机器学习实战Ch03: 决策树
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习实战Ch03: 决策树相关的知识,希望对你有一定的参考价值。
相比kNN的无脑比较相似度,我们需要一种能够较清晰地给出数据内在含义的分类器。
这一章给出了“决策树”这种选择,这一概念本身不难理解,问题在于 在树的每一层如何划分数据集能达到最好的效果
(书中选用的是ID3算法,虽然不是很理解这个名字,但算法本身不是很难理解)
这里的效果,我们引入信息熵这个概念进行衡量
对于一个数据集中的各个标签特征xi,我们给出该类别信息熵的公式
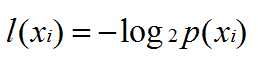
那么相应的按概率为权重,对数据集计算其信息熵
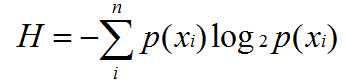
而对于整个数据集而言,其信息熵是分类特征yi取到的概率p(yi)*H(subDataSet(yi))
其中subDataSet(yi)为dataSet中分类特征对应为yi的子数据集
简单来讲,一个数据集划分后的信息熵为
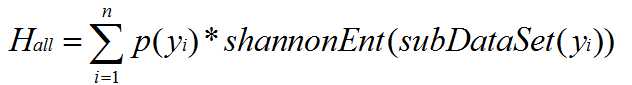
然后我们开始构建决策树的第一步,寻找当前最佳的划分标准
1 def chooseBestFeatureToSplit(dataSet): 2 numFeatures = len(dataSet[0]) - 1 3 baseEntropy = calcShannonEnt(dataSet) 4 bestInfoGain = 0.0 5 bestFeature = -1 6 for i in range(numFeatures): 7 #利用推导式提取出dataSet的第i列特征值 8 featList = [example[i] for example in dataSet] 9 uniqueVals = set(featList) 10 newEntropy = 0.0 11 for value in uniqueVals: 12 subDataSet = splitDataSet(dataSet, i, value) 13 prob = len(subDataSet)/float(len(dataSet)) 14 newEntropy += prob * calcShannonEnt(subDataSet) 15 #比较信息熵的差值,取信息熵下降效果最明显的特征 16 infoGain = baseEntropy - newEntropy 17 if (infoGain > bestInfoGain): 18 bestInfoGain = infoGain 19 bestFeature = i 20 return bestFeature
构建决策树本身的代码并不难理解,只是简单的递归实现
但用字典储存树这种奇技淫巧,可以学习一下
1 def createTree(dataSet,labels): 2 classList = [example[-1] for example in dataSet] 3 if (classList.count(classList[0]) == len(classList)): return classList[0] 4 if (len(dataSet[0]) == 1): return majorityCnt(classList) 5 bestFeat = chooseBestFeatureToSplit(dataSet) 6 bestFeatLabel = labels[bestFeat] 7 myTree = {bestFeatLabel:{}} 8 del(labels[bestFeat]) 9 featValues = [example[bestFeat] for example in dataSet] 10 uniqueVals = set(featValues) 11 for value in uniqueVals: 12 subLabels = labels[:] 13 myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value),subLabels) 14 return myTree
注意一下3,4行对应的两种特殊情况
1)标签特征在该子数据集中已经清一色了,没有继续划分的必要了
2)已经用所有特征划分过了数据集,标签特征却还是不是清一色,启动投票机制(少数服从多数)
用pyplot绘制树我决定还是先放着...
好麻烦啊orz
mark一下以后补上
以上是关于机器学习实战Ch03: 决策树的主要内容,如果未能解决你的问题,请参考以下文章