使用Compute Shader加速Irradiance Environment Map的计算
Posted viX0026
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用Compute Shader加速Irradiance Environment Map的计算相关的知识,希望对你有一定的参考价值。
- Irradiance Environment Map基本原理
Irradiance Environment Map(也叫Irradiance Map或Diffuse Environment Map),属于Image Based Lighting技术中的一种。
Irradiance Map的详细定义可参考GPU Gems 2 Chapter 10.“Real-Time Computation of Dynamic Irradiance Environment Maps”。简单说来就是一种用于近似Environment Diffuse Lighting的方法。想象一个场景中有k个方向光,方向分别为d1…dk,光照强度为i1…ik,对于一个法线和Diffuse Color分别为n和c的Lambert表面,其光照强度为:
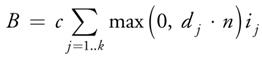
对于Environment Lighting,我们可以用一个Cube Map来表示,Cube Map里的每一个texel就是一个方向光,光强度为texel的值,方向为texel的location。这样就能通过一个Cube Map来表示任意的Environment Lighting。一般把这个Cube Map叫做Light Probe。
对于Lambert表面,其光照强度只和法线n和光照方向l相关,所以给定一个Light Probe,可以计算出所有可能的法线方向的光照,然后存储到一个Cube Map里,渲染时,只需要使用法线n去这个Cube Map里索引就能得到Environment Lighting,这个存储着光照的Cube Map就叫Irradiance Map。计算的伪代码如下:
diffuseConvolution(outputEnvironmentMap, inputEnvironmentMap) { for_all {T0: outputEnvironmentMap} sum = 0 N = envMap_direction(T0)
for_all {T1: inputEnvironmentMap} L = envMap_direction(T1) I = inputEnvironmentMap[T1] sum += max(0, dot(L, N)) * I
T0 = sum return outputEnvironmentMap }
对于每一个法线n都需要去遍历所有的光线方向,算法复杂度为O(NM),N为Light Probe的大小,M为Irradiance Map的大小。
- Spherical Harmonics
由于Diffuse光照本身是变化很缓慢的低频数据,所以可以使用SH来加速计算。把算法分为两步:
1. 把Light Probe投影到SH上,求解出SH系数存储下来。
2. 将Light Probe的SH和Diffuse Transfer的SH做卷积即可求出Irradiance Map。
具体做法如下:
//将LightProbe投影到SH上 for each texel of the lightProbe { lightSample = texelRadiance; weight += texelSolidAngle; //计算光照方向 l = texelDirection; //根据光照方向求出SH基函数 SHBasis = calculateSHBasis(l); //累加SH系数 lightSH += lightSample*SHBasis*texelSolidAngle; } lightSH = lightSH*4*PI/weight; for each texel of the irradianceMap { //法线方向 n = texelDirection; // 求出cosine lobe的SH diffuseSH = calculateDiffuseSH(n); // 用cosine lobe的SH和light probe的SH做卷积 irradiance = dotSH(diffuseSH, lightSH); // lambert brdf irradiance *= 1/PI; texelValue = irradiance; }
使用SH来计算的话,Light Probe和Irradiance Map只需要分别遍历一遍,所以算法复杂度为O(KN+KM),N为Light Probe的大小,M为Irradiance Map的大小,其中K为SH系数的个数,对于Diffuse光照,使用3阶的SH函数就能获得不错的近似结果,3阶的SH有9个系数,所以K远小于N和M。
因为Diffuse光照本身是低频的,所以输出的Irradiance Map可以使用较小的分辨率,那么整个算法的开销主要是在第一步——把Light Probe投影到 SH上。
- 使用GPU计算Light Probe SH
GPU Gems 2 的Chapter 10介绍了使用pixel shader来计算Light Probe SH的方法,使用SM5.0的Compute Shader来计算可以获得更大的加速比。
观察求解Light Probe SH的过程——遍历所有的texel,对于每个texel,求解出SH,然后累加,最后累加的结果就是SH系数。如果使用并行的算法,伪代码如下:
g_mutex; for each texel of the lightProbe { lightSample = texelRadiance; //计算光照方向 l = texelDirection; //根据光照方向求出SH基函数 SHBasis = calculateSHBasis(l); //累加SH系数 g_mutex.lock(); lightSH += lightSample*SHBasis*texelSolidAngle; weight += texelSolidAngle; g_mutex.unlock(); } lightSH = lightSH*4*PI/weight;
但是对于GPU的Compute Shader,只能同步一个Group里的thread,对于不同Group的thread无法同步,所以无法使用一个加锁的全局变量不断累加的方法。
既然无法一次求出所有的累加结果,那么就先求出每个Group的累加结果,然后根据GroupID写入到输出的Buffer,然后把这个Buffer作为输入,重复之前的操作,直到输出Buffer的Size为1时就求出了结果。比如对于一个512x512的Cube Map,固定Thread Group大小为8x8,那么我们分配64x64个Group,其输出Buffer大小为64x64(每一个Group输出一个结果),运行Compute Shader计算结果输出到Buffer,这时数据就缩小到了64x64,然后重复之前的操作,下一轮的数据大小就变成了8x8(64/8)。一直重复这个操作,直到输出的Buffer大小为1时就求解出了结果。
这个算法的思路和HDR渲染中求解场景的平均亮度是一样的,在求解平均亮度时,每次把Texture的Size缩小到1/4做Down Sample,直到Texture大小为1x1时就求出了平均亮度。
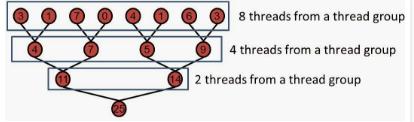
求解每个Group的SH累加结果的算法参考Nvidia的 “Optimizing Parallel Reduction in CUDA”, Parallel Reduction的思路就是一个递归的tree-based approach,如下图
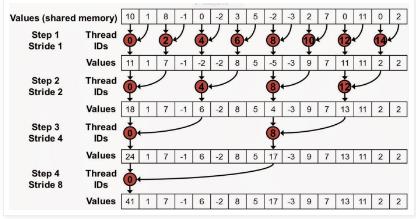
对于Shader代码,使用循环来模拟这个过程,具体做法是设置一个步长step,把相隔step个步长的数据相加,然后step乘以2,重复这个过程,直到step大于N,N为输入数据的大小,循环累加的代码如下:
for (uint s = 1; s < groupthreads; s *= 2) // stride: 1, 2, 4, 8, 16,32, 64, 128 { int index = 2 * s * GI; if (index < (groupthreads)) sharedMem[index] += sharedMem[index + s]; GroupMemoryBarrierWithGroupSync(); }
算法的流程如下图:
完整的Shader代码如下:
#define THREAD_SIZE_X 8 #define THREAD_SIZE_Y 8 #define GROUP_THREADS THREAD_SIZE_X*THREAD_SIZE_Y Texture2D<float> g_InputBuffer : register(t0); RWTexture2D<float> g_OutputBuffer : register(u0); groupshared float g_ShareMem[GROUP_THREADS]; [numthreads(THREAD_SIZE_X, THREAD_SIZE_Y, 1)] void ReductionCS(uint3 Gid : SV_GroupID, uint3 DTid : SV_DispatchThreadID, uint3 GTid : SV_GroupThreadID, uint GI : SV_GroupIndex) { //加载数据到share memory中 uint Idx = DTid.y*g_InputBuffer.Length.x + DTid.x; g_ShareMem[GI.xy] = g_InputBuffer[Idx]; GroupMemoryBarrierWithGroupSync(); // 循环累加所有数据 [unroll] for (uint s = 1; s < GROUP_THREADS; s *= 2) // stride: 1, 2, 4, 8, 16, 32, 64, 128 { int index = 2 * s * GI; if (index < GROUP_THREADS) g_ShareMem[index] += g_ShareMem[index + s]; GroupMemoryBarrierWithGroupSync(); } if (GI == 0) { //写入结果 g_OutputBuffer[Gid.xy] = g_ShareMem[0]; } }
NV的paper中还提到了可以进一步优化,GPU在运行Thread Group时,会把Thread划分为Warp,Nvidia的GPU中一个Warp包含32个Thread,这些线程是由SIMD32处理器同步运行的,所以如果线程数目小于32时,可以去掉GroupMemoryBarrierWithGroupSync() 的调用来提升性能。(对于AMD的GPU,把线程划分为Wavefronts,和NV的Warp对应,AMD的每个Wavefronts中包含64个同步执行的Thread)
- 运行结果
运行的参考对象是DirectX ToolKit中的SHProjectCubeMap,这个函数使用CPU来计算Light Probe SH。测试使用的Light Probe是一个512x512的R16G16B16A16_FLOAT格式的HDR Cube Map,测试结果发现在Release模式下使用Compute Shader可以比DXTK的CPU版本快10倍以上,加速比很高。

- 其他
1. Light Probe一般都是HDR格式的,所以生成的Irradiance Map也是HDR格式的,那么使用Irradiance Map计算光照时需要使用HDR渲染。
2. Diffuse Lighting一般用3阶的SH足矣,对于HDR的Light Probe,5阶的SH会更准确(4阶的Diffuse Transer SH系数为0,所以无需使用)。当然也意味着更多的计算量。
3. 使用GPU计算的时候,计算的结果参考了DXTK的函数,但是发现和DXTK的结果有些许偏差。仔细调试后发现是浮点累加误差导致的,DXTK的结果并不准确,在其SHProjectCubeMap源码实现中,是使用float类型不断累加,比如对于求解solid angle weight,最后的结果会累加到几百万,但是对于单个的weight数据,其值可能只有1左右,而float有效数字只有6位,所以在累加的过程中会有误差,数据到几百万时,误差可能会达到几十。理论上来讲,solid angle weight是使用texture uv求解的,那么对于Cube Map的每一个face,其累加结果应该都是相同的,DXTK因为使用float累加,浮点误差导致其每个face的solid angle weight累加结果并不相同,所以DXTK的结果并不准确,只能作为参考值。
实际上相比于DXTK,GPU算法的准确度更高,因为调试的时候发现GPU求解出来的结果,每一个face的solid angle累加结果都是相同的,不会像DXTK那样有误差。因为在GPU算法中,累加是分层求解的(参考前面的算法图解),每一层中的节点数据范围都差不多,这样浮点的误差就不会像直接累加那么大,所以GPU求解的速度和精度都好于DXTK的SHProjectCubeMap。
参考资料:
http://http.developer.nvidia.com/GPUGems2/gpugems2_chapter10.html
http://developer.download.nvidia.com/assets/cuda/files/reduction.pdf
http://diaryofagraphicsprogrammer.blogspot.com/2014/03/compute-shader-optimizations-for-amd.html
https://seblagarde.wordpress.com/2012/06/10/amd-cubemapgen-for-physically-based-rendering/
以上是关于使用Compute Shader加速Irradiance Environment Map的计算的主要内容,如果未能解决你的问题,请参考以下文章