TreeSet源码解析笔记
Posted 断剑重铸之时
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TreeSet源码解析笔记相关的知识,希望对你有一定的参考价值。
定义:
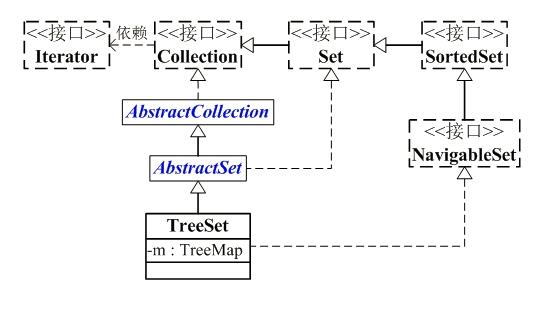
TreeSet是一个有序的集合,它的作用是提供有序的Set集合。它继承了AbstractSet抽象类,实现了NavigableSet<E>,Cloneable,Serializable接口。TreeSet是基于TreeMap实现的,TreeSet的元素支持2种排序方式:自然排序或者根据提供的Comparator进行排序。
TreeSet的接口依赖图:
package java.util;
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable
{
// 使用NavigableMap对象的key来保存Set集合的元素
private transient NavigableMap<E,Object> m;
//使用PRESENT作为Map集合中的value
private static final Object PRESENT = new Object();
// 不带参数的构造函数。创建一个空的TreeMap
//以自然排序方法创建一个新的TreeMap,再根据该TreeMap创建一个TreeSet
//使用该TreeMap的key来保存Set集合的元素
public TreeSet() {
this(new TreeMap<E,Object>());
}
// 将TreeMap赋值给 "NavigableMap对象m"
TreeSet(NavigableMap<E,Object> m) {
this.m = m;
}
//以定制排序的方式创建一个新的TreeMap。根据该TreeMap创建一个TreeSet
//使用该TreeMap的key来保存set集合的元素
public TreeSet(Comparator<? super E> comparator) {
this(new TreeMap<E,Object>(comparator));
}
// 创建TreeSet,并将集合c中的全部元素都添加到TreeSet中
public TreeSet(Collection<? extends E> c) {
this();
// 将集合c中的元素全部添加到TreeSet中
addAll(c);
}
// 创建TreeSet,并将s中的全部元素都添加到TreeSet中
public TreeSet(SortedSet<E> s) {
this(s.comparator());
addAll(s);
}
// 返回TreeSet的顺序排列的迭代器。
// 因为TreeSet时TreeMap实现的,所以这里实际上时返回TreeMap的“键集”对应的迭代器
public Iterator<E> iterator() {
return m.navigableKeySet().iterator();
}
// 返回TreeSet的逆序排列的迭代器。
// 因为TreeSet时TreeMap实现的,所以这里实际上时返回TreeMap的“键集”对应的迭代器
public Iterator<E> descendingIterator() {
return m.descendingKeySet().iterator();
}
// 返回TreeSet的大小
public int size() {
return m.size();
}
// 返回TreeSet是否为空
public boolean isEmpty() {
return m.isEmpty();
}
// 返回TreeSet是否包含对象(o)
public boolean contains(Object o) {
return m.containsKey(o);
}
// 添加e到TreeSet中
public boolean add(E e) {
return m.put(e, PRESENT)==null;
}
// 删除TreeSet中的对象o
public boolean remove(Object o) {
return m.remove(o)==PRESENT;
}
// 清空TreeSet
public void clear() {
m.clear();
}
// 将集合c中的全部元素添加到TreeSet中
public boolean addAll(Collection<? extends E> c) {
// Use linear-time version if applicable
if (m.size()==0 && c.size() > 0 &&
c instanceof SortedSet &&
m instanceof TreeMap) {
//把C集合强制转换为SortedSet集合
SortedSet<? extends E> set = (SortedSet<? extends E>) c;
//把m集合强制转换为TreeMap集合
TreeMap<E,Object> map = (TreeMap<E, Object>) m;
Comparator<? super E> cc = (Comparator<? super E>) set.comparator();
Comparator<? super E> mc = map.comparator();
//如果cc和mc两个Comparator相等
if (cc==mc || (cc != null && cc.equals(mc))) {
//把Collection中所有元素添加成TreeMap集合的key
map.addAllForTreeSet(set, PRESENT);
return true;
}
}
return super.addAll(c);
}
// 返回子Set,实际上是通过TreeMap的subMap()实现的。
public NavigableSet<E> subSet(E fromElement, boolean fromInclusive,
E toElement, boolean toInclusive) {
return new TreeSet<E>(m.subMap(fromElement, fromInclusive,
toElement, toInclusive));
}
// 返回Set的头部,范围是:从头部到toElement。
// inclusive是是否包含toElement的标志
public NavigableSet<E> headSet(E toElement, boolean inclusive) {
return new TreeSet<E>(m.headMap(toElement, inclusive));
}
// 返回Set的尾部,范围是:从fromElement到结尾。
// inclusive是是否包含fromElement的标志
public NavigableSet<E> tailSet(E fromElement, boolean inclusive) {
return new TreeSet<E>(m.tailMap(fromElement, inclusive));
}
// 返回子Set。范围是:从fromElement(包括)到toElement(不包括)。
public SortedSet<E> subSet(E fromElement, E toElement) {
return subSet(fromElement, true, toElement, false);
}
// 返回Set的头部,范围是:从头部到toElement(不包括)。
public SortedSet<E> headSet(E toElement) {
return headSet(toElement, false);
}
// 返回Set的尾部,范围是:从fromElement到结尾(不包括)。
public SortedSet<E> tailSet(E fromElement) {
return tailSet(fromElement, true);
}
// 返回Set的比较器
public Comparator<? super E> comparator() {
return m.comparator();
}
// 返回Set的第一个元素
public E first() {
return m.firstKey();
}
// 返回Set的最后一个元素
public E first() {
public E last() {
return m.lastKey();
}
// 返回Set中小于e的最大元素
public E lower(E e) {
return m.lowerKey(e);
}
// 返回Set中小于/等于e的最大元素
public E floor(E e) {
return m.floorKey(e);
}
// 返回Set中大于/等于e的最小元素
public E ceiling(E e) {
return m.ceilingKey(e);
}
// 返回Set中大于e的最小元素
public E higher(E e) {
return m.higherKey(e);
}
// 获取第一个元素,并将该元素从TreeMap中删除。
public E pollFirst() {
Map.Entry<E,?> e = m.pollFirstEntry();
return (e == null)? null : e.getKey();
}
// 获取最后一个元素,并将该元素从TreeMap中删除。
public E pollLast() {
Map.Entry<E,?> e = m.pollLastEntry();
return (e == null)? null : e.getKey();
}
// 克隆一个TreeSet,并返回Object对象
public Object clone() {
TreeSet<E> clone = null;
try {
clone = (TreeSet<E>) super.clone();
} catch (CloneNotSupportedException e) {
throw new InternalError();
}
clone.m = new TreeMap<E,Object>(m);
return clone;
}
// java.io.Serializable的写入函数
// 将TreeSet的“比较器、容量,所有的元素值”都写入到输出流中
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
s.defaultWriteObject();
// 写入比较器
s.writeObject(m.comparator());
// 写入容量
s.writeInt(m.size());
// 写入“TreeSet中的每一个元素”
for (Iterator i=m.keySet().iterator(); i.hasNext(); )
s.writeObject(i.next());
}
// java.io.Serializable的读取函数:根据写入方式读出
// 先将TreeSet的“比较器、容量、所有的元素值”依次读出
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
// Read in any hidden stuff
s.defaultReadObject();
// 从输入流中读取TreeSet的“比较器”
Comparator<? super E> c = (Comparator<? super E>) s.readObject();
TreeMap<E,Object> tm;
if (c==null)
tm = new TreeMap<E,Object>();
else
tm = new TreeMap<E,Object>(c);
m = tm;
// 从输入流中读取TreeSet的“容量”
int size = s.readInt();
// 从输入流中读取TreeSet的“全部元素”
tm.readTreeSet(size, s, PRESENT);
}
// TreeSet的序列版本号
private static final long serialVersionUID = -2479143000061671589L;
}
对于TreeMap而言,它采用一种被称为”红黑树”的排序二叉树来保存Map中每个Entry。每个Entry被当成”红黑树”的一个节点来对待。
对于如下代码:
TreeMap<String,Double> map = new TreeMap<String,Double>();
map.put("ccc",89.0);
map.put("aaa",80.0);
map.put("bbb",89.0);
map.put("bbb",89.0);- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
如上代码所示,程序向TreeMap放入四个值。根据”红黑树”的定义,程序会把”ccc,89.0”这个Entry做为该”红黑数”的根节点,然后执行put(“aaa”,”80.0”)时会将其作为新的节点添加到已存在的红黑树中。也就是说,以后每次向TreeMap中放入一个key-value对,系统都需要将Entry当成一个新的节点,添加到存在的”红黑树”中,通过这种方式就可以保证TreeMap中所有的key都是按一定顺序地排列的。
由于TreeMap底层采用一颗”红黑树”来保存集合中的Entry。所以TreeMap添加元素,取出元素的性能都比HashMap低。当TreeMap添加元素时,需要通过循环找到新增的Entry的插入位置,因为比较耗性能。当取出元素时,也需要通过循环才能找到合适的Entry一样比较耗性能。但并不是说TreeMap性能低于HashMap就一无是处,TreeMap中的所有Entry总是按key根据指定的排序规则保持有序状态。
备注:红黑树是一种自平衡二叉查找树 , 它们当中每一个节点的比较值都必须大于或等于在它的左子树中的所有节点,并且小于或等于在它的右子树中的所有节点。这确保红黑树运作时能够快速的在树中查找给定的值。
现在我们来观察TreeMap的put(K key,V value)方法,该方法将Entry放入TreeMap的Entry链,并维护该Entry链的有序状态。下面列出源码:
public V put(K key, V value) {
//定义一个t来保存根元素
Entry<K,V> t = root;
//如果t==null,表明是一个空链表
if (t == null) {
//如果根节点为null,将传入的键值对构造成根节点(根节点没有父节点,所以传入的父节点为null)
root = new Entry<K,V>(key, value, null);
//设置该集合的size为1
size = 1;
//修改此时+1
modCount++;
return null;
}
// 记录比较结果
int cmp;
Entry<K,V> parent;
// 分割比较器和可比较接口的处理
Comparator<? super K> cpr = comparator;
// 有比较器的处理,即采用定制排序
if (cpr != null) {
// do while实现在root为根节点移动寻找传入键值对需要插入的位置
do {
//使用parent上次循环后的t所引用的Entry
// 记录将要被掺入新的键值对将要节点(即新节点的父节点)
parent = t;
// 使用比较器比较父节点和插入键值对的key值的大小
cmp = cpr.compare(key, t.key);
// 插入的key较大
if (cmp < 0)
t = t.left;
// 插入的key较小
else if (cmp > 0)
t = t.right;
// key值相等,替换并返回t节点的value(put方法结束)
else
return t.setValue(value);
} while (t != null);
}
// 没有比较器的处理
else {
// key为null抛出NullPointerException异常
if (key == null)
throw new NullPointerException();
Comparable<? super K> k = (Comparable<? super K>) key;
// 与if中的do while类似,只是比较的方式不同
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
// 没有找到key相同的节点才会有下面的操作
// 根据传入的键值对和找到的“父节点”创建新节点
Entry<K,V> e = new Entry<K,V>(key, value, parent);
// 根据最后一次的判断结果确认新节点是“父节点”的左孩子还是又孩子
if (cmp < 0)
parent.left = e;
else
parent.right = e;
// 对加入新节点的树进行调整
fixAfterInsertion(e);
// 记录size和modCount
size++;
modCount++;
// 因为是插入新节点,所以返回的是null
return null;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
上面程序中的两个do…while就是实现”排序二叉树”的关键算法。每当程序希望添加新节点时,总是从树的根节点开始比较,即将根节点当成当前节点。
如果新增节点大于当前节点且当前节点的右子节点存在,则以右子节点作为当前节点。并继续循环
如果新增节点小于当前节点且当前节点的左子节点存在,则以左子节点作为当前节点。并继续循环
如果新增节点等于当前节点,则新增节点覆盖当前节点,并结束循环。
当TreeMap根据key来取出value时,TreeMap对应的方法如下:
public V get(Object key) {
//根据key取出Entry
Entry<K,V> p = getEntry(key);
//取出Entry所包含的value
return (p==null ? null : p.value);
}- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
现在我们可以知道,其实get(Object key)方法实质上是由getEntry()方法实现的。现在我们来看getEntry(Object key)的源码:
final Entry<K,V> getEntry(Object key) {
// 如果有比较器,返回getEntryUsingComparator(Object key)的结果
if (comparator != null)
return getEntryUsingComparator(key);
// 查找的key为null,抛出NullPointerException
if (key == null)
throw new NullPointerException();
// 如果没有比较器,而是实现了可比较接口
//将key强制转换为Comparable接口
Comparable<? super K> k = (Comparable<? super K>) key;
// 获取根节点
Entry<K,V> p = root;
// 从根节点开始对树进行遍历查找节点
while (p != null) {
// 把key和当前节点的key进行比较
int cmp = k.compareTo(p.key);
// key小于当前节点的key
if (cmp < 0)
// p “移动”到左节点上
p = p.left;
// key大于当前节点的key
else if (cmp > 0)
// p “移动”到右节点上
p = p.right;
// key值相等则当前节点就是要找的节点
else
// 返回找到的节点
return p;
}
// 没找到则返回null
return null;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
getEntry(Object obj)方法也是充分利用排序二叉树的特性来搜索目标Entry。程序依然从二叉数的根节点开始,如果被搜索节点大于当前节点,程序向”右子树”搜索,如果小于,则向”左子树”搜索。如果相等则说明找到了指定节点。
我们观察到当该TreeMap采用了定制排序。在采用定制排序的方式下,TreeMap采用getEntryUsingComparator(key)方法来根据key获取Entry。
final Entry<K,V> getEntryUsingComparator(Object key) {
K k = (K) key;
// 获取比较器
Comparator<? super K> cpr = comparator;
// 其实在调用此方法的get(Object key)中已经对比较器为null的情况进行判断,这里是防御性的判断
if (cpr != null) {
// 获取根节点
Entry<K,V> p = root;
// 遍历树
while (p != null) {
// 获取key和当前节点的key的比较结果
int cmp = cpr.compare(k, p.key);
// 查找的key值较小
if (cmp < 0)
// p“移动”到左孩子
p = p.left;
// 查找的key值较大
else if (cmp > 0)
// p“移动”到右节点
p = p.right;
// key值相等
else
// 返回找到的节点
return p;
}
}
// 没找到key值对应的节点,返回null
return null;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
其实getEntry()和getEntryUsingComparator()这两个方法实现思路几乎完全类似。只是前者对自然排序的TreeMap获取有效,后者对定制排序的TreeMap有效。
通过上述源码其实不难看出,TreeMap这个工具类的实现其实很简单。或者说,从本质上来说TreeMap就是一棵”红黑树”,每个Entry就是一个节点。
总结
1、不能有重复的元素;
2、具有排序功能;
3、TreeSet中的元素必须实现Comparable接口并重写compareTo()方法,TreeSet判断元素是否重复 、以及确定元素的顺序 靠的都是这个方法;
①对于Java类库中定义的类,TreeSet可以直接对其进行存储,如String,Integer等,因为这些类已经实现了Comparable接口);
②对于自定义类,如果不做适当的处理,TreeSet中只能存储一个该类型的对象实例,否则无法判断是否重复。
4、依赖TreeMap。
5、相对HashSet,TreeSet的优势是有序,劣势是相对读取慢。根据不同的场景选择不同的集合。
以上是关于TreeSet源码解析笔记的主要内容,如果未能解决你的问题,请参考以下文章
#yyds干货盘点# Map - TreeSet & TreeMap 源码解析