图像压缩基本原理
Posted 悠悠南山下
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图像压缩基本原理相关的知识,希望对你有一定的参考价值。
信息论一些基础
自信息I(s)
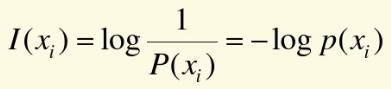

信息熵H(s)
在信源中,考虑的不是某一单个符号发生的不确定性,而是要考虑这个信源所有可能发生情况的平均不确定性。若信源符号有n种取值:U1…Ui…Un,对应概率为:P1…Pi…Pn,且各种符号的出现彼此独立。这时,信源的平均不确定性应当为单个符号不确定性-logPi的统计平均值(E),可称为信息熵,即
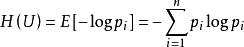
式中对数一般取2为底,单位为比特
香农采样定理
香农第一定理(可变长无失真信源编码定理)
设离散无记忆信源X包含N个符号{x1,x2,…,xi,..,xN},信源发出K重符号序列,则此信源可发出N^k个不同的符号序列消息,其中第j个符号序列消息的出现概率为PKj,其信源编码后所得的二进制代码组长度为Bj,代码组的平均长度B为
B=PK1B1+PK2B2+…+PKN^kBN^k
当K趋于无限大时,B和信息量H(X)之间的关系为B*K=H(X)(K趋近无穷)
香农第一定理又称为无失真信源编码定理或变长码信源编码定理。
香农第一定理的意义:将原始信源符号转化为新的码符号,使码符号尽量服从等概分布,从而每个码符号所携带的信息量达到最大,进而可以用尽量少的码符号传输信源信息。
香农第二定理(有噪信道编码定理)
有噪信道编码定理。当信道的信息传输率不超过信道容量时,采用合适的信道编码方法可以实现任意高的传输可靠性,但若信息传输率超过了信道容量,就不可能实现可靠的传输。
设某信道有r个输入符号,s个输出符号,信道容量为C,当信道的信息传输率R<C,码长N足够长时,总可以在输入的集合中(含有r^N个长度为N的码符号序列),找到M ((M<=2^(N(C-a))),a为任意小的正数)个码字,分别代表M个等可能性的消息,组成一个码以及相应的译码规则,使信道输出端的最小平均错误译码概率Pmin达到任意小。
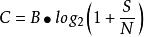
注:B为信道带宽;S/N为信噪比,通常用分贝(dB)表示。
香农第三定理(保失真度准则下的有失真信源编码定理)
保真度准则下的信源编码定理,或称有损信源编码定理。只要码长足够长,总可以找到一种信源编码,使编码后的信息传输率略大于率失真函数,而码的平均失真度不大于给定的允许失真度,即D\'<=D.
设R(D)为一离散无记忆信源的信息率失真函数,并且选定有限的失真函数,对于任意允许平均失真度D>=0,和任意小的a>0,以及任意足够长的码长N,则一定存在一种信源编码W,其码字个数为M<=EXP{N[R(D)+a]},而编码后码的平均失真度D\'(W)<=D+a。
行程编码
RLE(Run LengthEncoding行程编码)算法是一个简单高效的无损数据压缩算法,其基本思路是把数据看成一个线性序列,而这些数据序列组织方式分成两种情况:一种是连续的重复数据块,另一种是连续的不重复数据块。对于连续的重复数据快采用的压缩策略是用一个字节(我们称之为数据重数属性)表示数据块重复的次数,然后在这个数据重数属性字节后面存储对应的数据字节本身,例如某一个文件有如下的数据序列AAAAA,在未压缩之前占用5个字节,而如果使用了压缩之后就变成了5A,只占用两个字节,对于连续不重复的数据序列,表示方法和连续的重复数据块序列的表示方法一样,只不过前面的数据重数属性字节的内容为1。一般的这里的数据块取一个字节,这篇文章中数据块都默认为一个字节。为了更形象的说明RLE算法的原理我们给出最原始的RLE算法:
给出的数据序列为:A-A-A-A-A-B-B-C-D
未压缩前:A-A-A-A-A-B-B-C-D
(0x41-0x41-0x41-0x41-0x41-0x42-0x42-0x43-0x44)
压缩后:5-A-2-B-1-C-1-D
(0x05-0x41-0x02-0x42-0x01-0x43-0x01-0x44)
霍夫曼编码
霍夫曼编码使用变长编码表对源符号(如文件中的一个字母)进行编码,其中变长编码表是通过一种评估来源符号出现机率的方法得到的,出现机率高的字母使用较短的编码,反之出现机率低的则使用较长的编码,这便使编码之后的字符串的平均长度、期望值降低,从而达到无损压缩数据的目的。
算数编码
术编码用到两个基本的参数:符号的概率和它的编码间隔。信源符号的概率决定压缩编码的效率,也决定编码过程中信源符号的间隔,而这些间隔包含在0到1之间。编码过程中的间隔决定了符号压缩后的输出。
给定事件序列的算术编码步骤如下:
(1)编码器在开始时将“当前间隔” [ L, H) 设置为[0,1)。
(2)对每一事件,编码器按步骤(a)和(b)进行处理
(a)编码器将“当前间隔”分为子间隔,每一个事件一个。
(b)一个子间隔的大小与下一个将出现的事件的概率成比例,编码器选择子间隔对应于下一个确切发生的事件相对应,并使它成为新的“当前间隔”。
(3)最后输出的“当前间隔”的下边界就是该给定事件序列的算术编码。
设Low和High分别表示“当前间隔”的下边界和上边界,CodeRange为编码间隔的长度,LowRange(symbol)和HighRange(symbol)分别代表为了事件symbol分配的初始间隔下边界和上边界。上述过程的实现可用伪代码描述如下:
set Low to 0
set High to 1
while there are input symbols do
take a symbol
CodeRange = High – Low
High = Low + CodeRange *HighRange(symbol)
Low = Low + CodeRange * LowRange(symbol)
end of while
output Low
算术码解码过程用伪代码描述如下:
get encoded number
do
find symbol whose range straddles the encoded number
output the symbol
range = symbo.LowValue – symbol.HighValue
substracti symbol.LowValue from encoded number
divide encoded number by range
until no more symbols
词典编码
LZW算法
LZW算法先将可能的信源符号,创建一个初始词典,然后再编码过程中,遇到词典中没有的短语就加到词典中,动态创建词典。
参考:
预测编码
帧内预测
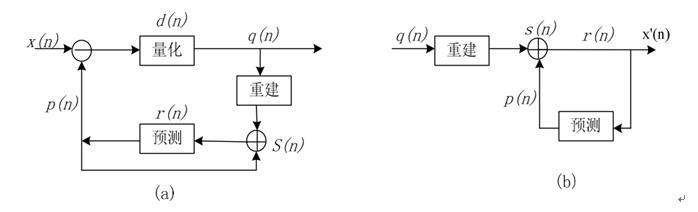
预测编码的思路简单来说就是指编码实际值与预测值之间的差别,通过预测其对当数据块进行预测(与前面的数据有关),之后与真实值做差,将差值进行编码。在重建数据时,需要采取相同的预测器预测当前数据,与差值求和即可得到真实值。
线性预测
非线性预测
差分脉冲调制编码(DPCM)
 帧间预测编码
帧间预测编码运动估计ME
运动估计就是寻找当前编码块在已编码图像(或参考帧)中的最佳对应块,并且计算出对应块的偏移(即运动矢量)。
运动补偿MC
运动补偿则是根据运动矢量和帧间预测方法,求得当前帧的估计值的过程。它是对当前图像的描述,旨在说明当前图像的每一块像素如何由其参考图像的像素块得到。
运动补偿预测编码
对于运动的物体,估计出物体在相邻帧内的相对位移,用上一帧中物体的图像对这一帧的物体进行预测,将预测的差值部分编码传输,就可以压缩着部分的码率。包括以下4个部分:
1.图像区域划分,划分为静止区域和运动区域
2.运动估计。对每一个运动物体进行位移估计
3.运动补偿。由位移的估计值建立同一个运动物体在不同帧的空间位置对应关系,从而尽力预测关系。
4.补偿后的预测信息编码。对运动物体的补偿后的位移帧差信号以及运动矢量等进行编码传输
运动估计算法
像素递归法:根据像素间亮度的变化和梯度,通过递归修正的方法来估计每个像素的运动矢量。每个像素都有一个运动矢量与之对应。
块匹配算法:
(1)分块匹配算法
一种基于模板的匹配方法。
(2)快速搜索算法
全局搜索算法(full search,FS)是最简单和细致的搜索算法,它在搜索区内搜索每一个点,然后找到误差最小的点。
三步搜索法(three step search,TSS):基本思想是采用由粗到细的搜索模式。
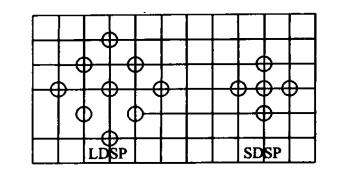
钻石搜索法(diamond search,DS):选用两种形状的搜索模板,分别是9个检测点的大钻石模板(LDSP)和5个检测点的小钻石模板(SDSP),先进行大模板搜索,再用小模板定位
匹配标准

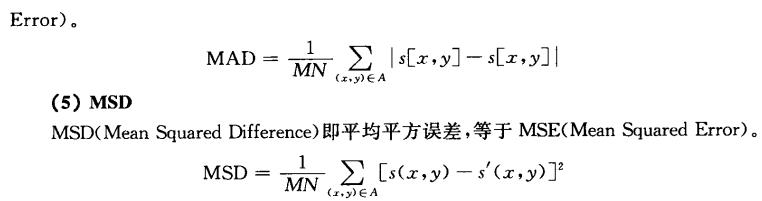
变换编码
指对信号的样本值进行某种形式的函数变换,从一种空间变换到另一种空间,然后再根据信号在另一个空间域的特征来对信号进行编码压缩。
K-L变换(均方误差准则下最佳变换)
指图像信号中各像素间存在的相关性完全解除的正交变换
离散傅里叶变换(DFT)
建立以时间为自变量的信号与以频率为自变量的频谱函数之间的变换关系
离散余弦变换(DCT)
量化
标量量化:均衡量化、非均衡量化和自适应量化
矢量量化:一次量化多个采样点的量化方法,即将输入数据几个一组分成许多组,成组进行量化编码
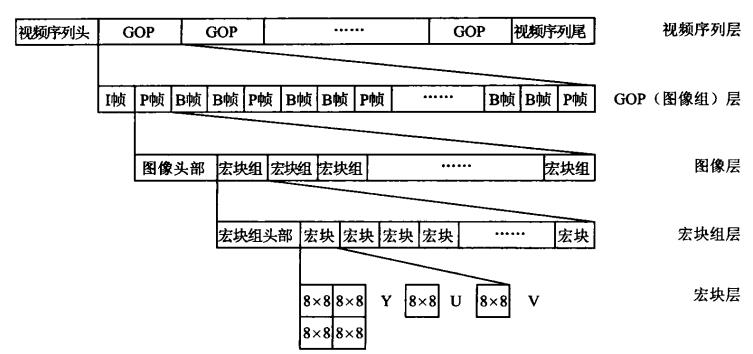
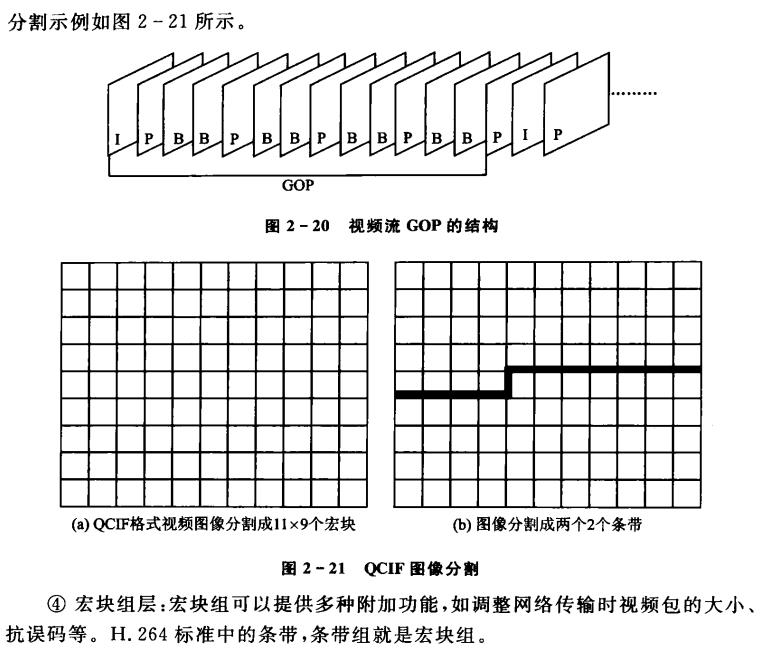
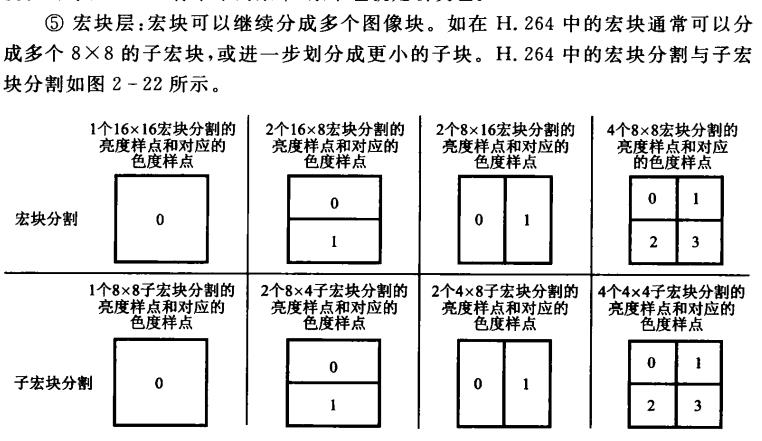
视频数据组织结构

以上是关于图像压缩基本原理的主要内容,如果未能解决你的问题,请参考以下文章