如果我把CDR网络禁止掉是否就不会翻车了
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如果我把CDR网络禁止掉是否就不会翻车了相关的知识,希望对你有一定的参考价值。
把CDR网络禁止掉不会掉线,操作方法如下:
1、首先在电脑中打开CorelDRAW X8软件,进入软件工作界面,如下图所示。
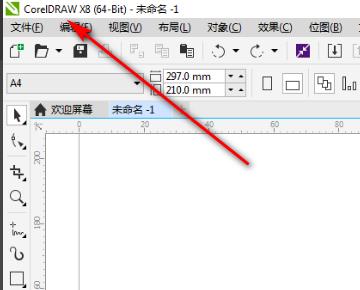
2、然后点击【基本形状工具】,如下图所示。
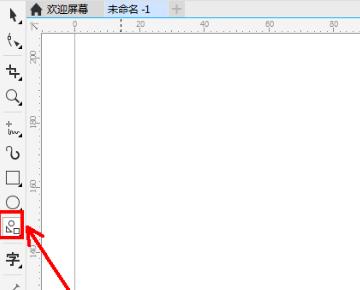
3、接着在打开的页面中,点击【完美形状】,如下图所示。

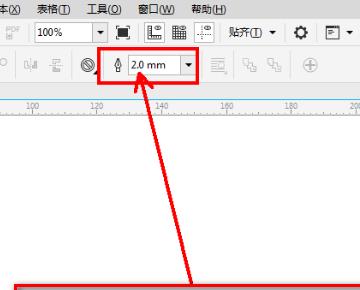
4、点击【禁止图标】,轮廓宽度设置为:2mm,如下图所示。
5、绘制出一个禁止图标并设置好图案的各个尺寸参数(如图所示),就完成了。

第一种就是通过电脑本身自带的防火墙,利用防火墙阻挡CDR连接网络。
第二种是通过其他app比如360安全卫士或者电脑管家类的软件 通过流量管理然后找到CDR禁止网络连接即可 参考技术B 网络禁掉是永久的禁掉么,还是说安装的时候不联网,如果只是安装的时候,破解版的可以安装上去,但是在使用的时候如果打开网络还是会有反盗版的提示,现在中国软件市场对盗版打击力度在不断加大,不然软件开发商,运营商靠什么吃饭,毕竟盗版也是侵权的,预计未来大家可能都找不到破解及盗版软件了,还是建议使用正版软件的 参考技术C 网站客服系统可以帮助网站客服查看到正在浏览网店的客户,让客服具备洞察出客户购买心理的能力,减少客服的工作量,将网站流量转化为销售订单,提升订单质量并减少订单丢失几率。推荐快商通智能营销客服,不仅功能强大,服务还周到。
spark在生产中是否要禁止掉BHJ(BroadcastHashJoin)
背景
本文基于spark 3.2
driver内存 2G
问题描述
在基于复杂的sql运行中,或者说是存在多个join操作的sql中,如果说driver内存不是很大的情况下,我们经常会遇到如下报错:
Caused by: org.apache.spark.SparkException: Could not execute broadcast in 800 secs. You can increase the timeout for broadcasts via spark.sql.broadcastTimeout or disable broadcast join by setting spark.sql.autoBroadcastJoinThreshold to -1
at org.apache.spark.sql.execution.adaptive.BroadcastQueryStageExec$$anon$1.run(QueryStageExec.scala:217)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
其实从字面上就可以理解:broadcast的数据超时了,这种经常是由于广播的数据量太大引起的,spark中默认的广播大小不是只有10M才会进行广播么?
spark.sql.autoBroadcastJoinThreshold默认为10M
为什么还会存在广播的数据量很大呢?
问题分析
直接说重点:
在spark中 SMJ转BHJ 在两个阶段会发生:
- 正常的物理计划的生成阶段,也就是SparkPlanner中的JoinSelection规则中
- AQE阶段,也就是AdaptiveSparkPlanExec中的reOptimize方法
其实这两个阶段调用的方法都是一样的都是调用了sparkPlanner的JoinSelection规则
我们说说第一阶段,也就是正常的物理计划的生成阶段,即JoinSelection规则
这里的重要的方法是canBroadcastBySize:
def canBroadcastBySize(plan: LogicalPlan, conf: SQLConf): Boolean =
plan.stats.sizeInBytes >= 0 && plan.stats.sizeInBytes <= conf.autoBroadcastJoinThreshold
具体的逻辑阶段的统计信息,可以参考spark logicalPlan Statistics (逻辑计划阶段的统计信息),这里如果我们是基于文件读取的话(大部分就是基于文件的读取),如果说我们的的sql是
##其中tableA有很多字段,我们只选取a,b两个字段
select a,b from tableA
这里的逻辑阶段的数据统计就是一个大概的计算:
private def visitUnaryNode(p: UnaryNode): Statistics =
// There should be some overhead in Row object, the size should not be zero when there is
// no columns, this help to prevent divide-by-zero error.
val childRowSize = EstimationUtils.getSizePerRow(p.child.output)
val outputRowSize = EstimationUtils.getSizePerRow(p.output)
// Assume there will be the same number of rows as child has.
var sizeInBytes = (p.child.stats.sizeInBytes * outputRowSize) / childRowSize
if (sizeInBytes == 0)
// sizeInBytes can't be zero, or sizeInBytes of BinaryNode will also be zero
// (product of children).
sizeInBytes = 1
// Don't propagate rowCount and attributeStats, since they are not estimated here.
Statistics(sizeInBytes = sizeInBytes)
...
def getSizePerRow(
attributes: Seq[Attribute],
attrStats: AttributeMap[ColumnStat] = AttributeMap(Nil)): BigInt =
// We assign a generic overhead for a Row object, the actual overhead is different for different
// Row format.
8 + attributes.map attr =>
if (attrStats.get(attr).map(_.avgLen.isDefined).getOrElse(false))
attr.dataType match
case StringType =>
// UTF8String: base + offset + numBytes
attrStats(attr).avgLen.get + 8 + 4
case _ =>
attrStats(attr).avgLen.get
else
attr.dataType.defaultSize
.sum
我们看到其实就是对于从一个表中读取一个字段的大小是基于改字段类型所占avgLen的大小除以该表中所有字段总的类型的avgLen的一个比值:
如: select a from tableA, 假如tableA是50M 有a,b,c,d,e三个字段,其中a是int类型,且avgLen是10,b,c,d,e是string类型,且avgLen是20。
则该sql算出来的size就是 10/(10+4*(10+8+4))*50M=5.1M 这样这个sql所对应的临时表就能进行广播。
但是正如spark里说的:
Statistics collected for a column.
1. The JVM data type stored in min/max is the internal data type for the corresponding Catalyst data type. For example, the internal type of DateType is Int, and that the internal type of TimestampType is Long. 2. There is no guarantee that the statistics collected are accurate. Approximation algorithms (sketches) might have been used, and the data collected can also be stale.
Params:
distinctCount – number of distinct values
min – minimum value
max – maximum value
nullCount – number of nulls
avgLen – average length of the values. For fixed-length types, this should be a constant.
maxLen – maximum length of the values. For fixed-length types, this should be a constant.
histogram – histogram of the values
version – version of statistics saved to or retrieved from the catalog
这些统计信息有可能是不准确的,所以在计算的时候,有可能broadcast的数据就相对比较大,如果存在这种join有很多的情况下,就会导致driver端很卡,甚至OOM
我们再说说第二阶段,也就是AQE阶段
其实这个阶段核心还是getFinalPhysicalPlan方法中的createQueryStages方法和reOptimize方法,
在createQueryStages方法中如果方法已经是BroadcastExchangeExec的话,就会直接包装成ShuffleQueryStageExec,
如果是ShuffleExchangeExec的话,在下一个阶段会经过reOptimize方法根据运行时的统计信息大小,来进行是否可以进行SMJ到BHJ的转换
这里在的阈值判断是通过spark.sql.adaptive.autoBroadcastJoinThreshold来判断的,默认也是10M,
所以在spark UI上有时候能看到broadcast 的datasize有50M甚至100多M,而明明broadcast的阈值是10M,却变成了BroadCastHashJoin。
结论
所以在大数据量,以及在复杂的sql情况下,禁止broadcasthashjoin是明确的选择,毕竟稳是一切运行的条件,但是也是可以根据单个任务个别开启。
以上是关于如果我把CDR网络禁止掉是否就不会翻车了的主要内容,如果未能解决你的问题,请参考以下文章