行为模式--字节码
Posted 夜色魅影
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了行为模式--字节码相关的知识,希望对你有一定的参考价值。
出处:Game Programming Patterns
理论要点
-
什么是字节码模式:将行为编码为虚拟机器上的指令,来赋予其数据的灵活性。从而让数据易于修改,易于加载,并与其他可执行部分相隔离。
-
要点
1,字节码模式:指令集定义了可执行的底层操作。一系列的指令被编码为字节序列。 虚拟机使用中间值堆栈依次执行这些指令。 通过组合指令,可以定义复杂的高层行为。2,可以理解为项目中的转表工具,将excel中的数据转为二进制数据,并读取到工程中。还有如在项目中使用protobuf,json,xml等都是这么个思路。
3,字节码类似GOF的解释器模式,这两种方式都能让我们将数据与行为相组合。其实很多时候都是两者一起使用。用来构造字节码的工具会有内部的对象树,而为了编译到字节码,我们需要递归回溯整棵树,就像用解释器模式去解释它一样。唯一的不同在于,并不是立即执行一段行为,而是生成整个字节码再执行。
-
使用场合
像C++这样的编译型语言开发游戏,一个功能刚开发完甚至还没开发完,策划又该需求了,这里调下数值,那里调下表现,等等诸如此类,犹如家常便饭。
而如果是大型项目,改需求难点不是实现需求,而是烦人的编译时间,而且对于上线的项目,我甚至得重新出包发布。更恐怖的如果遇到error,我程序就直接over了。我们是不是可以想个办法,把需求行为和游戏主逻辑隔开,这样底层不变,上层行为通过中间层传递给底层使用,这时,即使上层行为要修改或是有bug都不影响我们底层代码的运行。这有点像数据,如果能在分离的数据文件中定义行为,游戏引擎还能加载并“执行”它们,就可以实现所有目标- - -即把行为转换为数据使用。
这其实有点类似,“开发我们自己的程序语言”,想想,我们自己定义一套指令集,分别实现编译器和解释器,编译器负责把我们自定义的语言转换为类似机器码的字节码,这种字节码然后通过我们的解释器解析为机器码。如果实现了这些,那么我们自定义的语言就真的能被计算机识别使用了,到时再把它以自己名字命名。想想是不是很激动!(像现在很多脚步语言,如Lua等都是这样发展而来的)
但需要注意,这种中间字节码的形式比直接本地机器码代码慢,所以最好不要用于引擎对性能敏感的部分。
代码分析
1,实现自己语言前,我们先温习下与之类似的GOF的解释器模式:假设我们要让语言支持这样的算术表达式:(1 + 2) * (3 - 4)
我们的做法是把每块表达式,每条语言规则,都封装到对象中去,那么最终就会变成如下这样的抽象语法树。
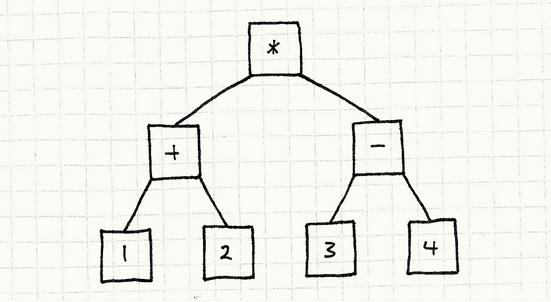
创建这棵树是编译器的工作,我们这里讲的解释器模式与这无关。怎么形成的先不管,下面我们来看看怎么去解析这颗树,即实现解释器:
首先,我们定义所有表达式的基本接口:
class Expression
{
public:
virtual ~Expression() {}
virtual double evaluate() = 0; //求值
};
然后,实现数字派生类:
class NumberExpression : public Expression
{
public:
NumberExpression(double value)
: value_(value)
{}
virtual double evaluate()
{
return value_;
}
private:
double value_;
};
最后就是运算符了,下面是加法的实现:
class AdditionExpression : public Expression
{
public:
AdditionExpression(Expression* left, Expression* right)
: left_(left),
right_(right)
{}
virtual double evaluate()
{
// 计算操作数
double left = left_->evaluate();
double right = right_->evaluate();
// 把它们加起来
return left + right;
}
private:
Expression* left_;
Expression* right_;
};
好,这样支持简单的算术计算的解释器就实现了。然而,很明显它是把每种指令都封装成对象,想想如果处理的问题比较复杂,那么会是个庞大的语法树,层次很,深,而且需要new很多对象。这样明显效率不好且耗内存。
2,上面我们已经实现了解释器模式,它的优点就是安全,因为它的语法行为是我们自己定义的,不直接接触底层。但是缺点也很明显,就是效率低、耗内存。
再想想我们现有的语言C++,它是直接把这些指令编译成机器码,机器码是一组密集的,线性的,底层的指令,硬件直接识别,它效率飞快。然而,我们总不能指望要用户编写机器码吧,这肯定不现实,也不安全(硬件直接识别,所以不安全)。
那我们想过没有,如果把它们两者结合起来,不是直接加载机器码,而是定义自己的虚拟机器码呢? 然后,在游戏中写个小模拟器。 这与机器码类似,密集,线性,相对底层,但支持规则都是我们自己定义的,所以可以放心地将其放入沙箱。
我们将这个小模拟器称为虚拟机(或简称“VM”),它运行的虚拟机器码叫做字节码。 它有数据的灵活性和易用性,但比解释器模式有更好的性能。
这听起来有点高端吓人。不过下面经过我通俗易懂的解剖完后,其实拥有自己的语言也就那么回事!(我们风靡全球的lua脚步其实就是这个原理实现的,即使你不打算开发自己的语言,也至少能对lua语言有更多的了解)
好,下面我们就以一个通俗易懂的游戏情境来带你走进字节码模式,看看我是怎么实现这个能解析字节码的虚拟机的。
假设我们游戏中有两只怪物,他们可以互相攻击,释放法术。绝大多数法术是会改变怪物身上的某个状态,我们就从一组状态开始:如果是c++会这么设置:
void setHealth(int wizard, int amount); //设置生命值
void setWisdom(int wizard, int amount); //设置智力值
void setAgility(int wizard, int amount); //设置敏捷值
参数wizard是怪物目标,比如说用0代表玩家,用1代表对手。参数amount是改变对应属性的具体数值。
上面只有数值上的变化,这样的法术未免太单调,我们再加些特效作用:
void playSound(int soundId); //播发音效
void spawnParticles(int particleType); //播发粒子特效
好,上面这是我们硬代码的一般形式了,看看我们怎么来一步一步把这些API抽离出来,让它用我们自己定义的指令去解析执行。
首先,我们的目标是实现自己的解析器。好,那么我们需求解析什么呢?当然是上面API操作的所有状态,我们要把这些状态定义成指令。我们可以这样枚举它们:
enum Instruction
{
INST_SET_HEALTH = 0x00,
INST_SET_WISDOM = 0x01,
INST_SET_AGILITY = 0x02,
INST_PLAY_SOUND = 0x03,
INST_SPAWN_PARTICLES = 0x04
};
一个法术就是一系列这样的指令,每个指令对应一个行为操作。如下:
switch (instruction)
{
case INST_SET_HEALTH:
setHealth(0, 100);
break;
case INST_SET_WISDOM:
setWisdom(0, 100);
break;
case INST_SET_AGILITY:
setAgility(0, 100);
break;
case INST_PLAY_SOUND:
playSound(SOUND_BANG);
break;
case INST_SPAWN_PARTICLES:
spawnParticles(PARTICLE_FLAME);
break;
}
如果我把这套东西封装好,那么以后我们的法术代码就变成了一个个字节列表,列表保存的就是这些状态的枚举值,其实这就是所谓的字节码。
好,现在我们就实现我们的第一个虚拟机,像这样它就能解析一个完整的法术:
class VM
{
public:
void interpret(char bytecode[], int size)
{
for (int i = 0; i < size; i++)
{
char instruction = bytecode[i];
switch (instruction)
{
// 每条指令的跳转分支……
}
}
}
};
恩,是不是觉得这个虚拟机过于死板了,没错,它不能设置参数,我们不能设定攻击对手的法术,也不能减少状态上限。我们只能播放声音!
那要这个虚拟机生动起来,就得支持怎么引入参数?其实上面定义的状态集 + 这里的参数 = 数据。我们只要处理如何序列化的操作这个数据,其实这个过程就是我们的解析,而且释放法术这个行为也已经完美转换成纯数据了。那么现在就只有一个问题了,就是究竟怎么序列式操作这个数据呢?没错,堆栈。通过push,pop与外界交互数据,把所有数据用堆栈来保存。先我们来定义一个堆栈:
class VM
{
public:
VM()
: stackSize_(0)
{}
// 其他代码……
private:
static const int MAX_STACK = 128;
int stackSize_;
int stack_[MAX_STACK];
};
到时我们的一个技能对应的一组连续字节码就保存到这个stack_堆栈数组中,遍历这个堆栈过程就是执行技能的过程。
接着来看怎么加入(push),和取出(pop)数据:
class VM
{
private:
void push(int value)
{
// 检查栈溢出
assert(stackSize_ < MAX_STACK);
stack_[stackSize_++] = value;
}
int pop()
{
// 保证栈不是空的
assert(stackSize_ > 0);
return stack_[--stackSize_];
}
// 其余的代码
};
现在支持引入参数的指令执行操作就会这样从堆栈中pop取了:
switch (instruction)
{
case INST_SET_HEALTH:
{
int amount = pop();
int wizard = pop();
setHealth(wizard, amount);
break;
}
case INST_SET_WISDOM:
case INST_SET_AGILITY:
// 像上面一样……
case INST_PLAY_SOUND:
playSound(pop());
break;
case INST_SPAWN_PARTICLES:
spawnParticles(pop());
break;
}
然后,我们还得为添加数据(push)也定义一个指令,接着上面枚举INST_LITERAL = 0x05:
case INST_LITERAL:
{
//bytecode字节码数组,它就是我们的行为,我们这个虚拟机所有工作就是在解析它
int value = bytecode[++i];
push(value);
break;
}
好,这个第二次改进的虚拟机就搞完了。然后我们来个游戏实际情形分析下它的工作原理:“假设我们这次的技能操作是要给玩家自己加10点生命值。”这个行为对应的字节码数据就是这样:[0x05, 0, 0x05, 10, 0x00]。下面是示意图分析:
首先从空栈开始,虚拟机指向字节码数组的第一个:

然后,它执行第一个指令“INST_LITERAL",把下一个字节0压入堆栈。

接着执行第二个"INST_LITERAL",把下一个字节10压入堆栈。

最后执行”INST_SET_HEALTH"。它会弹出10存进amount,弹出0存进wizard。然后用这两个参数调用setHealth()。这就实现了我们为自己加血行为的整套字节码解析流程。
嗯,乍看上去貌似很完美了!不过还缺些行为,我们只有set属性,而没有get属性是不是?我们可以引入参数把属性设置为我们想要的值,这更像是数据。而如果我想把智力属性值设置为它的生命值,那这又怎么操作呢?很明显,我们得再添加些get指令:
case INST_GET_HEALTH:
{
int wizard = pop();
push(getHealth(wizard));
break;
}
case INST_GET_WISDOM:
case INST_GET_AGILITY:
// 你知道思路了吧……
现在,我们的虚拟机已经可以支持设置任意属性,得到当前属性,播发音效,粒子特效。好,我们接着再来丰富下它,让它支持更多的行为。接下来,我们添加一个算术指令,让它具有计算能力:
case INST_ADD:
{
int b = pop();
int a = pop();
push(a + b);
break;
}
算计指令就类似这样了,那么有了这些我们能实现什么复杂点的行为呢?来看看这么个示例:假设我们希望有个法术,能让玩家的血量增加敏捷和智慧的平均值。 用代码表示如下:
setHealth(0, getHealth(0) + (getAgility(0) + getWisdom(0)) / 2);
好,假设玩家目前有45点血量,7点敏捷,和11点智慧。 我们来看看实现这么个行为,我们是用的一组什么字节码数组和对应堆栈的数据变化,下面是演示这个过程的示例图:
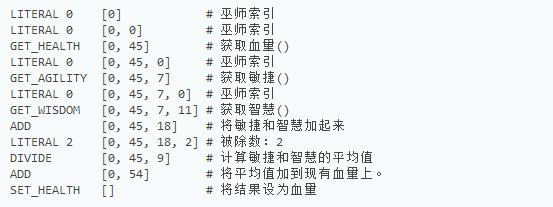
左边是指令,右边是对应的堆栈数据变化。这么个过程我们就计算出了玩家的血量增加敏捷和智慧的平均值。
我可以继续下去,添加越来越多的指令,但是时候适可而止了。 如上所述,我们已经有了一个可爱的小虚拟机,可以使用简单,紧凑的数据格式,定义开放的行为。 虽然“字节码”和“虚拟机”的听起来很吓人,但你可以看到它们往往简单到只需栈,循环,和switch语句。
再回过头来想想,是不是实现自己的虚拟机其实也就那么回事,首先我们对需要处理的问题定义好指令集合(枚举),从而某个行为就可以用这些对应指令来表示(字节码数组),然后用堆栈来遍历这组字节码(push存储数据,pop使用数据),执行对应操作。
3,到目前为止,我们虚拟机(解释器)已经讲完了,但是对应的编译器呢?我们上面所有操作的字节码数组都是自己手动写的,这样肯定不实用。很明显,我们需要写个上层的图形工具(编译器),就算不是程序的人也可以轻松使用这个工具编辑行为,然后生成对应的字节码数组。类似这样的东西:
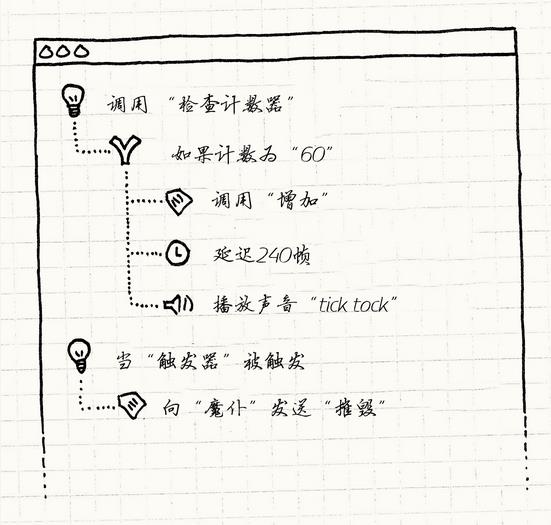
你可以做个这样的工具,用户通过单击拖动小盒子,下拉菜单项,或任何有意义的行为创建“脚本”,从而创建行为。
这样做的好处是,你的UI可以保证用户无法创建“无效的”程序。 与其向他们喷射错误警告,不如主动关闭按钮或提供默认值, 以确保他们创造的东西在任何时间点上都有效。
这篇已经太长了,其实到目前,关于怎么实现自定义语言的编译器,解释器原理已经讲得很清楚了。相信你只要认真看完了的,实现一个小型自定义语言是完全没压力的了。
比如游戏里的技能系统,我们刚好是不是可以做个工具让策划自己去编辑行为,然后生成字节码,最后我们的虚拟机去解析执行。这套东西做好后,我们程序里将没有一个硬代码,所有工作无非是策划的编辑事情了。这时我们就可以轻松的去倒杯咖啡,看着策划们调它们要的效果,而这再也与我们无关~
相信理解好这章并运用到你项目中后,一定能让你代码提示一大波气质~~
哈哈,结束!
以上是关于行为模式--字节码的主要内容,如果未能解决你的问题,请参考以下文章