scikit-learn Quick Start
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了scikit-learn Quick Start相关的知识,希望对你有一定的参考价值。
Time:2017/02/24 21:50 at UTSZ
Environment: pyCharm, python2.7
一般来讲,学习是指利用一些已知的样例数据来预测未知数据的属性。
1. 我们可以将学习问题分为如下的类别:
- 监督学习:样例数据有自己的标签。
- 分类:要预测的值是离散的
- 回归:要预测的值是连续的
- 无监督学习:样例数据没有自己的标签。
2. 机器学习的常用步骤(python):
- 导入要用的包(sklearn)
- 加载训练数据
- 确定要用的训练算法(原例是用的svm)
- 训练,算法内部得到一些参数的值
- 预测
from sklearn import datasets from sklearn import svm # 加载数据集 digits = datasets.load_digits() # 分类算法 clf = svm.SVC(gamma=0.001, C=100.) # 训练 clf.fit(digits.data[:-1], digits.target[:-1]) # 预测 result = clf.predict(digits.data[-1:]) # 输出结果 print result
3. 训练模型的保存和重新加载
在实际的编码中,我们经常要将之前训练过的模型重复使用,为了不必每次训练,节省时间和空间,我们需要将当前训练过的模型保存起来,便于下次的使用。
这里用到了 pickle。
from sklearn import datasets from sklearn import svm import pickle # 加载数据 iris = datasets.load_iris() X, y = iris.data, iris.target # 确定算法 clf = svm.SVC() # 训练 clf.fit(X, y) # 保存训练后的模型 s = pickle.dumps(clf) # 加载之前保存的模型 clf2 = pickle.loads(s) # 预测 result = clf2.predict(X[0:1]) # 输出结果 print result print y[0]
注:pickle会有一些安全性和维护性的问题。
对于大数据而言,使用joblib.dump and joblib.load更好,它会将模型保存到磁盘中,而不仅仅只是保存成一个字符串。
from sklearn.externals import joblib # 保存模型 joblib.dump(clf, ‘filename.pkl‘) # 重新加载模型 joblib.load(‘filename.pkl‘)
#其他和pickle一样
4. 变量类型问题
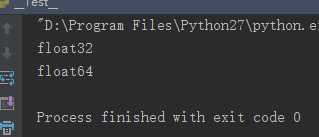
如果没有特别声明,输入将被转换成 float64:
import numpy as np from sklearn import random_projection rng = np.random.RandomState(0) X = rng.rand(10, 2000) # 定义X是float32的数组 X = np.array(X, dtype=‘float32‘) # 输出查看X的类型 print X.dtype # 利用fit_transform(X)将X的类型改变为float64 transformer = random_projection.GaussianRandomProjection() X_new = transformer.fit_transform(X) # 输出查看X_new的类型 print X_new.dtype
结果如下:
另外的一个例子:
1 from sklearn import datasets 2 from sklearn.svm import SVC 3 4 iris = datasets.load_iris() 5 clf = SVC() 6 clf.fit(iris.data, iris.target) 7 print list(clf.predict(iris.data[:3])) 8 9 clf.fit(iris.data, iris.target_names[iris.target]) 10 print list(clf.predict(iris.data[:3]))
results:
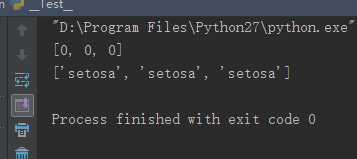
因此,第一个预测中,由于训练的目标值target是一个整型数组,所以最后的预测值也是一个整型数组。
第二个预测中,由于训练的目标值target_names是一个字符串数组,所以最后的预测值也是一个字符串数组。
5. 再训练和更新参数
import numpy as np from sklearn.svm import SVC rng = np.random.RandomState(0) X = rng.rand(100, 10) y = rng.binomial(1, 0.5, 100) X_test = rng.rand(5, 10) clf = SVC() # equal to the two sentences # clf2 = clf.set_params(kernel=‘linear‘) # clf2.fit(X, y) clf.set_params(kernel=‘linear‘).fit(X, y) print clf.predict(X_test) clf.set_params(kernel=‘rbf‘).fit(X, y) print clf.predict(X_test)
results:
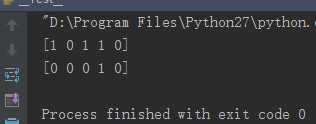
因此,我们可以看到在算法中选用不同的核函数,会产生不同的预测结果。在实际的应用中,需要不断的调整参数的值。
6. 多类标 vs 多类标拟合
当我们使用多类标分类器(multiclass classifiers)的时候,训练和预测很大程度上依赖于数据的格式。
from sklearn.svm import SVC from sklearn.multiclass import OneVsRestClassifier from sklearn.preprocessing import LabelBinarizer X = [[1, 2], [2, 4], [4, 5], [3, 2], [3, 1]] y = [0, 0, 1, 1, 2] clf = OneVsRestClassifier(estimator=SVC(random_state=0)) print clf.fit(X, y).predict(X) y = LabelBinarizer().fit_transform(y) print clf.fit(X, y).predict(X)
results:
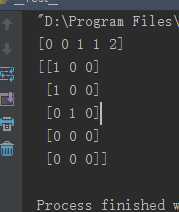
因此,对于输入是两维来说,输出也是两维的。相互对应的多类标预测。
注:第四个和第五个样例的预测值都是0,这表示它们未能匹配到任意一个类标。
同理,对多于两个类标的情况。
from sklearn.svm import SVC from sklearn.multiclass import OneVsRestClassifier from sklearn.preprocessing import MultiLabelBinarizer X = [[1, 2], [2, 4], [4, 5], [3, 2], [3, 1]] y = [[0, 1], [0, 2], [1, 3], [0, 2, 3], [2, 4]] clf = OneVsRestClassifier(estimator=SVC(random_state=0)) y = MultiLabelBinarizer().fit_transform(y) print clf.fit(X, y).predict(X)
results:
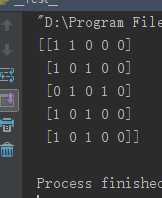
在上面的例子中,分类器对每个样例赋予多个类标。MultiLabelBinarizer 用来二值化多类标的训练数据,最终的预测结果也是一个多类标的二位数组。
参考资料:http://scikit-learn.org/stable/tutorial/basic/tutorial.html
以上是关于scikit-learn Quick Start的主要内容,如果未能解决你的问题,请参考以下文章
Commons Configuration2 - Quick start guide