三十分钟理解计算图上的微积分:Backpropagation,反向微分
Posted 大饼博士X
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了三十分钟理解计算图上的微积分:Backpropagation,反向微分相关的知识,希望对你有一定的参考价值。
神经网络的训练算法,目前基本上是以Backpropagation (BP) 反向传播为主(加上一些变化),NN的训练是在1986年被提出,但实际上,BP 已经在不同领域中被重复发明了数十次了(参见 Griewank (2010)[1])。更加一般性且与应用场景独立的名称叫做:反向微分 (reverse-mode differentiation)。本文是看了资料[2]中的介绍,写的蛮好,自己记录一下,方便理解。
从本质上看,BP 是一种快速求导的技术,可以作为一种不单单用在深度学习中并且可以胜任大量数值计算场景的基本的工具。
计算图
必须先来讲一讲计算图的概念,计算图出现在Bengio 09年的《Learning Deep Architectures for AI》,
Bengio使用了有向图结构来描述神经网络的计算:
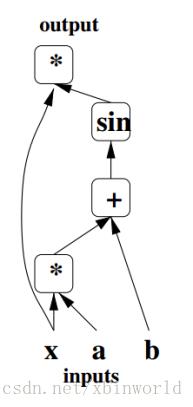
整张图可看成三部分:输入结点、输出结点、从输入到输出的计算函数。上图很容易理解,就是output=sin(a*x+b) * x
计算图上的导数
有向无环图在计算机科学领域到处可见,特别是在函数式程序中。他们与依赖图(dependency graph)或者调用图(call graph)紧密相关。同样他们也是大部分非常流行的深度学习框架背后的核心抽象。
下文以下面简单的例子来描述:
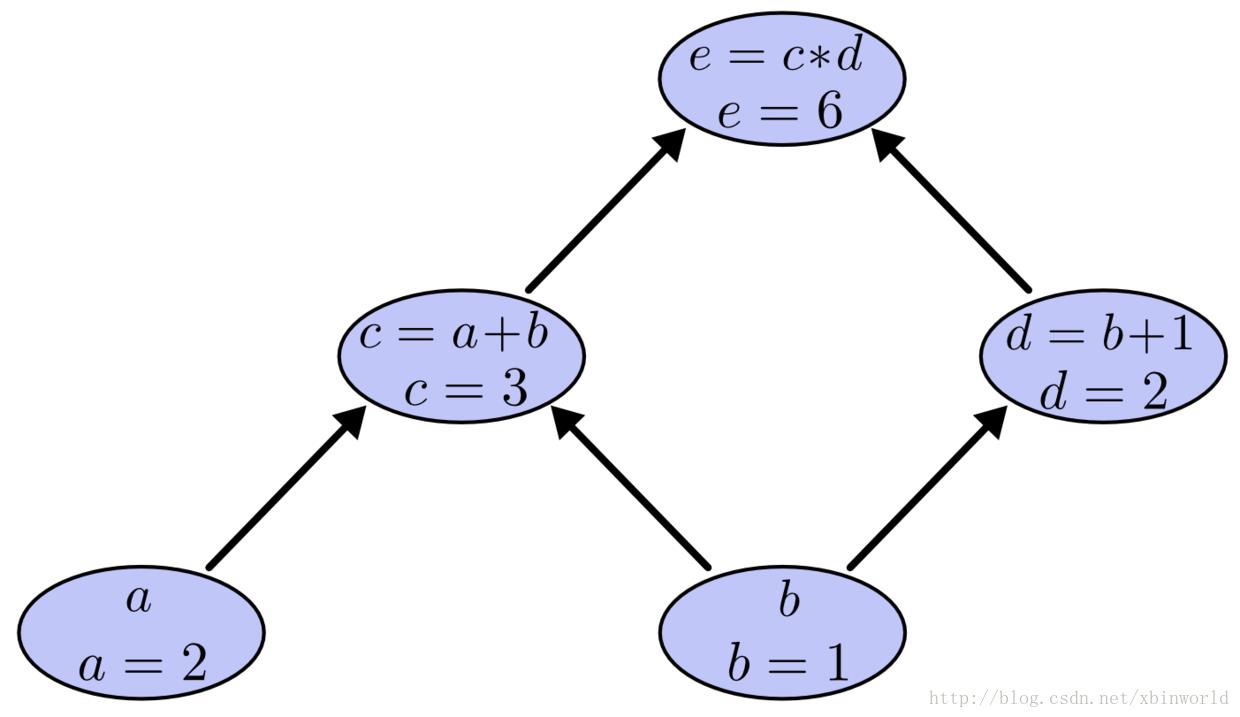
假设 a = 2, b = 1,最终表达式的值就是 6。
为了计算在这幅图中的偏导数,我们需要 和式法则(sum rule )和 乘式法则(product rule):
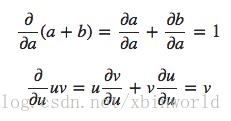
下面,在图中每条边上都有对应的导数了:
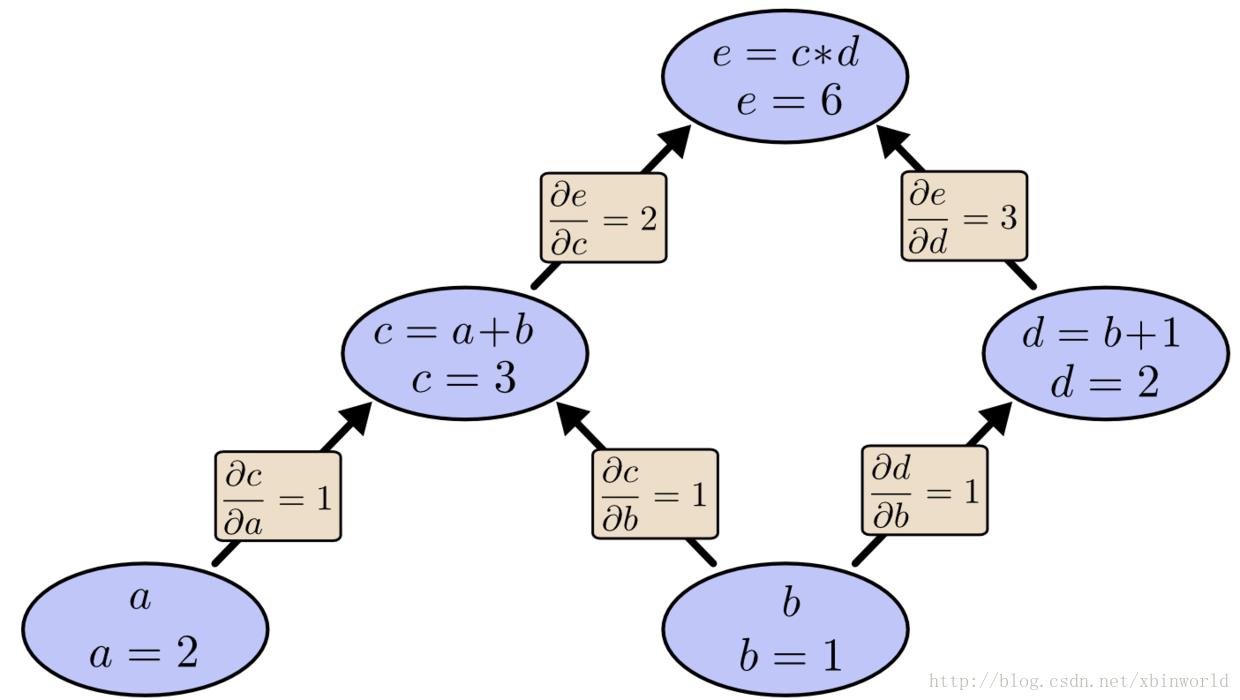
那如果我们想知道哪些没有直接相连的节点之间的影响关系呢?假设就看看 e 如何被 a 影响的。如果我们以 1 的速度改变 a,那么 c 也是以 1 的速度在改变,导致 e 发生了 2 的速度在改变。因此 e 是以 1 * 2 的关于 a 变化的速度在变化。
而一般的规则就是对一个点到另一个点的所有的可能的路径进行求和,每条路径对应于该路径中的所有边的导数之积。因此,为了获得 e 关于 b 的导数,就采用路径求和:
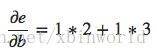
这个值就代表着 b 改变的速度通过 c 和 d 影响到 e 的速度。聪明的你应该可以想到,事情没有那么简单吧?是的,上面例子比较简单,在稍微复杂例子中,路径求和法很容易产生路径爆炸:
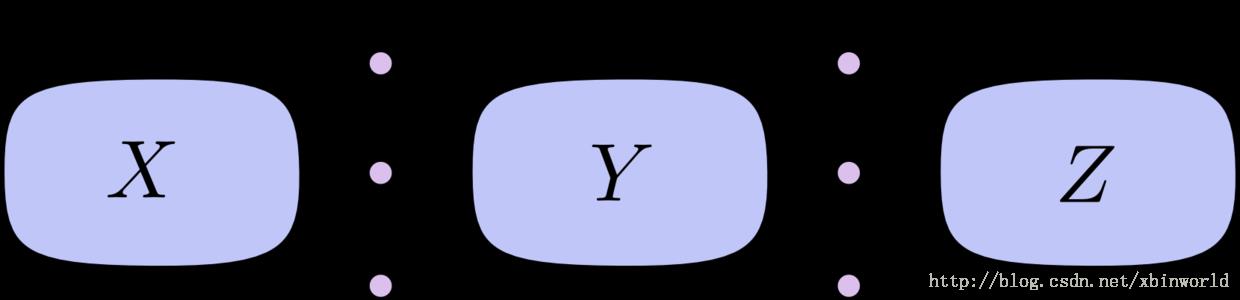
在上面的图中,从 X 到 Y 有三条路径,从 Y 到 Z 也有三条。如果我们希望计算 dZ/dX,那么就要对 3 * 3 = 9 条路径进行求和了:
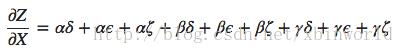
该图有 9 条路径,但是在图更加复杂的时候,路径数量会指数级地增长。相比于粗暴地对所有的路径进行求和,更好的方式是进行因式分解:
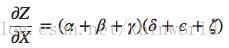
有了这个因式分解,就出现了高效计算导数的可能——通过在每个节点上反向合并路径而非显式地对所有的路径求和来大幅提升计算的速度。实际上,两个算法对每条边的访问都只有一次!
前向微分和反向微分
前向微分从图的输入开始,一步一步到达终点。在每个节点处,对输入的路径进行求和。每个这样的路径都表示输入影响该节点的一个部分。通过将这些影响加起来,我们就得到了输入影响该节点的全部,也就是关于输入的导数。
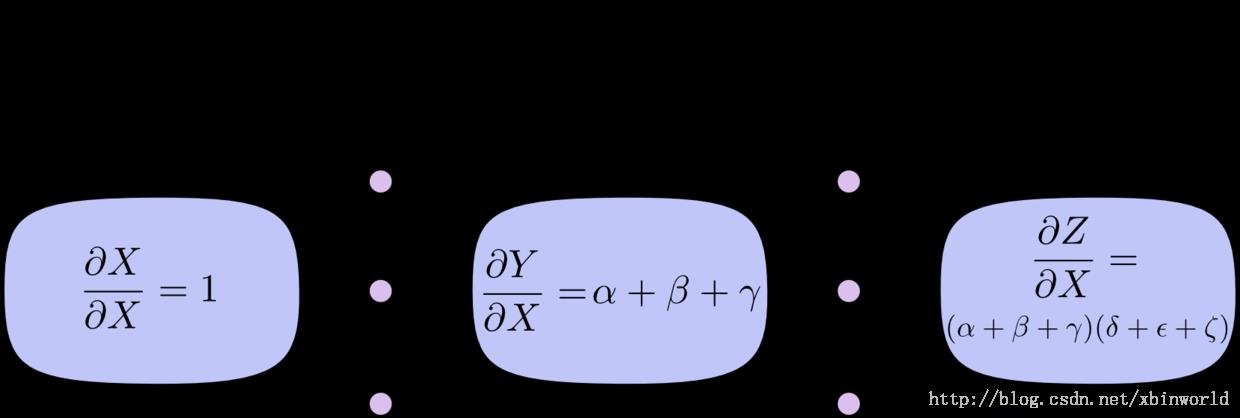
相对的,反向微分是从图的输出开始,反向一步一步抵达最开始输入处。在每个节点处,会合了所有源于该节点的路径。
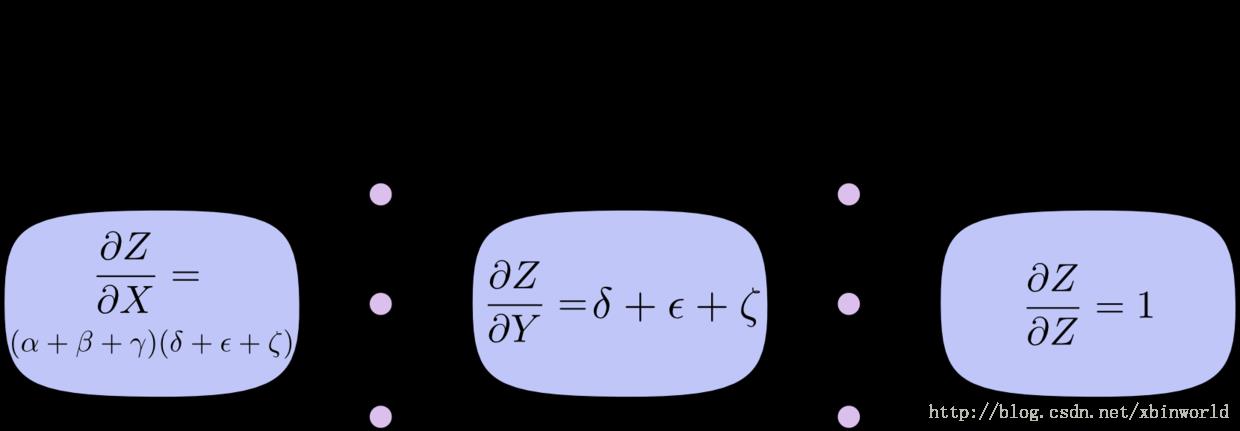
前向微分 跟踪了输入如何改变每个节点的情况。反向微分 则跟踪了每个节点如何影响输出的情况。也就是说,前向微分应用操作 d/dX 到每个节点,而反向微分应用操作 dZ/d 到每个节点。
让我们重新看看刚开始的例子:
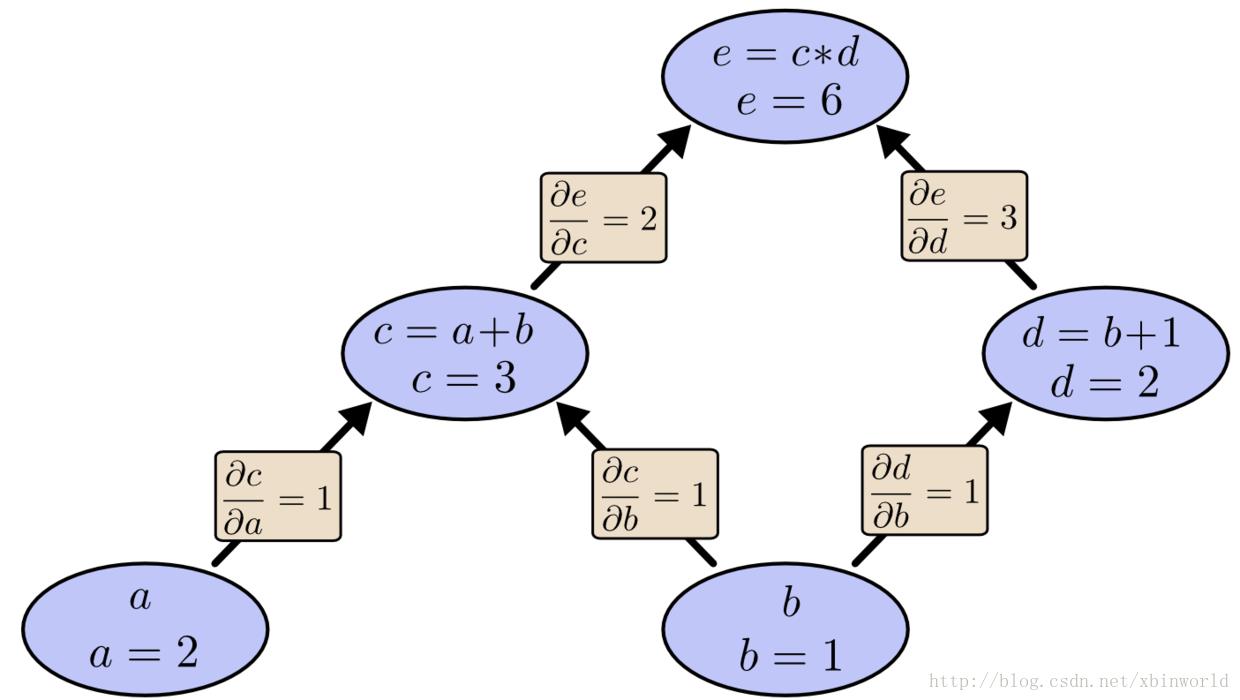
我们可以从 b 往上使用前向微分。这样获得了每个节点关于 b 的导数。(写在边上的导数我们已经提前算高了,这些相对比较容易,只和一条边的输入输出关系有关)
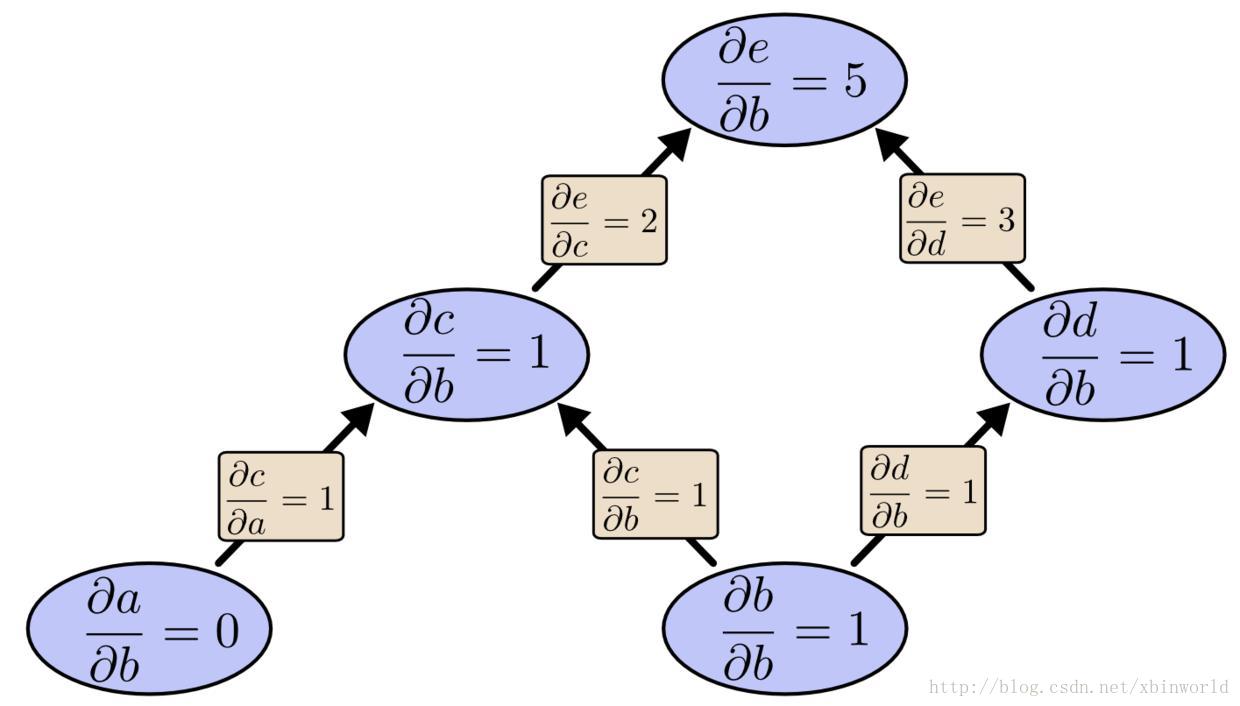
我们已经计算得到了 de/db,输出关于一个输入 b 的导数。但是如果我们从 e 往回计算反向微分呢?这会得到 e 关于每个节点的导数:
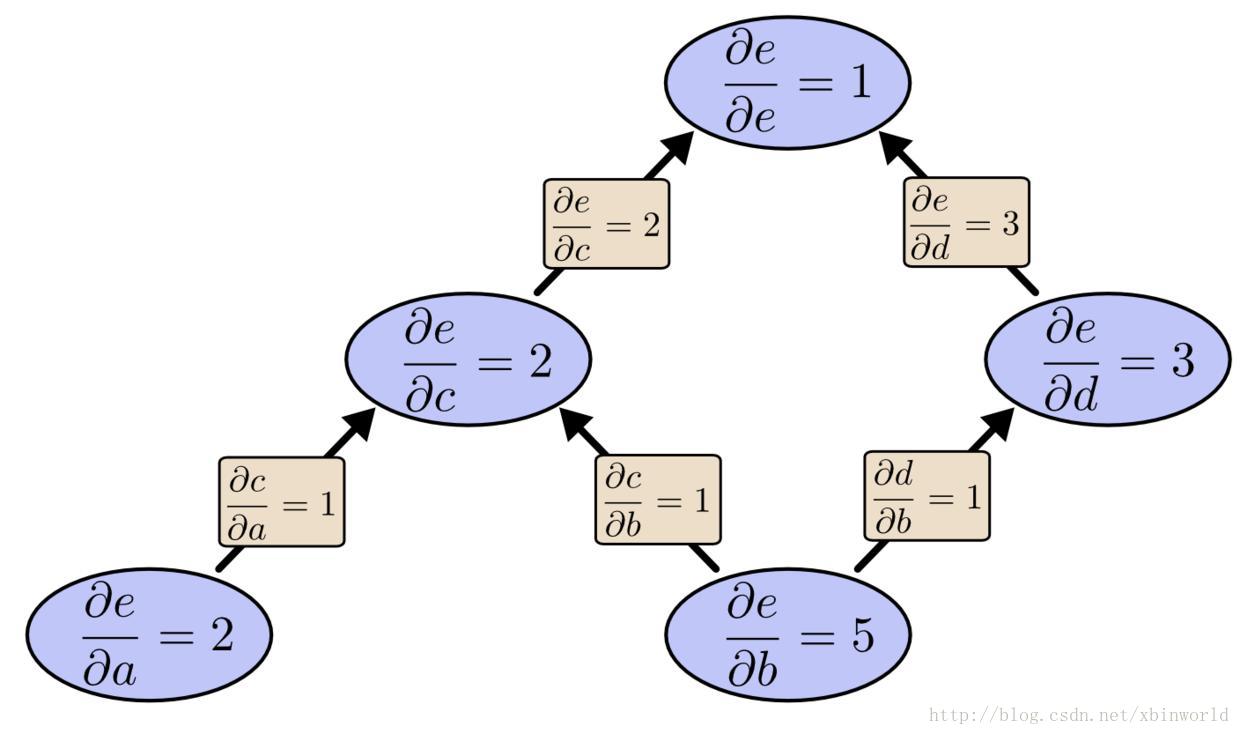
反向微分给出了 e 关于每个节点的导数,这里的确是每一个节点。我们得到了 de/da 和 de/db,e 关于输入 a 和 b 的导数。(当然中间节点都是包括的),前向微分给了我们输出关于某一个输入的导数,而反向微分则给出了所有的导数。
想象一个拥有百万个输入和一个输出的函数。前向微分需要百万次遍历计算图才能得到最终的导数,而反向微分仅仅需要遍历一次就能得到所有的导数!速度极快!
训练神经网络时,我们将衡量神经网络表现的代价函数看做是神经网络参数的函数。我们希望计算出代价函数关于所有参数的偏导数,从而进行梯度下降(gradient descent)。现在,常常会遇到百万甚至千万级的参数的神经网络。所以,反向微分,也就是 BP,在神经网络中发挥了关键作用!所以,其实BP的本质就是链式法则。
(有使用前向微分更加合理的场景么?当然!因为反向微分得到一个输出关于所有输入的导数,前向微分得到了所有输出关于一个输入的导数。如果遇到了一个有多个输出的函数,前向微分肯定更加快速)
BP 也是一种理解导数在模型中如何流动的工具。在推断为何某些模型优化非常困难的过程中,BP 也是特别重要的。典型的例子就是在 Recurrent Neural Network 中理解 vanishing gradient 的原因。
有的时候,越是有效的算法,原理往往越是简单。
参考资料
[1] Who Invented the Reverse Mode of Differentiation?
[2] http://www.jianshu.com/p/0e9eea729476
以上是关于三十分钟理解计算图上的微积分:Backpropagation,反向微分的主要内容,如果未能解决你的问题,请参考以下文章
三十分钟理解:线性插值,双线性插值Bilinear Interpolation算法
三十分钟理解:双调排序Bitonic Sort,适合并行计算的排序算法
三十分钟理解博弈论“纳什均衡” -- Nash Equilibrium
索引::机器学习方法系列,深度学习方法系列,三十分钟理解系列等