Spark和Hive的整合
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark和Hive的整合相关的知识,希望对你有一定的参考价值。
Spark和Hive的整合
node1 spark master
node2 hive 的服务端-->metastore server
1.拷贝 hive-site.xml 到 spark master的 conf 下
node1
<configuration><property><name>hive.metastore.uris</name><value>thrift://node2:9083</value><description>Thrift uri for the remote metastore.Used by metastore client to connect to remote metastore.</description></property></configuration>

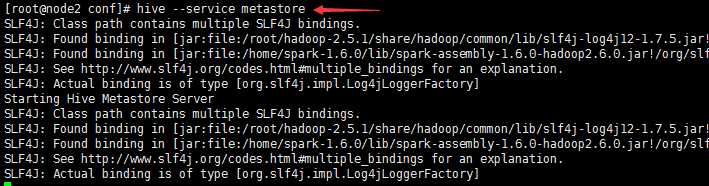
2.开启hive的元数据服务
node2 hive --service metastore
3.启动HDFS和Spark集群
因为hive中源数据是在hdfs上的,所以需要启动hdfs
启动zookeeper
zkServer.sh start
启动hdfs
start-all.sh
启动spark集群
spark-start-all.sh
4.测试
进入node1spark中bin下启动 spark-shell
spark-shell --master spark://node1:7077 --executor-memory 1G
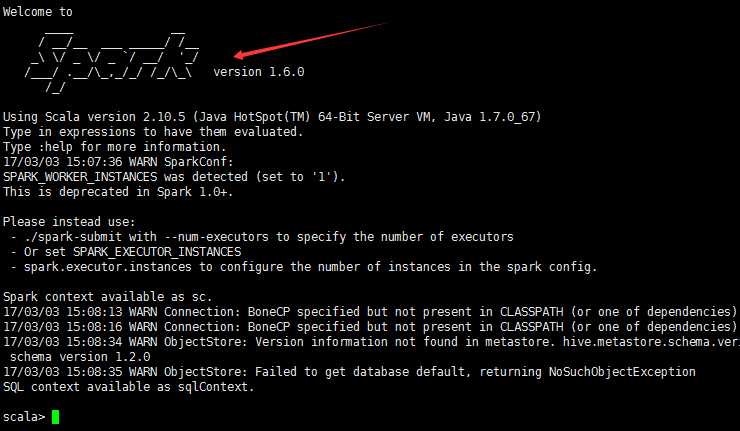
先导入HiveContext的包
scala>import org.apache.spark.sql.hive.HiveContext

scala> val hiveContext = new HiveContext(sc)


scala> hiveContext.sql("show tables").show
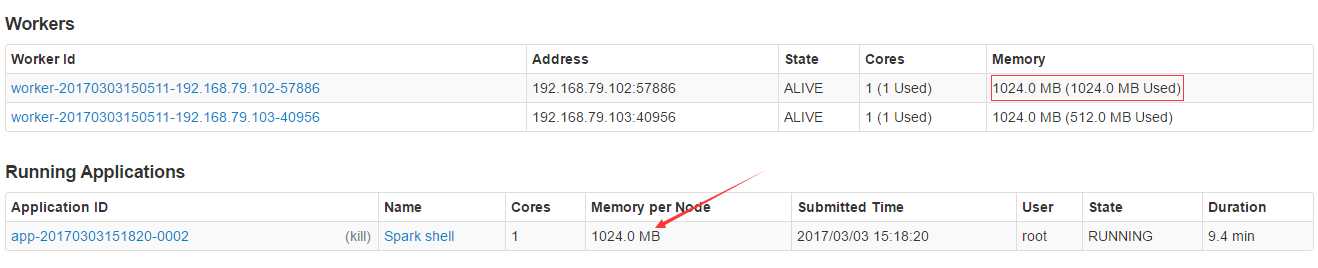
这一步可能会出现资源问题!

出错原因:确保每个节点有足够的资源,因为一开始启动spark shell的时候指定--executor-memory 1G,表明每个executor进程需要1G的资源,但是实际运行时master不能为executor分配足够的资源,所以就报了如上的错误。
解决办法:
在web端把其他无关的Applications kill(Application ID下方有kill)掉即可
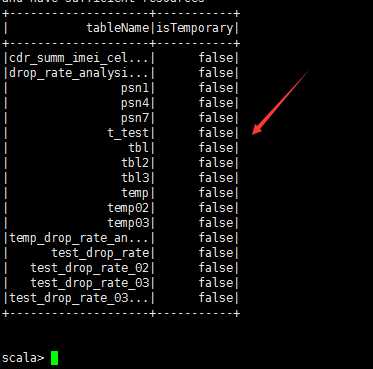
出现如下结果,表明Spark和hive整合ok
如果看不到打印信息,在spark shell 中设置
scala>:sc.setSetLogLevel(INFO)
以上是关于Spark和Hive的整合的主要内容,如果未能解决你的问题,请参考以下文章