直播技术总结音视频数据压缩及编解码基础
Posted 码农突围
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了直播技术总结音视频数据压缩及编解码基础相关的知识,希望对你有一定的参考价值。
转载请把头部出处链接和尾部二维码一起转载,本文出自逆流的鱼yuiop:http://blog.csdn.net/hejjunlin/article/details/60480109
音视频压缩技术是编解码中难点,常常会涉及很多算法处理问题。数据封装,转封装等,看下Agenda:
- 音视频为何需要压缩?
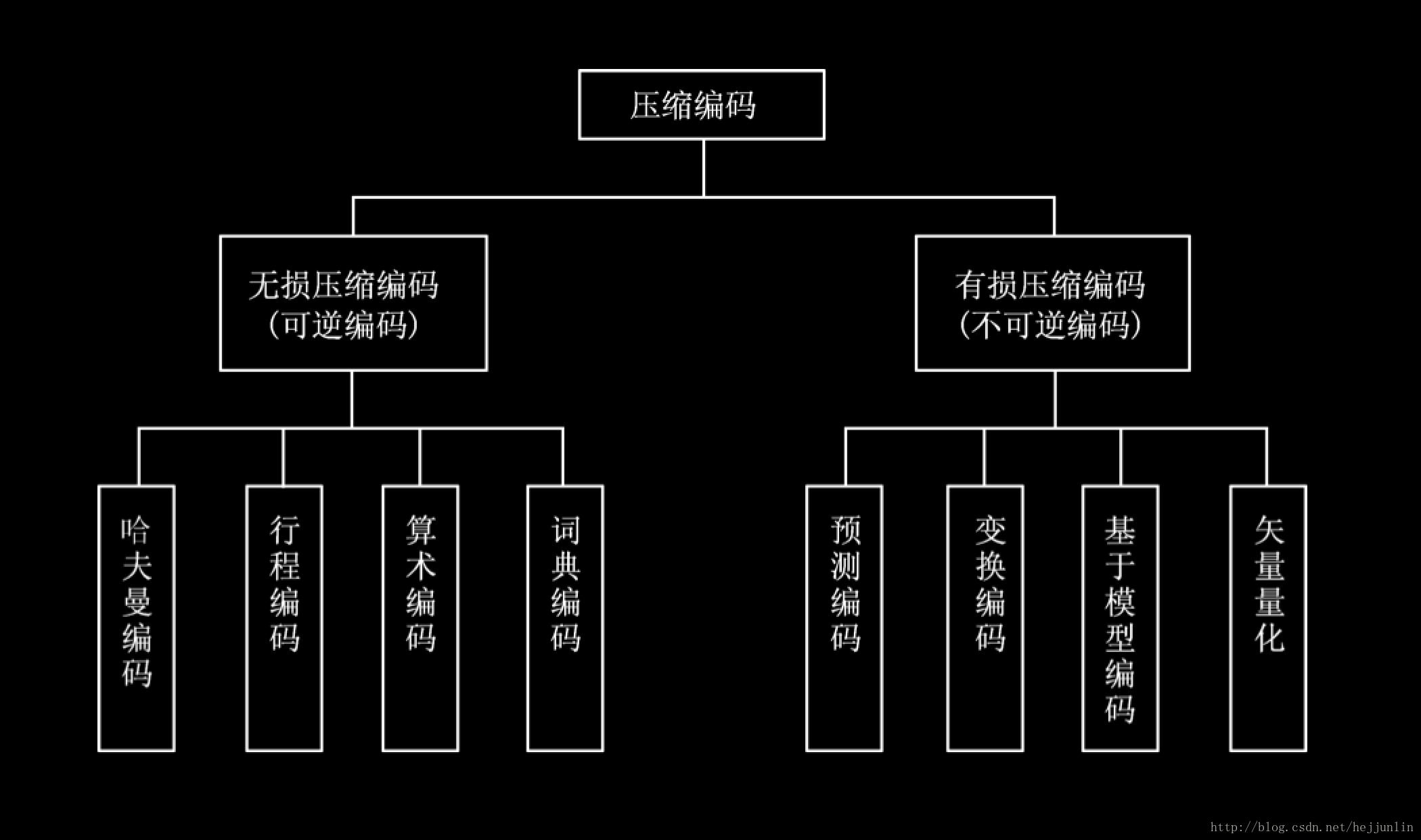
- 压缩编码的分类
- 常用压缩编码的方法
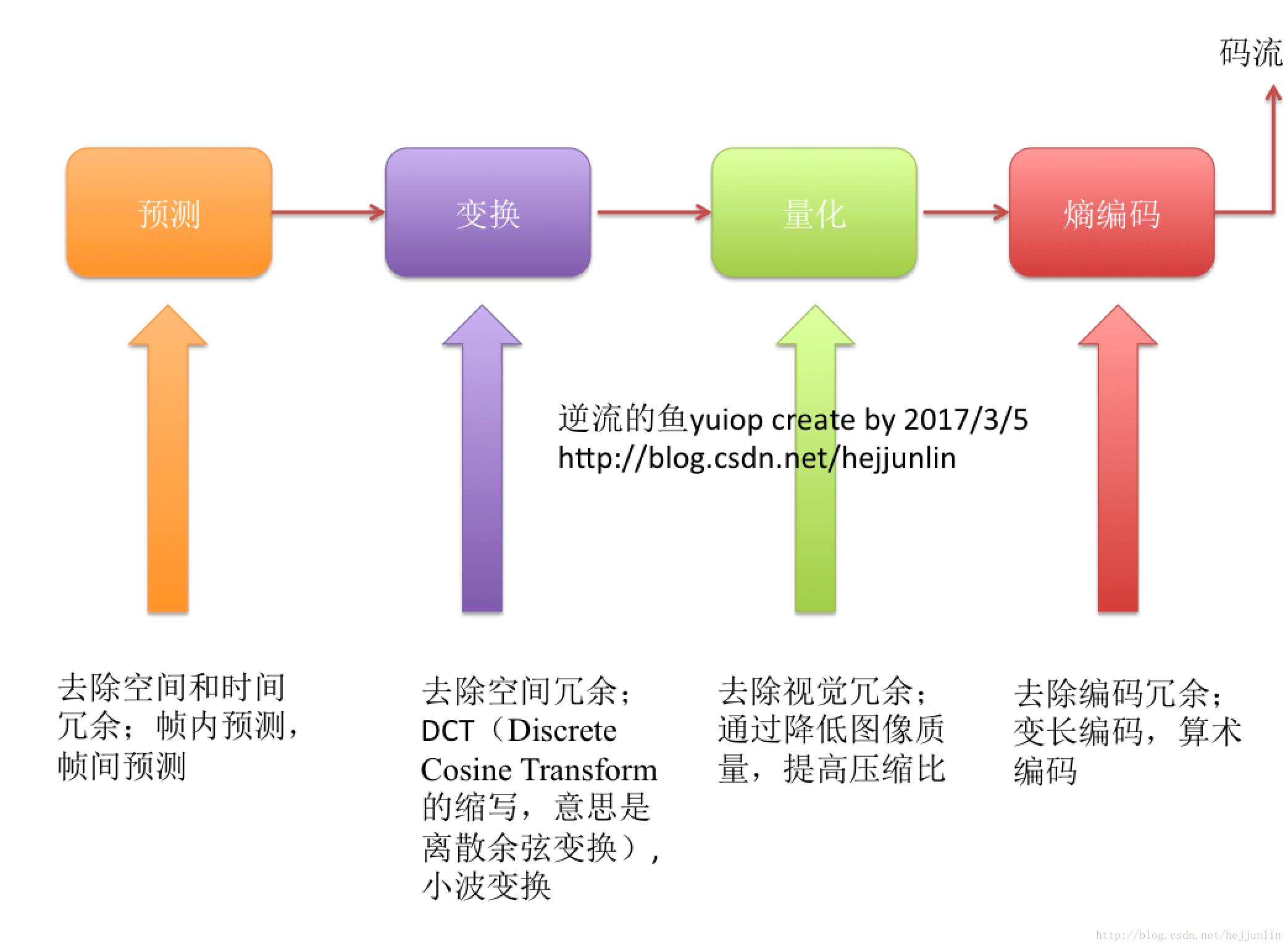
- 编码器中的关键技术
- 预测
- 量化
- 变换
- 熵编码
- 编解码中的情况
音视频为何需要压缩?
未经压缩的数字视频的数据量巨大
- 存储困难:一张DVD只能存储几秒钟的未压缩数字视频。
- 传输困难 : 1兆的带宽传输一秒的数字电视视频需要大约4分钟。
压缩编码的重要性:
- 数据压缩是通过减少计算机中所存储数据或者通信传播中数据的冗余度,达到增大数据密度,最终使数据的存储空间减少的技术
压缩编码的分类:
- 1、空间冗余。在很多图像数据中,像素间在行、列方向上都有很大的相关性,相邻像素的值比较接近,或者完全相同,这种数据冗余叫做空间冗余。
- 2、时间冗余。在视频图像序列中,相邻两帧图像数据有许多共同的地方,这种共同性称为时间冗余,可采用运动补偿算法来去掉冗余信息.
- 3、视觉冗余。视觉冗余度是相对于人眼的视觉特性而言的,人类视觉系统对图像的敏感性是非均匀和非线性的,并不是图像中的所有变化人眼都能观察到。
- 4、信息熵冗余。信息熵是指一组数据所携带的信息量,信息熵冗余指数据所携带的信息量少于数据本身而反映出来的数据冗余。
- 5、结构冗余。在有些图像的纹理区,图像的像素值存在着明显的分布模式。
- 6、知识冗余。有许多图像的理解与某些先验知识有相当大的相关性。这类规律性的结构可由先验知识和背景知识得到,称此类冗余为知识冗余
常用压缩编码方法的分类
编码器中的关键技术
- 预测:通过帧内预测和帧间预测降低视频图像的空间冗余和时间冗余。
- 变换:通过从时域到频域的变换,去除相邻数据之间的相关性,即去除空间冗余。
- 量化:通过用更粗糙的数据表示精细的数据来降低编码的数据量,或者通过去除人眼不敏感的信息来降低编码数据量。
- 熵编码:根据待编码数据的概率特性减少编码冗余。
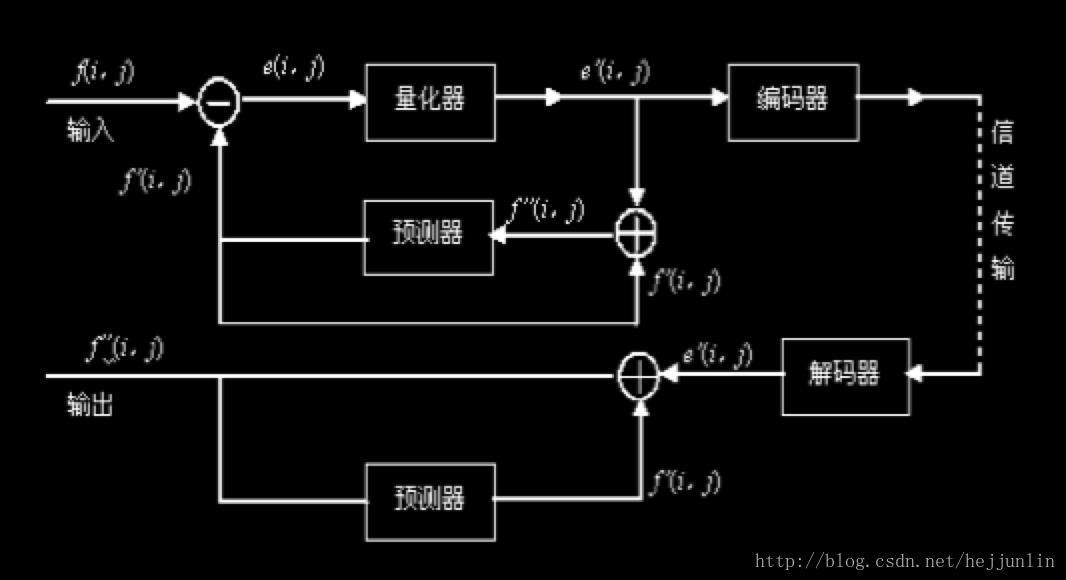
预测:
空间预测:利用图像空间相邻像素的相关性来预测的方法
- 帧内预测技术:利用当前编码块周围已经重构出来的像素预测当前块
Intra图像编码(I帧)
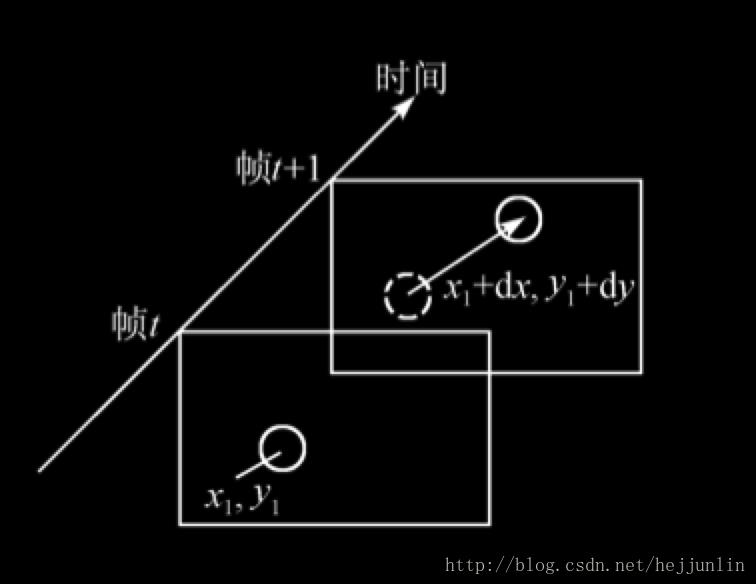
时间预测:利用时间上相邻图像的相关性来预测的方法
- 帧间预测:运动估计(Motion Estimation,ME),运动补偿(Motion Compensation,MC)
Inter图像编码:前向预测编码图像(P帧),双向预测编码图像(B帧)
帧间预测编码:
- 采用预测编码方法消除序列图像在时间上的相关性,传送前后两帧的对应像素之间的差值,这称为帧间预测。
帧内预测编码:
- I帧图像的每个宏块都采用帧内(Intra)预测编码模式。
- 宏块分成8x8或者4x4块,对每个块采用帧内预测编码,称作Intra8x8或者Intra4x4。
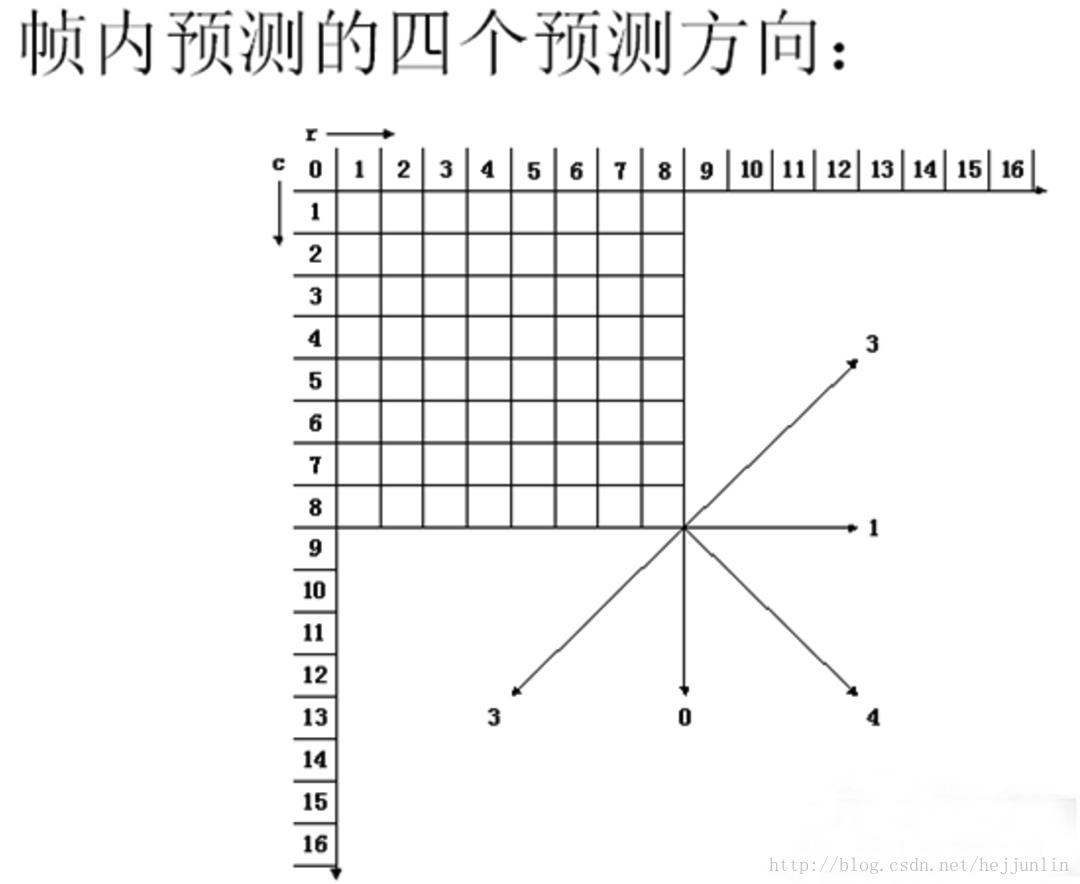
- 帧内预测有多个预测方向:水平,垂直,左下,右上。
- 帧内预测还有直流(DC)预测。
- 色度块预测还有平面预测。
变换:
变换编码也是去除冗余的一种最基本的编码方法。不同的是变换编码首先要把压缩的数据变换到某个变换域中(如频域),然后再进行编码。变化域中表现为能量集中在某个区域,可以利用这一特点在不同区域间有效地分配量化比特数,或者去掉那些能量很小的区域,从而达到数据压缩的目的。例如声音信号,从时域变换到频域以后,可以清楚的看到能量集中在哪些频率范围内,从而根据频率范围分布有效地分配不同的量化位数。
量化:
量化操作实质上是将连续的模拟信号采样得到的瞬时幅度值映射成离散的数字信号,即用一组规定的电平,把瞬时抽样值用最接近的电平值来表示。
量化位数:量化位数是每个采样点能够表示的数据范围,常用的有8位、12位和16位。
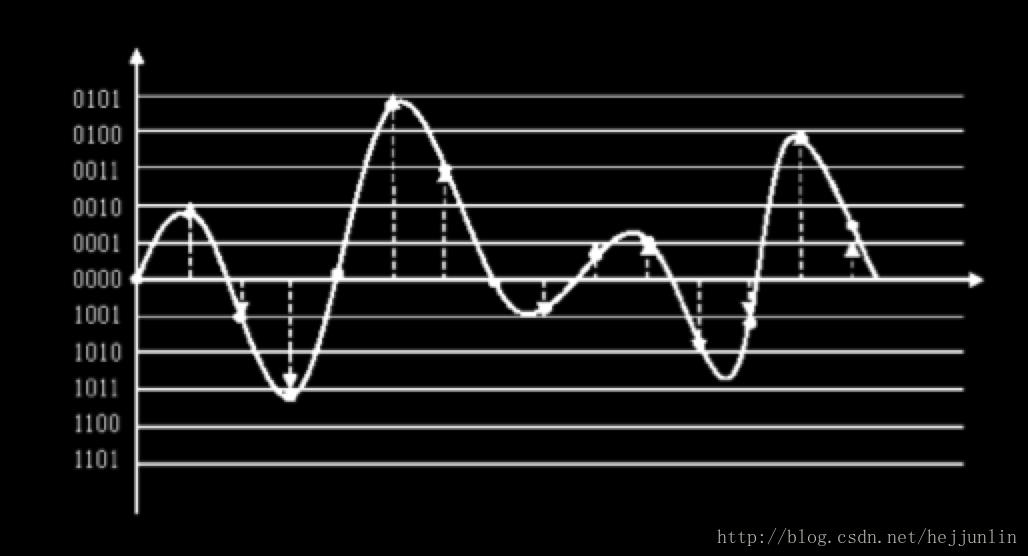
量化过程是,先将整个幅值划分为有限个小幅度(量化阶距)的集合,把落入某个阶距内的样值归为一类,并赋予相同的量化值,如图所示,其中虚线箭头表示采样值量化后的电平值。
均匀量化
- 采用相等的量化间隔对采样得到的信号做量化就是均匀量化,也称为线性量化。量化后的样本值Y和实际值X的差E=Y-X称为量化误差或量化噪声。
非均匀量化
- 非均匀量化的基本思想是,对输入信号进行量化时,大的输入信号采用大的量化间隔,小的输入信号采用小的量化间隔,这样就可以在满足精度要求的情况下用较少的位数来表示。声音数据还原时,采用相同的规则。
熵编码:
为了进一步压缩数据,对DPCM编码后的直流系数DC和RLE编码后的交流系数AC采用熵编码。在JPEG有损压缩算法中,使用哈夫曼编码器的理由是可以使用很简单的查表方法进行编码。压缩数据符号时,哈夫曼编码器对出现频率比较高的符号分配比较短的代码,而对出现频率低的符号分配比较长的代码。这种可变长度的哈夫曼编码表可以事先进行定义。为了实现正确解码,发送端和接收端必须采用相同的哈夫曼编码表。
采用哈夫曼编码时有两个问题值得注意:
- 哈夫曼编码没有错误保护功能。在译码时,如果某些位出现错误,会引起一连串的错误,造成错误传播(Error Propagation )。计算机对这种错误也无能为力,说不出错在哪里,更谈不上去纠正它。
哈夫曼编码是可变长度码,因此很难随意查找或调用压缩文件中的内容,然后再译码,这就需要在存储代码之前加以考虑。尽管如此,哈夫曼编码还是得到了广泛的应用。
该算法基于一种称为编码树的技术,其步骤如下:
(1)将待编码的N个信源符号按照出现的概率由大到小 排列,给排在最后的两个符号各分配一位二进制码元,对其中概率大的符号分配0,概率小的符号分配1(反之亦可)。
(2)把概率最小的两个符号概率相加,求出的和作为一个新符号的概率,将新的概率值与剩下的N-2个概率值一起重新进行排序,再重复步骤(1)的编码过程。
(3)重复步骤(2)直到只剩一个概率值为止,其值为1。
(4)分配码字,对于各种信源符号,基于步骤(1)分配的数字,从编码树的根部开始回溯读出,并将它作为该符号对应分配的码字。
例 设有离散无记忆信源,符号a1、a2、a3、a4、a5、a6的出现概率分别为0.12、0.08、0.4、0.1、0.25、0.05,其哈夫曼编码过程如下:

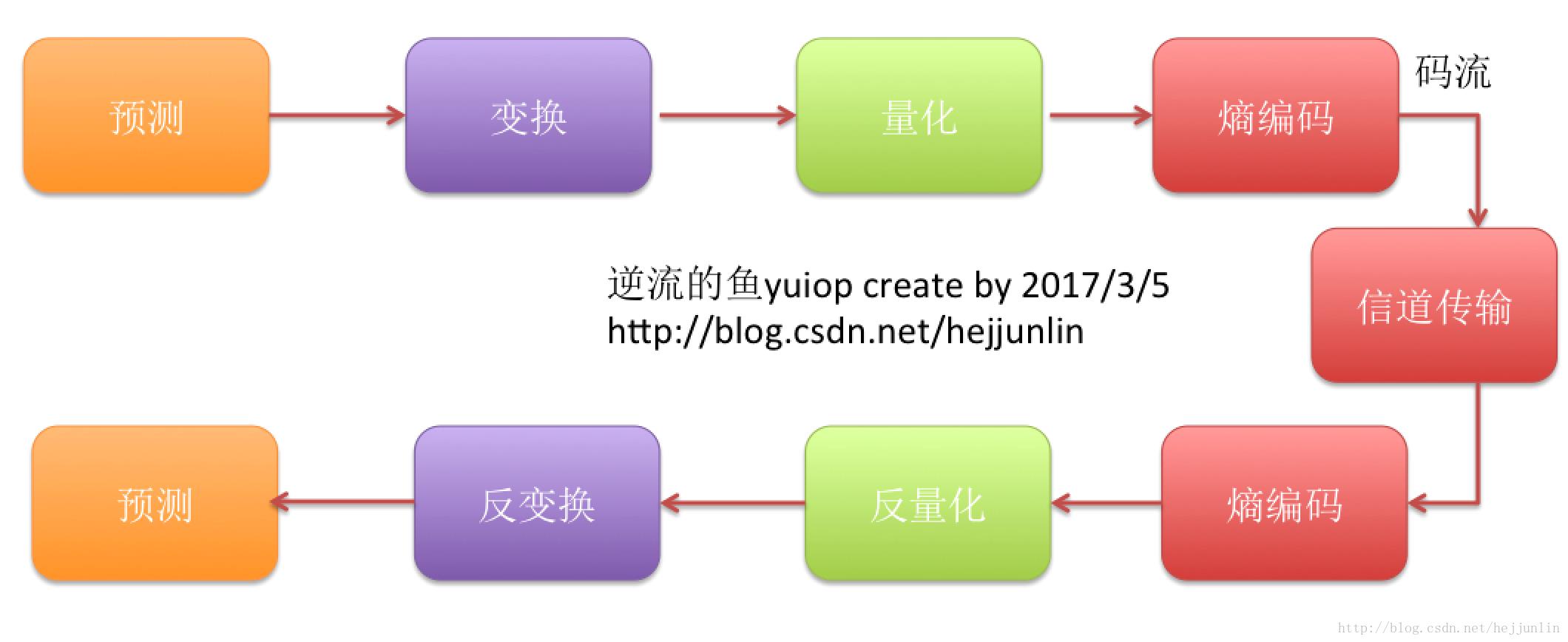
编解码总体情况:
第一时间获得博客更新提醒,以及更多android干货,源码分析,欢迎关注我的微信公众号,扫一扫下方二维码或者长按识别二维码,即可关注。

以上是关于直播技术总结音视频数据压缩及编解码基础的主要内容,如果未能解决你的问题,请参考以下文章