MySQL 数据库主从复制架构
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL 数据库主从复制架构相关的知识,希望对你有一定的参考价值。
前文《MySQL 数据库事务与复制》分析了 mysql 复制过程中如何保证 binlog 和事务数据之间的一致性,本文进一步分析引入从库后需要保证主从的数据一致性需要考虑哪些方面。
原生复制架构
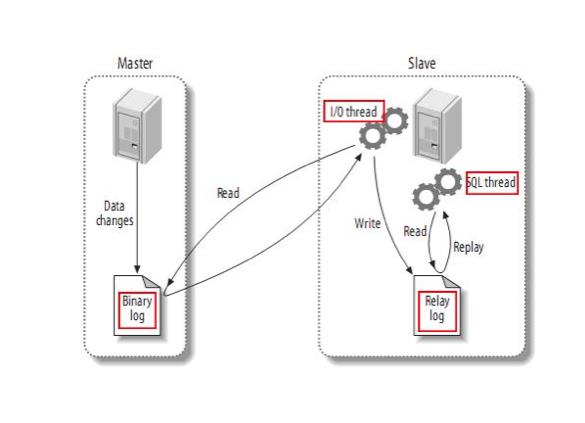
MySQL 的原生复制架构原理如上图所示。从库的 I/O Thread 线程负责不断读取主库的 binlog 日志文件并写入本地的 Relay log 临时缓存。从库的 SQL Thread 线程则不断读取 Relay log 重放事件入库。整个过程看起来是比较简单清晰的,但其中有几个点对主从数据一致性有关键影响,我们下面逐一分析。
主从复制的场景下,产生数据不一致的现象有两种:
- 数据丢失
- 数据重复
从库的 I/O Thread 是通过网络读取主库的 binlog 的,若出现网络故障,有可能产生数据丢失。为避免网络故障导致的数据丢失,网络恢复后从库重新连接上来需要知道从主库 binlog 的哪个位置重新传输数据。从库需要记住中断发生时 binlog 的位置,并从该断点处重新读取,这个断点我们称为从库的重传检查点。一个可靠的重传检查点必须是在从库读到数据并写入到本地 Relay log 持久化之后才可建立,否则都有丢失数据的可能。
由于主从复制过程的分布式特征,需要保证复制过程的幂等性,也就是重复复制同一条数据最终不会产生重复的数据。防重策略是必须的,一般符合范式特征的数据库表设计通过主键来防重,而无主键表数据可以通过所有字段联合唯一索引来防重。有了防重策略就可以任意回溯复制过程,而不必考虑从库产生重复数据。
为了保证主从数据一致性,复制过程不仅要保证不丢失、不重复,还需要保证操作顺序一致。binlog 的事件日志反应了主库并发事务的操作序列,最终这种序列也要原样反应到从库上。所以原生复制架构为了做到这点,采用了单线程模型的串行化操作。这也是没办法的,因为在数据库层面是无法知道不同数据之间的因果和依赖关系,因此无法并行入库。
原生的复制架构做到了无丢失、无重复和顺序一致性,普通场景下基本可用,但也存在一些不足:
- 可监控性、可管理性相对较弱。
- 对于异构数据无能为力。
- 通用的单线程模型可能成为性能瓶颈,导致复制延时过高。
- 一对多场景下对主库形成过大复制压力,影响主库可用性。
一些特殊场景下的数据库复制分布,使用原生复制架构则不一定合适,可能的场景有:
- 大型库,数据量大,写入量大,还需要跨地域、跨机房的复制,而且对复制延时长短比较敏感,比如大型电商的订单、交易类数据库。
所以我们才需要考虑针对特殊场景自定义复制架构,下面我们看一个自定义复制架构的概念原理图。
自定义复制架构
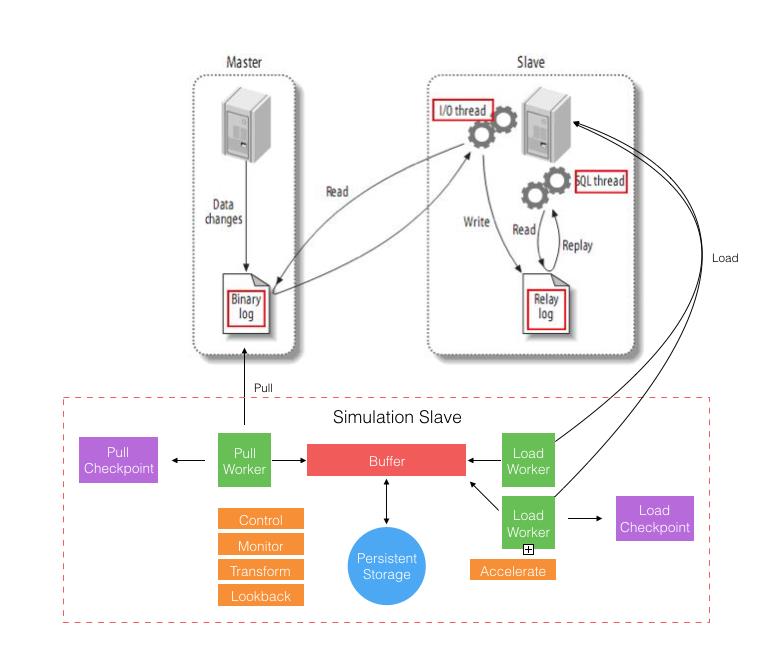
如上,自定义复制架构参考原生架构模拟成一个 MySQL 从库,它内部包括三个主要角色:
- Pull Worker,作用类似于原生的 I/O Thread。
- Buffer + Persistent Storage,作用类似于原生的 Relay log。
- Load Worker,作用类似于原生的 SQL Thread。
由于是自定义程序实现则可以在无改造 MySQL 的前提下提供额外的功能,相对应用和 MySQL 都可以做到透明。相对原生复制架构的不足,自定义复制架构可以提供更好的复制过程监控和管理能力,并支持异构数据转换等等。而对于需要跨地域、跨机房且延时敏感的大型库复制,则可以通过适当的策略来加速复制过程。
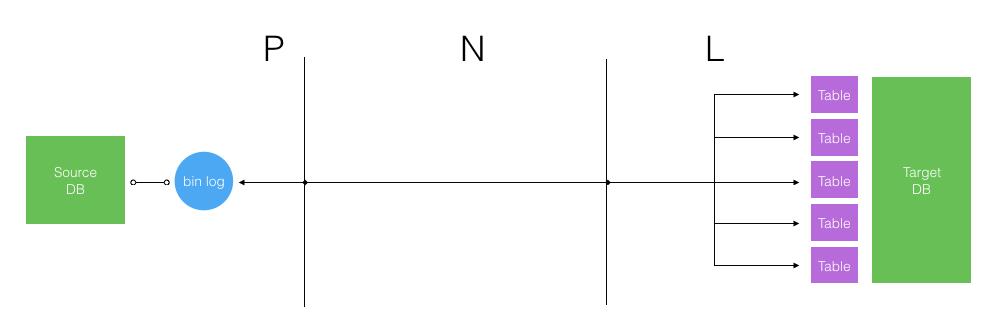
比如前面提到的大型电商的订单、交易类数据库,一般都是分库分表的。分库分表后,不同库表之间的数据其实在业务上是完全独立的,是可以支持并行写入的。所以我们看上图为什么画了两个 Load Worker,就是表达可以针对业务独立的表进行并行写入。一条数据的复制延时包括:
总时长 T = P + N + L; 其中 P 是 Pull Worker 处理时长,N 是网络传输时长, L 是 Load Worker 处理时长。
同一个库的 binlog 是顺序的不好并行拉取,传输过程的网络时长也是刚性的,唯一能加速的就是入库处理。按业务独立的不同表可以做到并行的多线程入库操作,以缩短 L 的整体时长,如下图所示。
总结
本文分析了 MySQL 基于 binlog 的主从复制原理,从数据一致性的角度考虑分布式网络环境下主从架构设计的关键要素。在分析了 MySQL 原生复制架构的基础上给出了一个灵活性和可控性更高的自定义复制架构的高层设计。理解了主从复制架构如何保证数据一致性后,我们后面才可进一步考虑在双写主库的场景如何做双向复制同步并保证双主库的数据最终一致性问题。这个系列下一篇文章会专门分析这个问题。
参考
[1] MySQL Internals Manual. Replication.
[2] MySQL Internals Manual. The Binary Log.
[3] in355hz. 数据库 ACID 的实现.
[4] jb51. MySQL 对 binlog 的处理说明.
[5] repls. 浅析 innodb_support_xa 与 innodb_flush_log_at_trx_commit.
[6] 68idc. MySQL 5.6 之 DBA 与开发者指南.
[7] csdn. 高性能 MySQL 主从架构的复制原理及配置详解
下面是我的微信公众号 「瞬息之间」,除了写技术的文章、还有产品、行业和人生的思考,希望能和更多走在这条路上同行者交流。
以上是关于MySQL 数据库主从复制架构的主要内容,如果未能解决你的问题,请参考以下文章