Master收到有子结点消失的通知,做相应的处理
4. 简单互斥锁(Simple Lock)
在传统的应用程序中,线程、进程的同步,都可以通过操作系统提供的机制来完成。但是在分布式系统中,多个进程之间的同步,就需要像ZooKeeper这样的分布式的协调(Coordination)服务来协助完成同步。
多个进程尝试去在指定的目录下去创建一个临时性(Ephemeral)结点 /locks/my_lock
ZooKeeper能保证,只会有一个进程成功创建该结点,创建结点成功的进程就是抢到锁的进程,假设该进程为A
其它进程都对/locks/my_lock进行Watch
当A进程不再需要锁,可以显式删除/locks/my_lock释放锁;或者是A进程宕机后Session超时,ZooKeeper系统自动删除/locks/my_lock结点释放锁。此时,其它进程就会收到ZooKeeper的通知,并尝试去创建/locks/my_lock抢锁,如此循环反复
5. 互斥锁(Simple Lock without Herd Effect)
上一节的例子中有一个问题,每次抢锁都会有大量的进程去竞争,会造成羊群效应(Herd Effect),为了解决这个问题,我们可以通过下面的步骤来改进上述过程:
每个进程都在ZooKeeper上创建一个临时的顺序结点(Ephemeral Sequential) /locks/lock_${seq}
${seq}最小的为当前的持锁者(${seq}是ZooKeeper生成的Sequenctial Number)
其它进程都对只watch比它次小的进程对应的结点,比如2 watch 1, 3 watch 2, 以此类推
当前持锁者释放锁后,比它次大的进程就会收到ZooKeeper的通知,它成为新的持锁者,如此循环反复
这里需要补充一点,通常在分布式系统中用ZooKeeper来做Leader Election(选主)就是通过上面的机制来实现的,这里的持锁者就是当前的“主”。
6. 读写锁(Read/Write Lock)
我们知道,读写锁跟互斥锁相比不同的地方是,它分成了读和写两种模式,多个读可以并发执行,但写和读、写都互斥,不能同时执行行。利用ZooKeeper,在上面的基础上,稍做修改也可以实现传统的读写锁的语义,下面是基本的步骤:
每个进程都在ZooKeeper上创建一个临时的顺序结点(Ephemeral Sequential) /locks/lock_${seq}
${seq}最小的一个或多个结点为当前的持锁者,多个是因为多个读可以并发
需要写锁的进程,Watch比它次小的进程对应的结点
需要读锁的进程,Watch比它小的最后一个写进程对应的结点
当前结点释放锁后,所有Watch该结点的进程都会被通知到,他们成为新的持锁者,如此循环反复
7. 屏障(Barrier)
在分布式系统中,屏障是这样一种语义: 客户端需要等待多个进程完成各自的任务,然后才能继续往前进行下一步。下用是用ZooKeeper来实现屏障的基本步骤:
Client在ZooKeeper上创建屏障结点/barrier/my_barrier,并启动执行各个任务的进程
Client通过exist()来Watch /barrier/my_barrier结点
每个任务进程在完成任务后,去检查是否达到指定的条件,如果没达到就啥也不做,如果达到了就把/barrier/my_barrier结点删除
Client收到/barrier/my_barrier被删除的通知,屏障消失,继续下一步任务
8. 双屏障(Double Barrier)
双屏障是这样一种语义: 它可以用来同步一个任务的开始和结束,当有足够多的进程进入屏障后,才开始执行任务;当所有的进程都执行完各自的任务后,屏障才撤销。下面是用ZooKeeper来实现双屏障的基本步骤:
进入屏障:
Client Watch /barrier/ready结点, 通过判断该结点是否存在来决定是否启动任务
每个任务进程进入屏障时创建一个临时结点/barrier/process/${process_id},然后检查进入屏障的结点数是否达到指定的值,如果达到了指定的值,就创建一个/barrier/ready结点,否则继续等待
Client收到/barrier/ready创建的通知,就启动任务执行过程
离开屏障:
Client Watch /barrier/process,如果其没有子结点,就可以认为任务执行结束,可以离开屏障
每个任务进程执行任务结束后,都需要删除自己对应的结点/barrier/process/${process_id}
9. 分布式队列
队列方面,简单地讲有两种,一种是常规的先进先出队列,另一种是要等到队列成员聚齐之后的才统一按序执行。对于第一种先进先出队列,和分布式锁服务中的控制时序场景基本原理一致,这里不再赘述。
第二种队列其实是在FIFO队列的基础上作了一个增强。通常可以在 /queue 这个znode下预先建立一个/queue/num 节点,并且赋值为n(或者直接给/queue赋值n),表示队列大小,之后每次有队列成员加入后,就判断下是否已经到达队列大小,决定是否可以开始执行了。这种用法的典型场景是,分布式环境中,一个大任务Task A,需要在很多子任务完成(或条件就绪)情况下才能进行。这个时候,凡是其中一个子任务完成(就绪),那么就去 /taskList 下建立自己的临时时序节点(CreateMode.EPHEMERAL_SEQUENTIAL),当 /taskList 发现自己下面的子节点满足指定个数,就可以进行下一步按序进行处理了。
以上是关于Zookeeper原理和应用的主要内容,如果未能解决你的问题,请参考以下文章