ZooKeeper源码学习笔记--Cluster模式下的ZooKeeper
Posted Kifile
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ZooKeeper源码学习笔记--Cluster模式下的ZooKeeper相关的知识,希望对你有一定的参考价值。
Cluster集群模式
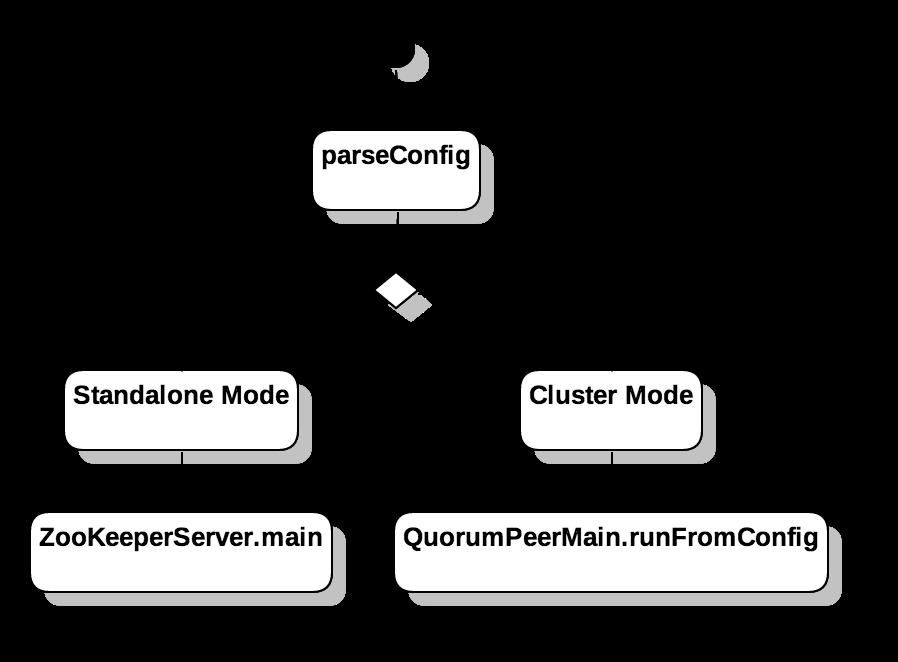
前一篇文章 介绍了当配置文件中只有一个server地址时,Standalone模式的启动流程以及ZooKeeper的节点模型和运行逻辑。在本节中,我会针对Cluster的运行模式进行详细讲解。
启动流程
public synchronized void start() {
loadDataBase();
cnxnFactory.start();
startLeaderElection();
super.start();
}QuorumPeerMain::runFromConfig会构造一个QuorumPeer对象,并调用start方法启动整个Server。
QuorumPeer::start经过了三个步骤:
- 通过
loadDatabase将磁盘中的Snapshot和TxnLog加载到内存中,构造一个DataTree对象 - 启动一个
ServerCnxnFactory对象,默认启动一个Daemon线程运行NioserverCnxnFactory,负责接收来自各个Client端的指令。 - 启动选举过程
前两步在Standalone的启动模式也有出现,我们不再做过多介绍,需要的朋友可以看一看前面的文章。在这里,我们需要留意第三步。
第三步的名字叫做startLeaderElection, 看到这个名字,我的第一反应是他会启动一个独立线程去负责Leader的选举,但其实不然。通过源码走读,我们看到startLeaderElection中其实只是对选举做了初始化设定,真正的选举线程其实是在QuorumPeer这个线程类中启动的。
选举算法我在这里先不做过多介绍,这会是一个独立的文章,放在下一篇进行讲解,让我们先看一下选举之后的状态。
ZooKeeper Server的三种状态
Cluster模式顾名思义是由多个server节点组成的一个集群,在集群中存在一个唯一的leader节点负责维护节点信息,其他节点只负责接收转发Client请求,或者更甚,只是监听Leader的变化状态。
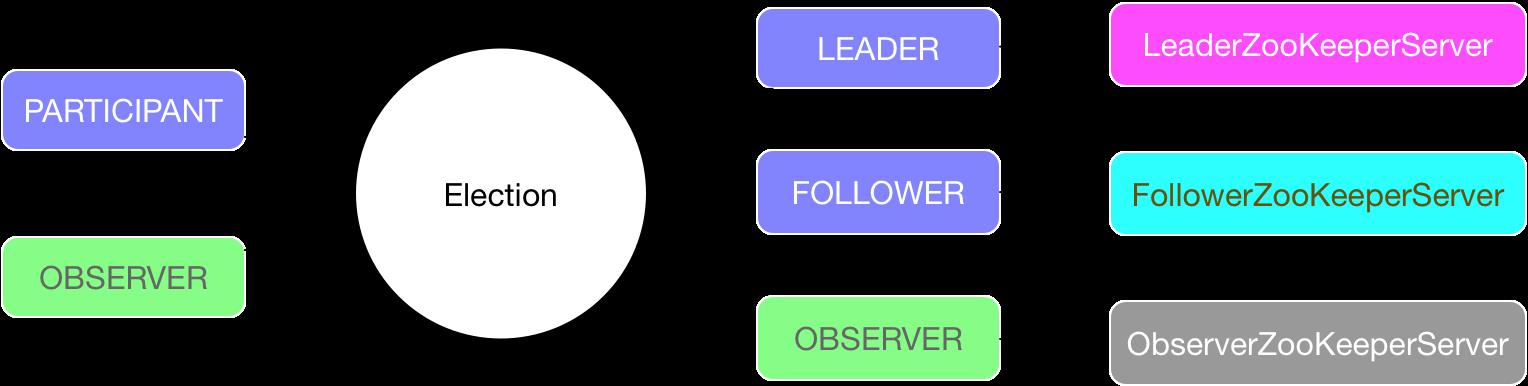
在配置文件中,我们可以通过peerType对当前节点类型进行配置。目前支持两种类型:
PARTICIPANT: participant 具有选举权和被选举权,可以被选举成为Leader,如果未能成功被选举,则成为Follower。OBSERVER: observer只具备选举权,他可以投票选举Leader,但是他本身只能够成为observer监听leader的变化。
选举完成之后,节点从PARTICIPANT和OBSERVER两种状态变成了LEADER,FOLLOWER和OBSERVER三种状态,每种状态对应一个ZooKeeperServer子类。
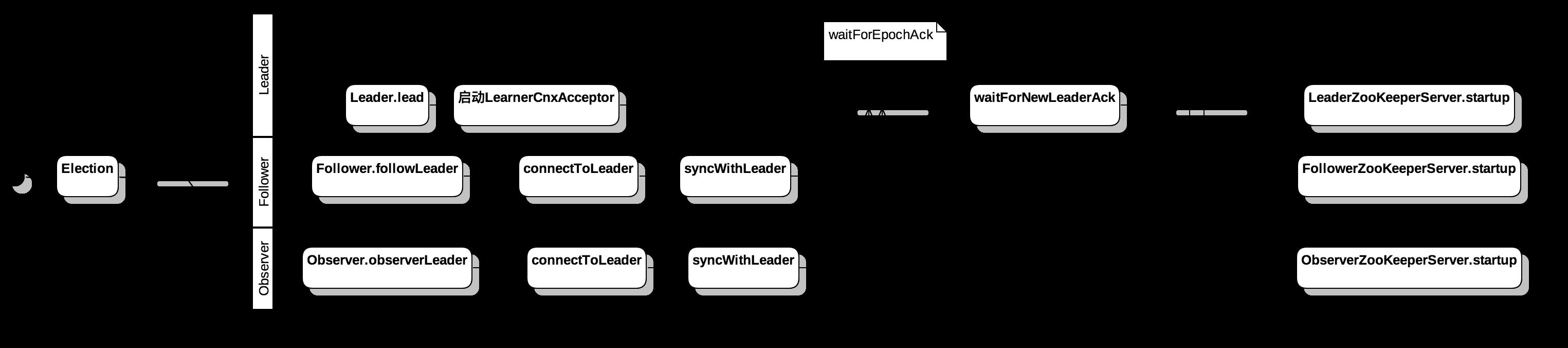
选举结束之后,三种类型的节点根据自身的类型进入启动流程,启动对应的ZooKeeperServer。
- Leader 作为整个集群中的主节点,会启动一个
LearnerCnxAcceptor的线程负责同其他节点进行通信。 - Follower和Observer的大致逻辑类似,首先通过配置信息连接上Leader节点,再向Leader节点发送ACK请求,告知链接成功。
- 当Leader中检测到大部分的Follower都已经成功链接到Leader之前,socket访问会被阻塞;直到检测到大部分Follower链接上之后,才退出阻塞状态,令
Leader,Follower和Observer启动对应的ZooKeeperServer。
维护节点的一致性
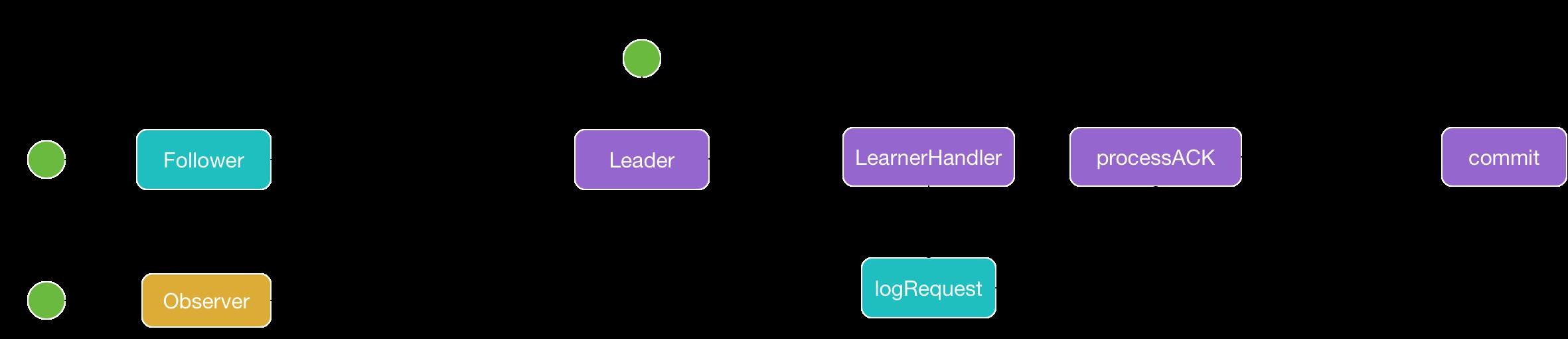
上图中使用黄色的节点表示 Observer 上的操作,蓝色的节点表示 Follower 中的操作,紫色的节点表示 Leader 上的操作。
如图所示,不论是Follower还是Observer在接受到Request请求后,都通过一个RequestProcessor将请求分发给Leader进行处理。单节点的处理逻辑能够保证数据在各个节点是一致的。
在Leader中,通过proposal方法将需要提交的Request加入 outstandingProposals 队列。
每个Follower或者Observer同Leader建立链接之后会创建一个LearnerHandler线程,对于Follower类型的LearnerHandler,在线程的循环中,会将outstandingProposals中的Request请求分发回对应的Follower 进行消费,消费完毕后,再通过 SendAckRequestProcessor 发回 Leader 。
在 Leader 的任务链中存在一个AckRequestProcessor节点,监听Follower 响应的结果,当大部分Follower都响应了某次提交之后,会认为该提交有效,再通过 CommitProcessor 正式提交到内存中。
LeaderZooKeeperServer

和Standalone模式的ZooKeeperServer一样,在LeaderZooKeeperServer中也是通过一个RequestProcessor任务链处理来自Client的请求。
- PrepRequestProcessor: 在outstandingChanges中创建临时节点,便于后续请求快速访问,详细解析请参看上一篇文章
- ProposalRequestProcessor: 在Proposal的构造方法中,会传入一个RequestProcessor对象,同时他自身也会构造一个包裹了
ACKRequestProcessor的SyncRequestProcessor对象。如上图所示,ProposalRequestProcessor在nextProcessor消费了Request之后,还会使用SyncReqeustProcessor进行二次消费,这使得任务在这个节点产生了两个分支。 - CommitProcessor: 本节点运行在一个独立线程中,每一次轮询都会将
queuedRequests中的请求信息加入toProcess队列中,然后在轮询的开始处,对toProcess队列进行批量处理。在方法内部有一个局部变量nextPending保存从queuedRequests取出的最后一个Request请求,如果nextPending迟迟没有被提交,则进入等待的逻辑,与此同时,queuedRequests会一直积累请求信息,直到nextPending的请求通过CommitProcessor::commit被提交到committedRequests中,才能够退出等待逻辑,批量消费queuedRequests中的请求数据。 - ToBeAppliedRequestProcessor:调用FinalRequestProcessor进行处理,并将请求从
toBeApplied队列中移除。 - FinalRequestProcessor:将请求信息合并到
DataTree中,具体操作见前一篇文章 - SyncRequestProcessor: 如上一节所说,在
SyncRequestProcessor中会将Request请求封装成一个Transaction,并写入 TxnLog, 同时定期备份 Snapshot。 - ACKRequestProcessor: 在这个节点中,通过执行
leader:processAck检查满足条件的request请求,调用CommitProcessor::commit将满足响应条件的Request提交给CommitProcessor处理。
FollowerZooKeeperServer
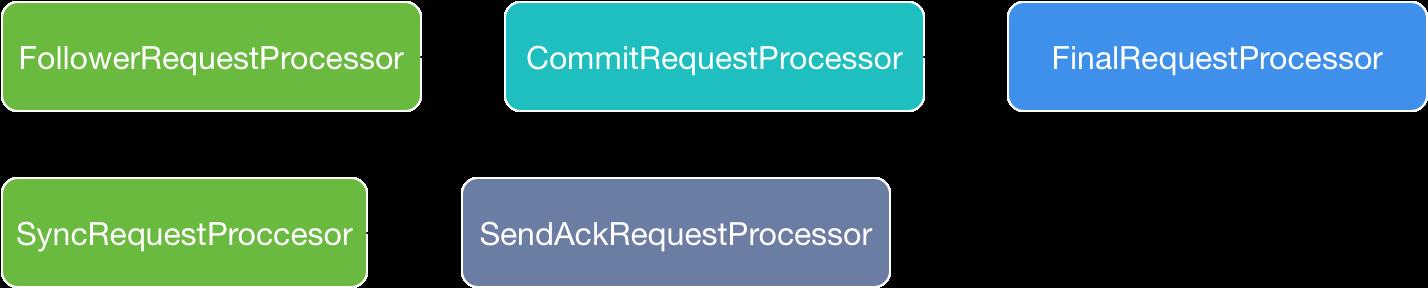
如图,和之前的任务链不同,在FollowerZooKeeperServer中同时存在两个并行的任务链处理。
第一个任务链负责将Follower接受到的Request请求分发给 Leader
第二个任务链通过接收 Leader 转发来的 Request 请求,当数据被同步到 disk 之后,通过 SendAckRequestProcessor 将接收结果反馈给 Leader。
ObserverZooKeeperServer

Observer 中的任务结构和 Follower中的第一个任务链很相似。都是负责把接收到的 Request 请求转发给 Leader。
集群间的交互
节点心跳
Leader::lead() 中有一个 while 循环负责维持 Leader 和其他节点之间的心跳关系。
while (true) {
Thread.sleep(self.tickTime / 2);
for (LearnerHandler f : getLearners()) {
f.ping();
}
if (!tickSkip && !self.getQuorumVerifier().containsQuorum(syncedSet)) {
shutdown("Not sufficient followers synced, only synced with sids: [ " + getSidSetString(syncedSet) + " ]");
return;
}
}可以看到,在 while 循环中,每个tick周期中会触发两次心跳。
每次心跳都是由 Leader 主动发送给各个节点,节点中也存在一个while 循环读取socket 中的信息。
while (this.isRunning()) {
readPacket(qp);
processPacket(qp);
}processPacket中,会处理接收到的 QuorumPacket 对象,当接受到心跳信息 PING 时,同Leader进行一次socket交互,告知存活。
sync 同步
Client 可以通过API接口发送一个sync信号给集群中的任意节点。 不论Leader 是直接或是间接接收到 sync 信号,都会将这个信号通过集群内部的 socket 链接分发给各个节点。
当Follower或者Observer 接收到集群广播的 sync 信号时,会在内部调用 commit 方法,确保 CommitProcessor 能够调用 FinalRequestProcessor 将Transaction Log 合并到 DataTree 中。
Leader异常的重新选主
如果因为 Leader 异常导致集群中的其他节点无法正常访问Leader,则会重新进入选主的流程。
我们在 QuorumPeer 中看到,不论是 Leader , Follower 还是 Observer 他们在出现异常之后,都会 setPeerState(ServerState.LOOKING),从而进入选主流程。
总结
ZooKeeper 的 Cluster 模式中,允许我们同时启动多个 ZooKeeper 服务。 在整个集群中会选出一个Leader Server 负责整个节点的维护。
Follower 和 Observer 会将自己接收到的 Request 分发给 Leader 进行消费,在Leader 中会通过内部广播将请求信息通知回Follower。
Cluster 模式和 Standalone 模式在节点模型方面没有什么区别,主要就是在RequestProcessor的任务链逻辑更加复杂,需要通过ProposalRequestProcessor将数据分发给集群中的Follower,当大多数Follower都认可记录后,才将Transaction Log 同步到 DataTree 中,他的处理细节会更加的复杂。
以上是关于ZooKeeper源码学习笔记--Cluster模式下的ZooKeeper的主要内容,如果未能解决你的问题,请参考以下文章
Redis学习笔记35——Codis VS Redis Cluster:我该选择哪一个集群方案?
Redis学习笔记35——Codis VS Redis Cluster:我该选择哪一个集群方案?