回归分析
Posted immaculate
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了回归分析相关的知识,希望对你有一定的参考价值。
回归分析即,量化因变量受自变量影响的大小,建立线性回归方程或者非线性回归方程,从而达对因变量的预测,或者对因变量的解释作用。
回归分析流程如下:
①探索性分析,画不同变量之间的散点图,进行相关性检验等,了解数据的大致情况,以及得知重点关注那几个变量;
②变量和模型选择,;
③回归分析假设条件验证;
④共线性和强影响点检查;
⑤模型修改,并且重复③④;
⑥模型验证。
基本原理
相关系数只能说明变量之间的相关性,并不能对相关性进行量化,回归分析就能够做到这一点。
一元线性回归方程为:Y=β0+β1X1+β2X2+...+βiXi+ε
而进行线性回归分析则要分析线性关系的显著性和回归系数的显著性,以及残差ε的检验。
线性关系的显著性,先假设原假设H0为各个变量间无线性关系即β0=β1=...=βi=0。这里的统计两为F统计量,只要F>F1-α,则拒绝原假设。
回归系数的显著性,在确定了线性关系的显著性之后,还需要对各个变量的归回系数的显著性进行检验,即剔除一些可有可无的变量以及回归系数,最后达到简化线性方程的效果,这里一般用T统计量进行检测,原假设为回归系数不显著,即βi=0.
残差检验,很容易想到残差是具有随机性的,能服从正太分布的特点。否则则认为还有总体的差异的信息没有提取完,需要考虑从别的方面提取。如残差散点图如二次函数分布,则应增加变量的二次项式。或者残差非独立,有自相关关系,以后的几篇博客会进一步解释。或者残差的方差为非齐性,随着自变量增大而方差增大,即应为因变量做一个转换。
探索性分析之相关性检验
H0原假设为:相关系数ρ=0。
PROC CORR DATA=EX.RETAIL RANK NOSIMPLE PLOTS(ONLY)=SCATTER(ELLIPSE=NONE NVAR=ALL);
VAR MEMBER SQUARE INVENTORY LOYALTY POPULATION TENURE;
WITH REVENUE;
RUN;
以上用到了选项,RANK表示输出报表中皮尔逊相关系数由大到小排列。NOSIMPLE表明不输出基本统计报表。PLOTS(ONLY)指明只输出PLOTS指定的图形(不输出PROC CORR默认的其他图形)。SCATTER指明做亮亮变量的散点图。NVAR=N表明分析VAR中的N个变量,NVAR=ALL最多分析10个变量。若无WITH语句则说明VAR中变量两两进行分析,若有WITH语句说明用WITH中的每一个变量分别跟VAR中的每一个变量两两分析。
结果如下:
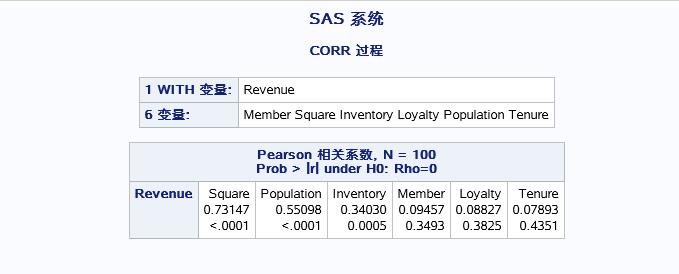
WITH变量(REVENUE)分别和每一个VAR变量的相关系数以及P值。其中有SQUARE和POPULATION和因变量具有比较强的相关性。
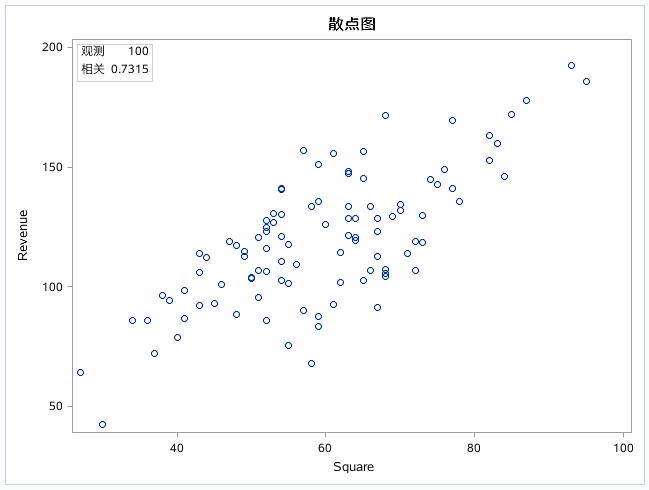
一下值只列出相关的几个变量的散点图:

变量和模型的选择
全部选择法:假设我们没有对变量的任何先验概率,可以在过程步中设置自动拟合所有可能的变量组合模型。
PROC REG DATA=EX.RETAIL PLOTS(ONLY)=(RSQUARE ADJRSQ CP); ALL_REG: MODEL REVENUE=MEMBER SQUARE INVENTORY LOYALTY POPULATION TENURE /SELECTION=RSQUARE ADJRSQ CP; RUN; QUIT;
PLOTS(ONLY)=(RSQUARE ADJRSQ CP)只显示有关R方和调整R方和CP的图,选项SELECTION=RSQUARE ADJRSQ CP即输出报表中按照第一个统计量的取值排序。
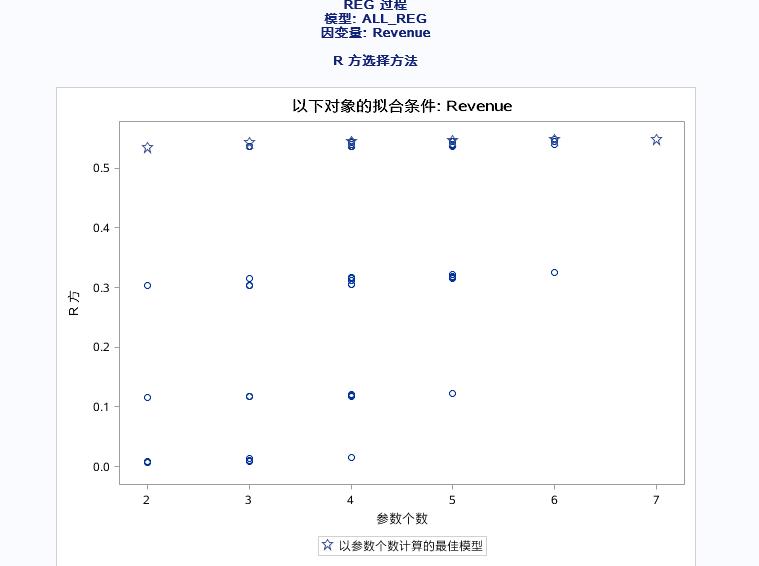
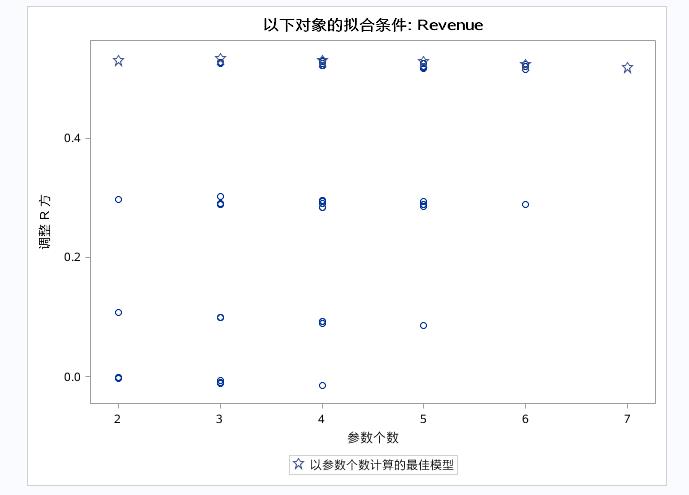
结果如下:
以上是输出所有变量组合的模型的拟合的统计值。
前面的博客中有提到过调整R方和R方的区别是:调整R方避免了R方统计是变量越多R方值越大的情况,避免给使用者造成变量越多越好的误导。
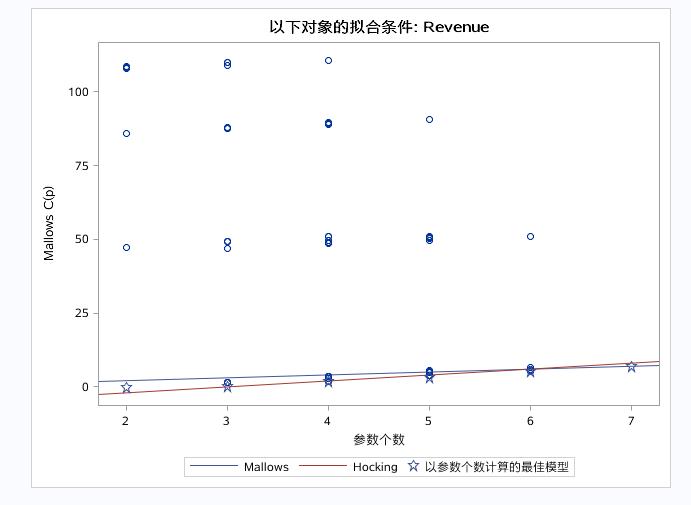
星星符号代表固定参数计算出的最佳模型。调整后R方显示最好的模型包含2~3个参数。CP散点图中有两条参考线MALLOWS为Y=P的函数线(P为参数个数),HOCKING为:Y=2P-PFULL+1。
当CP<=P时,代表该模型适合用于预测。当CP<=2P-PFULL+1代表该模型适合用于参数估计以及对因变量的解释。
上图由于CP的散点图中的散点过多,可以运用PLOTS(ONLY)=(CP)以及在model选项中加上BEST=20来只显示CP图以及值显示前20个点,来更加清晰的观察CP图。
有上图得出结论:用来预测变量是SQUARE,以解释为目的的回归模型的变量为:SQUARE和INVENTORY。
选好变量之后就可以进行拟合模型和参数估计了,提交一下代码:

PROC REG DATA=EX.RETAIL; PREDICT:MODEL REVENUE=SQUARE; EXPLAIN:MODEL REVENUE=SQUARE INVENTORY; RUN; QUIT;
代码中的PREDICT:为报表中表明两个模型的标签,结果如下:
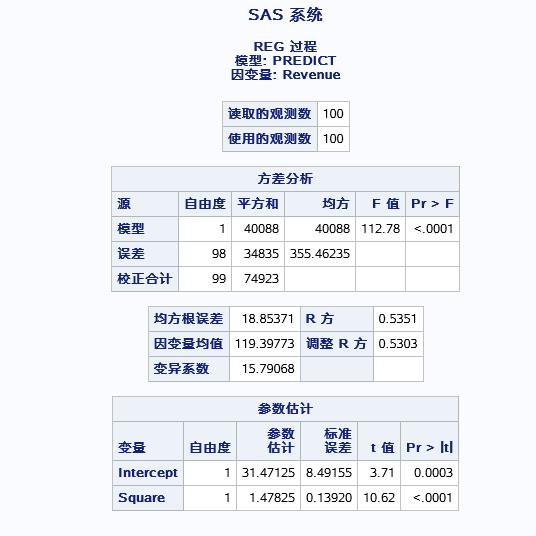
表一种的为:线性模型的显著性检验,表中F=112.78,P<0.001代表预测模型的revenue和square具有显著的线性关系。
表二中的R方=0.5351代表回归模型能够解释应变量的54%。
表三中对参数进行了估计β0=31.47 β1=1.48,所以回归模型的方程为:Y=31.47+1.48*SQUARE.
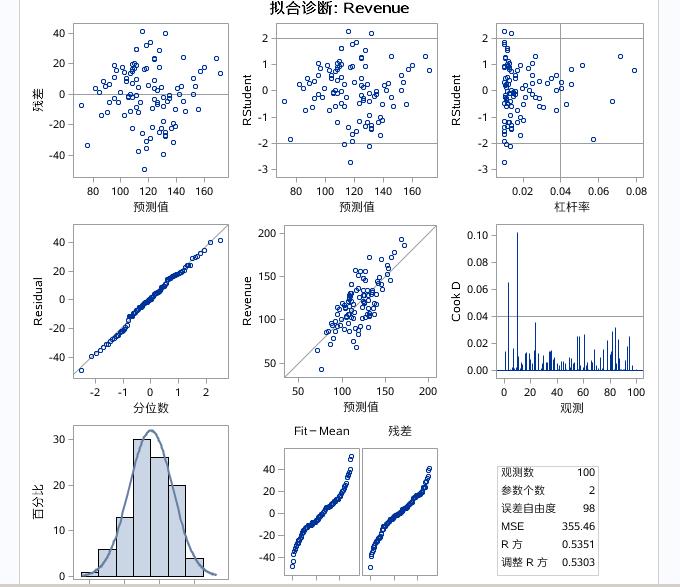
拟合诊断对残差进行了验证,包括指明了强影响点和残差分布。如上图中有几个强影点第二三个图中的两根范围线意为的几个点。还有残差分布检验何以容易的得知服从只能怪态分布。

SQUARE的残差图几乎均匀的分布的平面内,进一步说明正态性。
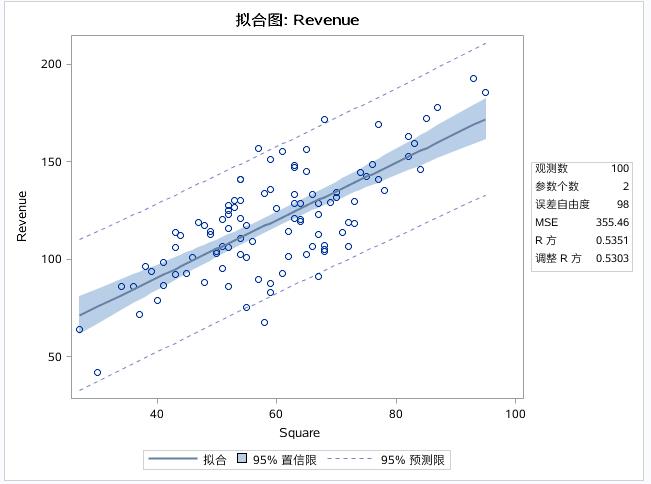
表明拟合的模型的精度,虚线以内是95%的预测限:给定一个SQUARE,REVENUE的值有95%的概率落在预测限内。
深色区域为95%置信限:即给定一个SQUARE,REVENUE的均值,有95%的概率落在置信限内。
解释模型和预测模型的输出结果类是,这里不赘述。
以上为全部选择法,同样的变量选择法还有向前选择法,向后选择法,逐步选择法,在前面的博客中对原理有过介绍,这里不说了。接下来看代码:
PROC REG DATA=EX.RETAIL PLOTS(ONLY)=ADJRSQ; FORWARD:MODEL REVENUE=MEMBER SQUARE INVENTORY LOYALTY POPULATION TENURE/SELECTION=FORWARD; BCKWARD:MODEL REVENUE=MEMBER SQUARE INVENTORY LOYALTY POPULATION TENURE/SELECTION=BCKWARD; STEPWISE:MODEL REVENUE=MEMBER SQUARE INVENTORY LOYALTY POPULATION TENURE/SELECTION=STEPWISE; RUN; QUIT;
分别提交的三种选择方法生成的模型,这里只挑逐步选择法模型进行解释,如下图:

先把SQUARE变量选进去之后,同样验证线性关系和估计参数
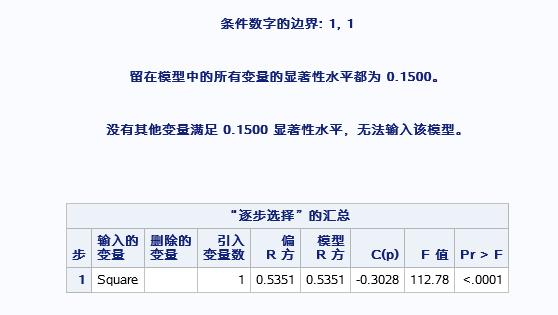
表明出square变量外,无法在选别的变量进入模型了,最后是逐步选择法的汇总情况。
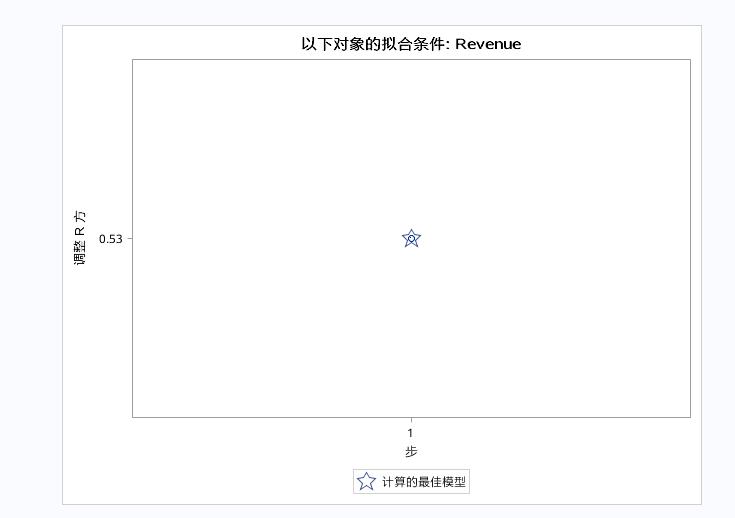
最后是调整R方图。表明第一步时模型最好。
三种变量选择方法最后得出的结论可能会不同,这时就需要使用者进行权衡。(用用R方的来权衡表象总体的贡献率)
自变量间的共线性诊断
需要知道的是:自变量间的共线性问题容易导致模型不稳定。VIF是model的选项(也称作方差膨胀系数),可以进行共线性诊断。
VIFI=1/(1-RI2)
如提交如下代码:
PROC REG DATA=EX.RETAIL PLOTS(ONLY)=ADJRSQ; FULLMODEL:MODEL REVENUE=MEMBER SQUARE INVENTORY LOYALTY POPULATION TENURE/VIF; RUN; QUIT;
输出如下结果:
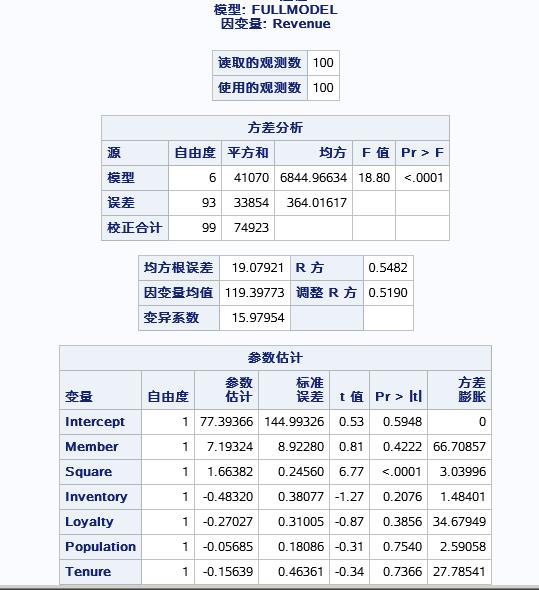
输出了线性模型检测以及方差膨胀系数,这里VIF值>10则代表存在共线性。可以一次剔除后再进行共线性验证。如先把MEMBER剔除后再进行共线性检验,直到无共线性变量为止。同时最后的模型中最好也别出现共线性变量。当然这里VIF选项可以和select选项一起使用,得到模型的变量的同时也进行共线性检验。
模型验证
得到归回方程后可以对因变量进行验证以及预测,这里可以手动编写回归方程也可以像之前的博客判别分析中的一样用PROC sore进行打分预测。提交一下代码:
DATA NEED; INPUT SQUARE @@; DATALINES; 30 40 50 60 70 80 90 ; RUN; PROC REG DATA=EX.RETAIL NOPRINT OUTEST=BETAS; PREREV:MODEL REVENUE=SQUARE; RUN; QUIT; PROC PRINT DATA=BETAS; RUN; PROC SCORE DATA=NEED SCORE=BETAS OUT=SCORED TYPE=PARMS; VAR SQUARE; RUN; PROC PRINT; RUN;
PROC REG输出的数据集为估计参数模型如图:

后面只要提供该数据集,集合对因变量进行预测,换句话说我们自己人工造一个这样的数据集也可以进行预测。
PROC SCORE的输出为:
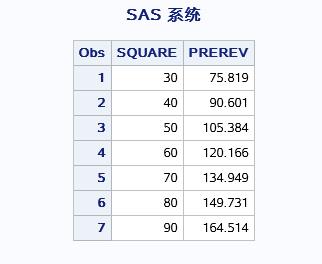
这里是对因变量进行了预测,同样可以输入几个已知的观测中的SQUARE值对REVENUE进行验证。
以上是关于回归分析的主要内容,如果未能解决你的问题,请参考以下文章