R系列:分词去停用词画词云(词云形状可自定义)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R系列:分词去停用词画词云(词云形状可自定义)相关的知识,希望对你有一定的参考价值。
附注:不要问我为什么写这么快,是16年写的。
R的优点:免费、界面友好(个人认为没有matlab友好,matlab在我心中就是统计软件中极简主义的代表)、小(压缩包就几十M,MATLAB.R2009b的压缩包是1.46G)、包多(是真的多,各路好友会经常上传新的包)。
R的麻烦之处:经常升级,是经常,非常经常,这就导致你在加载一个包之前需要考虑这个包要在R的哪个版本上才能使用,而往往做一件事情都要加载10个包左右,一般比较方便的做法就是先升级到最新版,因为只有小部分的包在新版本上不能用。
言归正传,下面用R语言画出红楼梦的词云图。主要是为了演示词云图的画法,不涉及分析。
一直对红楼有不可言说的感情,再见,纯真,你好,任重道远!
一、软件准备
版本:R x64 3.2.5(我的电脑是64位的,可根据自己电脑自行安装相应版本)
下载链接:https://mirrors.tuna.tsinghua.edu.cn/CRAN/
二、数据准备
文本:红楼梦txt,1.69M,链接:
http://vdisk.weibo.com/s/AfY-rVkr37U3?sudaref=www.so.com
词典:
http://pinyin.sogou.com/dict/search/search_list/%BA%EC%C2%A5%C3%CE/normal/1
停用词库:根据需要自定义了部分停用词,详情见附录1。
三、算法介绍
采用R语言里的Rwordseg包分词。Rwordseg是R环境下的中文分词工具,用rJava调用Java分词工具Ansj。Ansj也是一个开源的Java中文分词工具,基于中科院ictclas中文分词算法,采用HMM模型。
自带基础词库,支持新加词典。
新加词典放在E:\\R-3.2.5\\library\\Rwordseg\\dict目录下。(E是R安装位置)
Rwordseg包的详细说明可在E:\\R-3.2.5\\library\\Rwordseg\\doc\\Rwordseg_Vignette_CN.pdf目录下查看。
四、程序及结果
1.总耗时:1min左右
1.1.分词耗时:24.54秒
图1 分词耗时

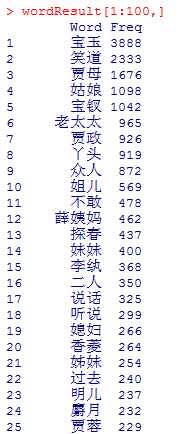
2.结果
2.1分词结果
图2 分词部分结果
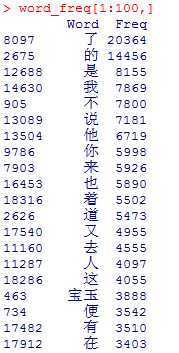
2.2过滤单字后结果
图3显示,结果中有部分没有意义的词,如“什么”,“一个”,这些没有意义的词也称为“停用词”,需要把他们去掉。
图3 过滤单字后部分结果
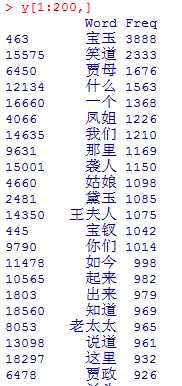
2.3去停用词后结果
到图4这里,我们便完成了词频的统计,实际应用中还需要合并同义词的词频,如“林黛玉”“黛玉”“颦颦”便属于同义词。
图4 去停用词后部分结果
2.4词云
词云结果如下。
图5 词云图



3.程序
#加载分词需要用到的包
library(tm)
library(Rwordseg)
library(wordcloud2)
library(tmcn)
#自定义词典
installDict(dictpath = ‘C:/Users/Thinkpad/Desktop/红楼梦/红楼梦诗词.scel‘,
dictname =‘hlmsc‘, dicttype = ‘scel‘)
installDict(dictpath = ‘C:/Users/Thinkpad/Desktop/红楼梦/红楼梦群成员名字词库.scel‘,
dictname =‘hlmname‘, dicttype = ‘scel‘)
installDict(dictpath = ‘C:/Users/Thinkpad/Desktop/红楼梦/红楼梦词汇.scel‘,
dictname =‘hlmch‘, dicttype = ‘scel‘)
installDict(dictpath = ‘C:/Users/Thinkpad/Desktop/红楼梦/红楼词语.scel‘,
dictname =‘hlmcy‘, dicttype = ‘scel‘)
installDict(dictpath = ‘C:/Users/Thinkpad/Desktop/红楼梦/《红楼梦》词汇大全【官方推荐】.scel‘,
dictname = ‘hlmch‘, dicttype = ‘scel‘)
#查看已添加词典
listDict()
#添加新词可以使用函数insertWords(),这里不添加新词
#分词,对segmentCN()第一个参数对应的文本分词,并将结果返回给第二个参数对应的位置,这种方式可以节约很多时间
system.time(segmentCN(‘C:/Users/Thinkpad/Desktop/红楼梦/红楼梦.txt‘,outfile=‘C:/Users/Thinkpad/Desktop/红楼梦/word_result.txt‘,blocklines=10000))
#统计词频,加载data.table()包,提高读取速度;把上步txt格式的分词结果变为csv格式再读取
library(data.table)
fc_result=fread("C:/Users/Thinkpad/Desktop/红楼梦/word_result.csv")
word_freq=getWordFreq(string = unlist(fc_result))
#按照词频排序,排名前100的词
word_freq[1:100,]
#dim(word_freq)[1]
#过滤前10000个热词中的单字
x=rep(0,times=10000)
for(i in 1:10000){
if(nchar(word_freq[i,])[1]>1)
x[i]=i
}
length(x)
y=sort(x)[2930:10000]
y=word_freq[y,]
#y[1:200,]
write.table(y,file="C:/Users/Thinkpad/Desktop/红楼梦/word_result2.txt")
#去停用词
ssc=read.table("C:/Users/Thinkpad/Desktop/红楼梦/word_result2.txt",header=TRUE)
class(ssc)
ssc[1:10,]
ssc=as.matrix(ssc)
stopwords=read.table("C:/Users/Thinkpad/Desktop/红楼梦/停用词.txt")
class(stopwords)
stopwords=as.vector(stopwords[,1])
wordResult=removeWords(ssc,stopwords)
#去空格
kkk=which(wordResult[,2]=="")
wordResult=wordResult[-kkk,][,2:3]
#去停用词结果
wordResult[1:100,]
write.table(wordResult,file="C:/Users/Thinkpad/Desktop/红楼梦/wordResult.txt")
#画出词云
wordResult=read.table("C:/Users/Thinkpad/Desktop/红楼梦/wordResult.txt")
#词云以"红楼梦"的形式展示
wordcloud2(wordResult,figPath=‘C:/Users/Thinkpad/Desktop/2.jpg‘)
#词云以"石头记"的形式展示
wordcloud2(wordResult,figPath=‘C:/Users/Thinkpad/Desktop/3.jpg‘)
#词云以汉字“红楼梦”的形式展示
letterCloud(wordResult,"红楼梦")
五、附录
附录1:停用词库
停用词库截图
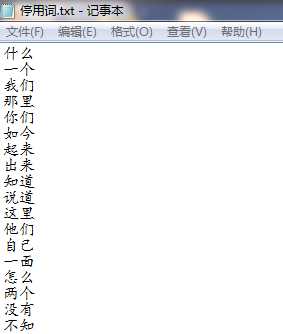
停用词库详情
什么
一个
我们
那里
你们
如今
起来
出来
知道
说道
这里
他们
自己
一面
怎么
两个
没有
不知
只见
这个
这样
听见
进来
咱们
告诉
就是
东西
回来
出去
这些
所以
过来
心里
如此
不能
一时
只得
今日
几个
这么
一回
只管
今儿
那些
问道
如何
那边
原来
回去
看见
进去
一声
一句
这话
到底
别人
于是
果然
还有
有些
此时
岂不
的话
别的
想起
许多
多少
不用
不如
十分
后来
时候
附录2:画词云使用的图


end!
以上是关于R系列:分词去停用词画词云(词云形状可自定义)的主要内容,如果未能解决你的问题,请参考以下文章