kafka+flume-ng+hdfs 整合
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka+flume-ng+hdfs 整合相关的知识,希望对你有一定的参考价值。
Kafka
由LinkedIn于2010年12月(https://thenewstack.io/streaming-data-at-linkedin-apache-kafka-reaches-1-1-trillion-messages-per-day/)开源出来一个消息的发布/订阅系统,用scala实现;版本从0.05到现在0.10.2.0(2017-02-25)
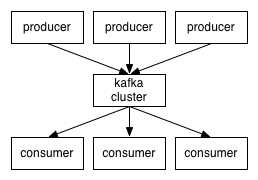
系统中,生产者(producer)主动向集群某个topic发送(push)消息(message);消费者(consumer)以组(group)为单位订阅topic,当消费者启动消费程序之后,如果集群中有未消费完的或者新的消息,则实时的拉取(pull)消息到消费者本地处理。
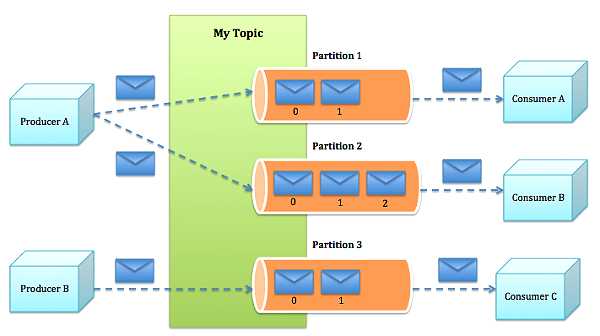
集群是以topic为单位管理和存储消息的。既然是集群,就利用集群的优势;将topic分成多个分片(partition),生产者发送的消息存储在各个分片上。对应的可能是不同节点的不同本地磁盘。每个分片可以设置多个副本(replicated)用来确保数据的容错性。
而且每个分片上的数据都是前后有序的;对应的就是后面的消息追加的文件中去;这种场景就能够利用磁盘顺序读写的特性。
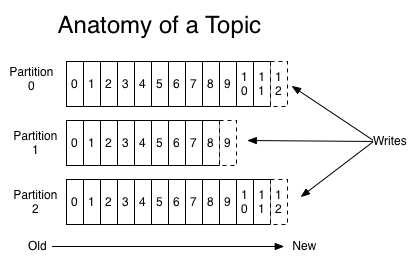
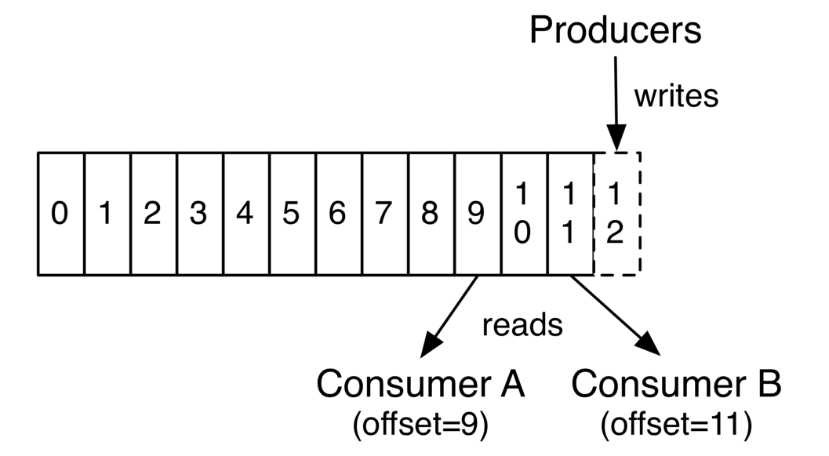
当然消费者消费也是有序消费的;偏移量(offset)从小到大顺序消费。
整体效果就是
磁盘顺序读写 内存随机读写
特点
分布式:由zookeeper管理,可以启动多个broker-server;以集群的方式给生产环境提供稳定的服务。
容错性:大部分分布式都具有的。
1.只要有一个正常的broker-server,集群就能正常运行。
2.可以设置为Topic的partition设置副本,确保就算一台机器的磁盘坏了;也不影响数据消费
负载问题:
1.生产者发送消息可以指定规则,发送到不同的partition上。
2.topic中所有partition选取一个对外提供服务的leader;如果leader宕掉了,从后选中选取下一个。
可扩展性:新增broker非常方便。
生产者样例代码


1 import java.util.Properties 2 import kafka.producer.ProducerConfig 3 import kafka.javaapi.producer.Producer 4 import java.util.Random 5 import java.util.Date 6 import kafka.producer.KeyedMessage 7 import kafka.producer.Partitioner 8 import kafka.utils.VerifiableProperties 9 import org.apache.log4j.PropertyConfigurator 10 import java.util.concurrent.TimeUnit 11 import java.text.SimpleDateFormat 12 import org.tx.common.BIConstant 13 14 /** 15 * @date 2015-10-27 16:54:19 16 */ 17 object FirstKafkaProducer { 18 19 PropertyConfigurator.configure("etc/log4j.properties"); 20 21 def main(args: Array[String]): Unit = { 22 23 24 // val Array(interval,records) = args 25 val (interval,records) = (1,1) 26 val props = new Properties() 27 // props.put("metadata.broker.list", "own:9092,own:9093,own:9094") 28 props.put("metadata.broker.list", "hdpc1-dn003:9092") 29 props.put("serializer.class", "kafka.serializer.StringEncoder") 30 props.put("partitioner.class", "org.henry.scala.scalamvn.SimplePartitioner") 31 // props.put("request.required.acks", "-1") 32 val config = new ProducerConfig(props); 33 val producer = new Producer[String, String](config) 34 val sdf = new SimpleDateFormat(BIConstant.DATE_SDF) 35 36 for (i <- 1 to records.toInt) { 37 val rnd = new Random(); 38 val runtime = new Date(); 39 val ip = rnd.nextInt(255).toString(); 40 // val msg = runtime + ",www.example.com," + ip; 41 val msg = "1001|2|2|"+runtime.getTime 42 println(" *** "+msg) 43 val data = new KeyedMessage[String, String]("mytopic", ip, msg) 44 TimeUnit.SECONDS.sleep(interval.toInt) 45 producer.send(data) 46 } 47 producer.close 48 } 49 } 50 51 class SimplePartitioner(props:VerifiableProperties) extends Partitioner { 52 53 override def partition(key: Any, numPartitions: Int): Int = { 54 var partition = 0; 55 val stringKey = key.toString(); 56 val offset = stringKey.lastIndexOf(‘.‘); 57 if (offset > 0) { 58 partition = Integer.parseInt( stringKey.substring(offset+1)) % numPartitions; 59 } 60 partition; 61 } 62 }
消费者样例代码(https://cwiki.apache.org/confluence/display/KAFKA/Consumer+Group+Example)
1 package com.test.groups; 2 3 import kafka.consumer.ConsumerIterator; 4 import kafka.consumer.KafkaStream; 5 6 public class ConsumerTest implements Runnable { 7 private KafkaStream m_stream; 8 private int m_threadNumber; 9 10 public ConsumerTest(KafkaStream a_stream, int a_threadNumber) { 11 m_threadNumber = a_threadNumber; 12 m_stream = a_stream; 13 } 14 15 public void run() { 16 ConsumerIterator<byte[], byte[]> it = m_stream.iterator(); 17 while (it.hasNext()) 18 System.out.println("Thread " + m_threadNumber + ": " + new String(it.next().message())); 19 System.out.println("Shutting down Thread: " + m_threadNumber); 20 } 21 }
flume-ng
由Cloudera于2010年5月开源出来,在2010年7月加入Cloudera Hadoop的发行版本CDH3b2(http://blog.cloudera.com/blog/2010/07/whats-new-in-cdh3b2-flume/)中,用Java开发的。
开始是flume-OG,一直到2011年10月,最后版本是0.94.0。后面对核心组件/代码架构的进行里程碑式的重构,就有了flume-ng;并开源到apache。
flume OG:agent采集数据,然后发送到collector;collector汇集后存储到目的地。
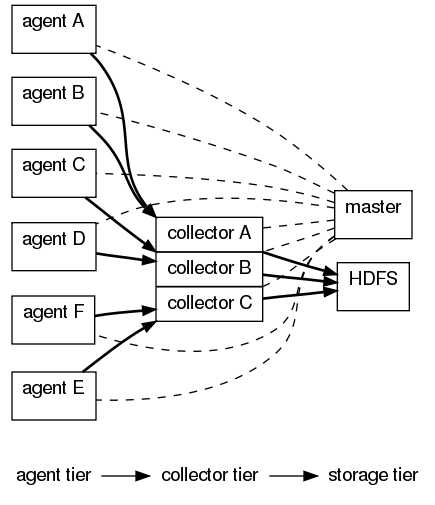
flume NG最小单位的架构;只有agent角色,分为三个步骤来接收和传输数据
Source(数据采集): 默认实现了从不同数据源接受数据。如Avro/Kafka/Netcat/Http等等;也可以根据具体需求扩展实现source
Channel(数据临时存储的地方): 接受source的数据,可选择持久化到数据库或者本地磁盘;确保sink处理完数据后,删除;保证数据完整性。
Sink(数据存储目的地):数据存储介质的实现。可选择HDFS/kafka/local file等等。
在整个流程中,接收到的每条数据被封装成Event来进行传递和处理的。
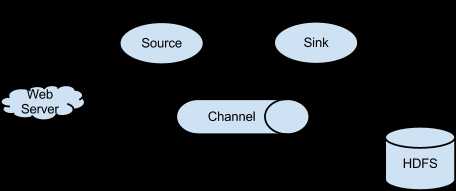
特点
1.部署,配置简单方便;通用
2.中间对数据做了临时存储,确保数据不丢失
整合
那么将这几个有关联的开源组件为我所用;而且还要考虑到后期开发调试方便,版本管理;部署到生产环境下的时候操作简单,可维护性好;能够监控JVM状态。就需要进行自动化部署的改造,而且公司有成熟可靠的解决方案。那么一切就顺理成章了。
整体思路是:使用maven将项目依赖的jar包/启动脚本,简单的配置打包成tar包。具体的配置项执行启动脚本,调用Main方法后从公共的配置中心加载。
在这次改造中,主要的任务有两大块。
1.理解,使用现在成熟的自动化部署步骤、过程。
2.确保功能正常的情况下,将原flume的conf下面配置文件搬移到配置中心的事情。
基本流程是:
将代码提交到Git进行管理,使用jekins获取Git代码打成tar包。tar包里面基本包含bin,conf,lib目录。bin下面存放任务启动停止脚本,conf下面存放简单的配置参数,lib下面存放项目依赖的jar和自身jar包。发布到私服;
服务器下载tar包,解压;启动bin下面start.sh脚本启动应用。应用启动时会将配套的日志、JMX监控服务注册,启动;再从配置中心获取详细的参数配置;启动目标程序。
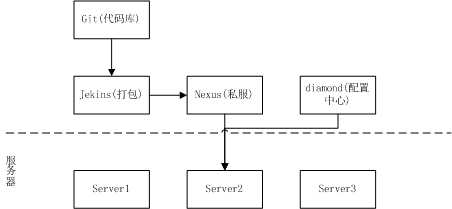
以本次flume的使用场景作为例子,具体做了哪些事。
由于我们的数据源选取为Kafka,存储介质是HDFS。所以数据传输流就是kafka(source)-->local file(channel)-->HDFS(sink)
而原生态的flume启动入口是使用脚本调用org.apache.flume.node.Application(Main方法入口程序),所以改造的切入点就是这里。
调用node.Application时,额外传入参数
-Djava-container=com.appleframework.flume.node.Application
-Dconfig-factory=com.appleframework.config.PropertyConfigurerFactory
其中PropertyConfigurerFactory是读取、加载system.properties指向配置中心的详细配置参数的作用。Application主要是增加从公共配置中加载参数的方法。其他地方保持统一。其中deploy.group=flume-demo,deploy.dataId=hdfs,deploy.env=dev这三个参数来识别一组配置信息。
更改的代码详情如下
node.Application
1 public class Application { 2 3 ... 4 public static void main(String[] args) { 5 6 7 ... 8 boolean isZkConfigured = false; 9 10 Options options = new Options(); 11 12 Option option = new Option("n", "name", true, "the name of this agent"); 13 option.setRequired(true); 14 options.addOption(option); 15 16 option = new Option("f", "conf-file", true, "specify a config file (required if -z missing)"); 17 option.setRequired(false); 18 options.addOption(option); 19 20 option = new Option(null, "no-reload-conf", false, "do not reload config file if changed"); 21 options.addOption(option); 22 23 // Options for Zookeeper 24 option = new Option("z", "zkConnString", true, "specify the ZooKeeper connection to use (required if -f missing)"); 25 option.setRequired(false); 26 options.addOption(option); 27 28 option = new Option("p", "zkBasePath", true, "specify the base path in ZooKeeper for agent configs"); 29 option.setRequired(false); 30 options.addOption(option); 31 32 option = new Option("h", "help", false, "display help text"); 33 options.addOption(option); 34 35 option = new Option("e", "env", true, "the environment of this app"); 36 option.setRequired(false); 37 options.addOption(option); 38 39 Component.init(args); 40 ... 41 } 42 ... 43 }
Component
1 package com.appleframework.flume.node; 2 3 import java.io.File; 4 import java.lang.management.ManagementFactory; 5 import java.text.SimpleDateFormat; 6 import java.util.ArrayList; 7 import java.util.Date; 8 import java.util.Hashtable; 9 import java.util.List; 10 import java.util.Properties; 11 12 import javax.management.MBeanServer; 13 import javax.management.ObjectName; 14 15 import org.apache.log4j.Logger; 16 17 import com.appleframework.boot.config.ConfigContainer; 18 import com.appleframework.boot.core.CommandOption; 19 import com.appleframework.boot.core.Container; 20 import com.appleframework.boot.core.log4j.Log4jContainer; 21 import com.appleframework.boot.core.log4j.LoggingConfig; 22 import com.appleframework.boot.core.monitor.MonitorConfig; 23 import com.appleframework.boot.core.monitor.MonitorContainer; 24 import com.appleframework.config.core.PropertyConfigurer; 25 26 public class Component { 27 28 private static Logger logger = Logger.getLogger(Component.class); 29 30 static void init(String[] args) { 31 //处理启动参数 32 CommandOption.parser(args); 33 34 MBeanServer mbs = ManagementFactory.getPlatformMBeanServer(); 35 36 final List<Container> containers = new ArrayList<Container>(); 37 containers.add(new Log4jContainer()); 38 containers.add(new MonitorContainer()); 39 40 String configContainer = System.getProperty("config-factory"); 41 if (null != configContainer) { 42 containers.add(new ConfigContainer(configContainer)); 43 } 44 45 for (Container container : containers) { 46 container.start(); 47 try { 48 49 Hashtable<String, String> properties = new Hashtable<String, String>(); 50 51 properties.put(Container.TYPE_KEY, Container.DEFAULT_TYPE); 52 properties.put(Container.ID_KEY, container.getType()); 53 54 ObjectName oname = ObjectName.getInstance("com.appleframework", properties); 55 Object mbean = null; 56 if(container instanceof Log4jContainer) { 57 mbean = new LoggingConfig(); 58 } 59 else if(container instanceof MonitorContainer) { 60 mbean = new MonitorConfig(); 61 } 62 else { 63 logger.error("The Error Container :" + container.getName()); 64 } 65 66 if (mbs.isRegistered(oname)) { 67 mbs.unregisterMBean(oname); 68 } 69 mbs.registerMBean(mbean, oname); 70 } catch (Exception e) { 71 logger.error("注册JMX服务出错:" + e.getMessage(), e); 72 } 73 logger.warn("服务 " + container.getType() + " 启动!"); 74 } 75 76 logger.warn(new SimpleDateFormat("[yyyy-MM-dd HH:mm:ss]").format(new Date()) + " 所有服务启动成功!"); 77 78 extHadoopConfToLocal(); 79 } 80 81 /** 82 * 读取配置中心的hdfs配置到本地,然后动态加载到classpath 83 */ 84 static void extHadoopConfToLocal() { 85 86 System.setProperty("HADOOP_USER_NAME","hdfs"); 87 String abc = PropertyConfigurer.getString("abc"); 88 logger.info("load conf from center ["+abc+"]"); 89 String dir = System.getProperty("user.dir"); 90 File file = new File(dir + "/conf/core-site.xml"); 91 92 // write core-site.xml to local if not exists 93 if (!file.exists()) { 94 Properties centerProps = PropertyConfigurer.getProps(); 95 Properties hdfsProps = new Properties(); 96 for (String key : centerProps.keySet().toArray(new String[0])) { 97 if (HDFSUtil.startWith(key)) { 98 hdfsProps.put(key, centerProps.get(key)); 99 } 100 } 101 try { 102 HDFSUtil.writerXMLToLocal(file, hdfsProps); 103 } catch (Throwable t) { 104 logger.error("write hdfs conf to local errors["+hdfsProps+"]", t); 105 } 106 } 107 108 //load dynamically to classpath 109 ExtClasspathLoader.loadResourceDir(file.getParent()); 110 } 111 }
HDFSUtil
1 package com.appleframework.flume.node; 2 3 import java.io.File; 4 import java.io.FileNotFoundException; 5 import java.io.FileOutputStream; 6 import java.io.UnsupportedEncodingException; 7 import java.lang.reflect.Method; 8 import java.net.URL; 9 import java.net.URLClassLoader; 10 import java.util.HashSet; 11 import java.util.Properties; 12 import java.util.Set; 13 14 import org.dom4j.Document; 15 import org.dom4j.DocumentHelper; 16 import org.dom4j.Element; 17 import org.dom4j.io.OutputFormat; 18 import org.dom4j.io.XMLWriter; 19 20 /** 21 * @author tjuhenryli<[email protected]> 22 * @date 2017-02-23 10:31:14 23 * 24 **/ 25 26 public class HDFSUtil { 27 //DFS_HA_NAMENODES_KEY_PREFIX DFS_NAMENODE_RPC_ADDRESS_KEY DFS_CLIENT_FAILOVER_PROXY_PROVIDER_KEY_PREFIX 28 public static final String FS_DEFAULT_NAME_KEY = "fs.defaultFS"; 29 public static final String DFS_NAMESERVICES = "dfs.nameservices"; 30 public static final String DFS_HA_NAMENODES_KEY_PREFIX = "dfs.ha.namenodes"; 31 public static final String DFS_NAMENODE_RPC_ADDRESS_KEY = "dfs.namenode.rpc-address"; 32 public static final String DFS_CLIENT_FAILOVER_PROXY_PROVIDER_KEY_PREFIX = "dfs.client.failover.proxy.provider"; 33 public static Set<String> CACHE = new HashSet<String>(); 34 static { 35 CACHE.add(FS_DEFAULT_NAME_KEY); 36 CACHE.add(DFS_NAMESERVICES); 37 CACHE.add(DFS_HA_NAMENODES_KEY_PREFIX); 38 CACHE.add(DFS_NAMENODE_RPC_ADDRESS_KEY); 39 CACHE.add(DFS_CLIENT_FAILOVER_PROXY_PROVIDER_KEY_PREFIX); 40 } 41 42 public static boolean startWith(String content) { 43 for (String key : CACHE) 44 if (content.startsWith(key)) return true; 45 return false; 46 } 47 48 public static void writerXMLToLocal(File file,Properties props) throws Throwable { 49 Element root = DocumentHelper.createElement("configuration"); 50 Document document = DocumentHelper.createDocument(root); 51 52 for (String key : props.keySet().toArray(new String[0])) { 53 Element property = root.addElement("property"); 54 Element name = property.addElement("name"); 55 Element value = property.addElement("value"); 56 name.setText(key); 57 value.setText(props.getProperty(key)); 58 } 59 60 OutputFormat format = new OutputFormat(" ", true);// 设置缩进为4个空格,并且另起一行为true 61 if (file.exists()) return; 62 else if (!file.getParentFile().exists()) file.getParentFile().mkdirs(); 63 XMLWriter xmlWriter = new XMLWriter(new FileOutputStream(file), format); 64 xmlWriter.write(document); 65 } 66 67 }
ExtClasspathLoader
1 package com.appleframework.flume.node; 2 3 import java.io.File; 4 import java.lang.reflect.Method; 5 import java.net.URL; 6 import java.net.URLClassLoader; 7 import java.util.ArrayList; 8 import java.util.List; 9 10 /** 11 * 根据properties中配置的路径把jar和配置文件加载到classpath中。 12 * @author jnbzwm 13 * 14 */ 15 public final class ExtClasspathLoader { 16 /** URLClassLoader的addURL方法 */ 17 private static Method addURL = initAddMethod(); 18 19 private static URLClassLoader classloader = (URLClassLoader) ClassLoader.getSystemClassLoader(); 20 21 /** 22 * 初始化addUrl 方法. 23 * @return 可访问addUrl方法的Method对象 24 */ 25 private static Method initAddMethod() { 26 try { 27 Method add = URLClassLoader.class.getDeclaredMethod( "addURL" , new Class[] { URL.class } ); 28 add.setAccessible( true ); 29 return add; 30 } 31 catch (Exception e) { 32 throw new RuntimeException(e); 33 } 34 } 35 36 /** 37 * 加载jar classpath。 38 */ 39 // public static void loadClasspath() { 40 // List < String > files = getJarFiles(); 41 // for (String f : files) { 42 // loadClasspath(f); 43 // } 44 // 45 // List < String > resFiles = getResFiles(); 46 // 47 // for (String r : resFiles) { 48 // loadResourceDir(r); 49 // } 50 // } 51 52 public static void loadClasspath(String filepath) { 53 File file = new File(filepath); 54 loopFiles(file); 55 } 56 57 public static void loadResourceDir(String filepath) { 58 File file = new File(filepath); 59 loopDirs(file); 60 } 61 62 /** 63 * 循环遍历目录,找出所有的资源路径。 64 * @param file 当前遍历文件 65 */ 66 private static void loopDirs(File file) { 67 // 资源文件只加载路径 68 if (file.isDirectory()) { 69 addURL(file); 70 File[] tmps = file.listFiles(); 71 for (File tmp : tmps) { 72 loopDirs(tmp); 73 } 74 } 75 } 76 77 /** 78 * 循环遍历目录,找出所有的jar包。 79 * @param file 当前遍历文件 80 */ 81 private static void loopFiles(File file) { 82 if (file.isDirectory()) { 83 File[] tmps = file.listFiles(); 84 for (File tmp : tmps) { 85 loopFiles(tmp); 86 } 87 } 88 else { 89 if (file.getAbsolutePath().endsWith( " .jar " ) || file.getAbsolutePath().endsWith( " .zip " )) { 90 addURL(file); 91 } 92 } 93 } 94 95 /** 96 * 通过filepath加载文件到classpath。 97 * @param filePath 文件路径 98 * @return URL 99 * @throws Exception 异常 100 */ 101 private static void addURL(File file) { 102 try { 103 addURL.invoke(classloader, new Object[] { file.toURI().toURL() } ); 104 } 105 catch (Exception e) { 106 } 107 } 108 109 /** 110 * 从配置文件中得到配置的需要加载到classpath里的路径集合。 111 * @return 112 */ 113 private static List < String > getJarFiles() { 114 // TODO 从properties文件中读取配置信息略 115 return new ArrayList<String>() ; 116 } 117 118 /** 119 * 从配置文件中得到配置的需要加载classpath里的资源路径集合 120 * @return 121 */ 122 private static List < String > getResFiles() { 123 // TODO 从properties文件中读取配置信息略 124 List<String> files = new ArrayList<String>(); 125 files.add("etc"); 126 return files ; 127 } 128 129 public static void main(String[] args) { 130 } 131 }
以上是关于kafka+flume-ng+hdfs 整合的主要内容,如果未能解决你的问题,请参考以下文章