php与mysql表中如何求递归求和汇总?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了php与mysql表中如何求递归求和汇总?相关的知识,希望对你有一定的参考价值。
如图所示,数据表是递归数据,每个节点是所有下一级节点之和,如何用php&mysql操作数据表,使更新最后一级数据,前一级一级数据自动更新!?

$sum = 0;
// foreach($tree as $key => $item) //这句话有毒
foreach($tree as $key => &$item)
if(isset($item[\'children\']))
$oldPshuzi = $tree[$key][\'Pshuzi\'];
$tree[$key][\'Pshuzi\'] = sumShuzi($item[\'children\'], $updateData);
if($oldPshuzi != $tree[$key][\'Pshuzi\'])
$updateData[$item[\'id\']] = array($tree[$key][\'Pshuzi\'], $tree[$key][\'Pname_ch\']);
$sum += $tree[$key][\'Pshuzi\'];
return $sum;
$tree = json_decode(\'["id":"1","Pid":"0","Pname_ch":"\\u6e20\\u9053\\u90e8","Pshuzi":"1638000","children":["id":"4","Pid":"1","Pname_ch":"\\u9500\\u552e\\u4e8c\\u90e8","Pshuzi":"895000","children":["id":"13","Pid":"4","Pname_ch":"\\u5468\\u7ecf\\u7406","Pshuzi":"28","children":["id":"28","Pid":"13","Pname_ch":"\\u6e56\\u5357","Pshuzi":"158000","id":"35","Pid":"13","Pname_ch":"\\u65b0\\u7586","Pshuzi":"19000"],"id":"40","Pid":"4","Pname_ch":"\\u9648\\u7ecf\\u7406","Pshuzi":"5000"]]]\', true);
//$tree是具有父子关系的数据树
sumShuzi($tree, $updateData);
foreach ($updateData as $id => $item)
$sql = "update your_table set Pshuzi=$item[0] where id=$id";
mysqli_query($db, $sql); //$db是你的数据库连接结果
参考技术A function get_str($id = 0)
global $str;
$sql = "select pname_ch,sum(pshuzi)as z from class where pid= $id group by pname_ch";
$result = mysql_query($sql);
if($result && mysql_affected_rows())
$str .= '<ul>';
while ($row = mysql_fetch_array($result))
$str .= "<li>" . $row['panem_ch'] . "--" . $row['z'] . "</li>";
get_str($row['id']);
$str .= '</ul>';
return $str;
给你个函数试试
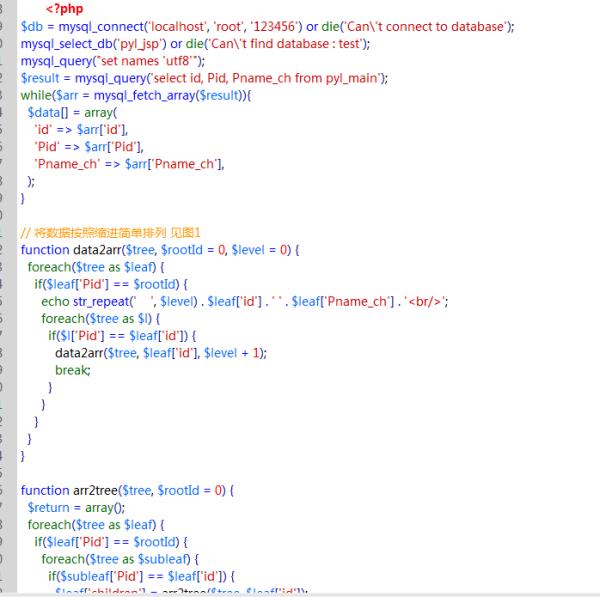
如果显示,我早已解决这个问题,现在要倒推,有点麻烦!
每更新一个最后一个节点数据,所有与之有关的上一级节点数据要联动更新!当然需要数据库操作,这样后期数据比较好处理一点,如纯js操作,不好方便后期报表制作!

那就不止无五级,理论上是N>5级
参考技术C 先明确一下需求:1:如何显示数据?
2:是否需要数据库更新操作?追问
每更新一个最后一个节点数据,所有与之有关的上一级节点数据要联动更新!当然需要数据库操作,这样比较数据处理一点,如纯js操作,不好方便后期报表制作!
Mysql经常使用函数汇总
一、 聚合函数
求和函数SUM( )用于对数据求和。返回选取结果集中全部值的总和。
语法:SELECT SUM(column_name) FROM table_name
说明:SUM()函数仅仅能作用于数值型数据。即列column_name中的数据必须是数值型的。
COUNT()函数用来计算表中记录的个数或者列中值的个数,计算内容由SELECT语句指定。
使用COUNT函数时,必须指定一个列的名称或者使用星号,星号表示计算一个表中的全部记录。
两种使用形式例如以下:
COUNT(*),计算表中行的总数,即使表中行的数据为NULL。也被计入在内。
COUNT(column),计算column列包括的行的数目。假设该列中某行数据为NULL,则该行不计入统计总数。
--使用COUNT(*)函数对表中的行数计数:
COUNT(*)函数将返回满足SELECT语句的WHERE子句中的搜索条件的函数。
--使用COUNT( )函数对一列中的数据计数:
COUNT( )函数可用于对一列中的数据值计数。
与忽略了全部列的COUNT(*)函数不同,COUNT( )函数逐一检查一列(或多列)中的值,并对那些值不是NULL的行计数。
--使用COUNT( )函数对多列中的数据计数:
COUNT( )函数不仅可用于对一列中的数据值计数,也能够对多列中的数据值计数。
假设对多列计数。则须要将要计数的多列通过连接符连接后,作为COUNT( )函数的參数。
当须要了解一列中的最大值时。能够使用MAX()函数;
相同,当须要了解一列中的最小值时,能够使用MIN()函数。
语法例如以下。
SELECT MAX (column_name) / MIN (column_name) FROM table_name
说明:列column_name中的数据能够是数值、字符串或是日期时间数据类型。
MAX()/MIN()函数将返回与被传递的列同一数据类型的单一值。
函数AVG()用于计算一列中数据值的平均值。
语法:SELECT AVG (column_name) FROM table_name
说明:AVG()函数的运行过程实际上是将一列中的值加起来,再将其和除以非NULL值的数目。
所以。与SUM( )函数一样,AVG()函数仅仅能作用于数值型数据,即列column_name中的数据必须是数值型的。
GROUP_CONCAT能够对分组后的列进行字符串的合并(拼接)。
语法:
GROUP_CONCAT (
[DISTINCT] [,expr ...] [,col_name]
[ ORDER BY {,col_name ...} [ASC | DESC] ]
[SEPARATOR str_val]
)
举例:表例如以下
中国 |1 |a
美国 |1 |b
日本 |5 |a
欧洲 |5 |c
韩国 |2 |a
非洲 |NULL |b
--SELECT GROUP_CONCAT(population) GROUP BY name
(result:1,5,2|1|5)
--SELECT GROUP_CONCAT(population ORDER BY population) GROUP BY name
(result:1,2,5|1|5)
--SELECT GROUP_CONCAT(population,‘-‘,country) GROUP BY name
(result:1-中国,2-韩国,5-日本|1-美国|5-欧洲)
--SELECT GROUP_CONCAT(
(CASE country
WHEN ‘中国‘ THEN ‘good‘
ELSE ‘bad‘
END)
,‘-‘,population) GROUP BY name
(result:good-1,bad-2,bad-5|bad-1|bad-5)
--SELECT GROUP_CONCAT(population,SEPARATOR ‘-‘) GROUP BY name
(result:1-5-2|1|5)
前面介绍的5种聚合函数。能够作用于所选列中的全部数据(无论列中的数据是否有重置),
也能够仅仅对列中的非重值进行处理,即把反复的值仅仅取一次进行聚合分析。
当然,对于MAX()/MIN()函数来讲。重值处理意义不大。
能够使用ALLkeyword指明对所选列中的全部数据进行处理,
使用DISTINCTkeyword指明对所选列中的非重值数据进行处理。
以AVG()函数为例。语法例如以下。
SELECT AVG ([ALL/DISTINCT] column_name) FROM table_name
说明:[ALL/DISTINCT]在缺省状态下,默认是ALLkeyword。
即无论是否有重值,处理全部数据。其它聚合函数的使用方法与此同样。
二、 数学函数
ABS(x) 返回x的绝对值
BIN(x) 返回x的二进制(OCT返回八进制,HEX返回十六进制)
CEILING(x) 返回大于x的最小整数值
EXP(x) 返回值e(自然对数的底)的x次方
FLOOR(x) 返回小于x的最大整数值
GREATEST(x1,x2,...,xn)返回集合中最大的值
LEAST(x1,x2,...,xn) 返回集合中最小的值
LN(x) 返回x的自然对数
LOG(x,y)返回x的以y为底的对数
MOD(x,y) 返回x/y的模(余数)
PI()返回pi的值(圆周率)
RAND()返回0到1内的随机值,能够通过提供一个參数(种子)使RAND()随机数生成器生成一个指定的值。
ROUND(x,y)返回參数x的四舍五入的有y位小数的值
SIGN(x) 返回代表数字x的符号的值
SQRT(x) 返回一个数的平方根
TRUNCATE(x,y) 返回数字x截短为y位小数的结果
三、 字符串函数
ASCII(char)返回字符的ASCII码值
BIT_LENGTH(str)返回字符串的比特长度
CONCAT(s1,s2...,sn)将s1,s2...,sn连接成字符串
CONCAT_WS(sep,s1,s2...,sn)将s1,s2...,sn连接成字符串。并用sep字符间隔
INSERT(str,x,y,instr) 将字符串str从第x位置開始,y个字符长的子串替换为字符串instr。返回结果
FIND_IN_SET(str,list)分析逗号分隔的list列表,假设发现str,返回str在list中的位置
LCASE(str)或LOWER(str) 返回将字符串str中全部字符改变为小写后的结果
LEFT(str,x)返回字符串str中最左边的x个字符
LENGTH(s)返回字符串str中的字符数
LTRIM(str) 从字符串str中切掉开头的空格
POSITION(substr,str) 返回子串substr在字符串str中第一次出现的位置
QUOTE(str) 用反斜杠转义str中的单引號
REPEAT(str,srchstr,rplcstr)返回字符串str反复x次的结果
REVERSE(str) 返回颠倒字符串str的结果
RIGHT(str,x) 返回字符串str中最右边的x个字符
RTRIM(str) 返回字符串str尾部的空格
STRCMP(s1,s2)比較字符串s1和s2
TRIM(str)去除字符串首部和尾部的全部空格
UCASE(str)或UPPER(str) 返回将字符串str中全部字符转变为大写后的结果
四、日期和时间函数
--CURDATE()或CURRENT_DATE() 返回当前的日期,比如‘2015-07-27‘
--CURTIME()或CURRENT_TIME() 返回当前的时间,比如‘09:36:23‘
--NOW()或CURRENT_TIMESTAMP()或SYSDATE() 返回当前日期时间,比如‘2015-07-27 09:37:11‘
--UNIX_TIMESTAMP(date)
假设没有參数调用,返回一个Unix时间戳记(从‘1970-01-01 00:00:00‘GMT開始的秒数)。
假设UNIX_TIMESTAMP()用一个date參数被调用。它返回从‘1970-01-01 00:00:00‘ GMT開始的秒数值。
date能够是一个DATE字符串、一个DATETIME字符串、一个TIMESTAMP或以YYMMDD或YYYYMMDD格式的本地时间的一个数字。
样例:SELECT UNIX_TIMESTAMP();//结果1437965279
样例:SELECT UNIX_TIMESTAMP(‘1997-10-04 22:23:00‘); //结果875996580
--FROM_UNIXTIME(unix_timestamp)
以‘YYYY-MM-DD HH:MM:SS‘或YYYYMMDDHHMMSS格式返回unix_timestamp參数所表示的值,
取决于函数是在一个字符串还是或数字上下文中被使用。
样例:SELECT FROM_UNIXTIME(875996580);//‘1997-10-04 22:23:00‘
样例:select FROM_UNIXTIME(875996580) + 0;//19971004222300
--FROM_UNIXTIME(unix_timestamp,format)
返回表示 Unix 时间标记的一个字符串,依据format字符串格式化。
format能够包括与DATE_FORMAT()函数列出的条目相同的修饰符。
详细參考以下format表.
样例:SELECT FROM_UNIXTIME(UNIX_TIMESTAMP(),‘%Y %D %M %h:%i:%s‘);//‘2015 27th July 10:53:29‘
--SEC_TO_TIME(seconds)
返回seconds參数。变换成小时、分钟和秒。值以‘HH:MM:SS‘或HHMMSS格式化。
取决于函数是在一个字符串还是在数字上下文中被使用。
样例:SELECT SEC_TO_TIME(2378);//‘00:39:38‘
样例:SELECT SEC_TO_TIME(2378) + 0; //3938
--TIME_TO_SEC(time)
返回time參数,转换成秒。
样例:SELECT TIME_TO_SEC(‘22:23:00‘);//80580v
样例:SELECT TIME_TO_SEC(‘00:39:38‘); //2378
--ADDDATE或DATE_ADD(date,INTERVAL expr type)
--SUBDATE或DATE_SUB(date,INTERVAL expr type)
--EXTRACT(type FROM date)函数从日期中返回“type”间隔
expr是指定加到開始日期或从開始日期减去的间隔值一个表达式,expr是一个字符串;
它能够以一个“-”開始表示负间隔。
type是一个关键词。指明表达式应该怎样被解释。
MINUTE 分钟 MINUTES
HOUR 时间 HOURS
DAY 天 DAYS
MONTH 月 MONTHS
YEAR 年 YEARS
MINUTE_SECOND 分钟和秒 "MINUTES:SECONDS"
HOUR_MINUTE 小时和分钟 "HOURS:MINUTES"
DAY_HOUR 天和小时 "DAYS HOURS"
YEAR_MONTH 年和月 "YEARS-MONTHS"
HOUR_SECOND 小时, 分钟, "HOURS:MINUTES:SECONDS"
DAY_MINUTE 天, 小时, 分钟 "DAYS HOURS:MINUTES"
DAY_SECOND 天, 小时, 分钟, 秒 "DAYS HOURS:MINUTES:SECONDS"
(1)SELECT DATE_ADD(NOW(),INTERVAL 60 SECOND);//间隔60秒
(2)SELECT DATE_ADD(NOW(),INTERVAL "2:20" MINUTE_SECOND);//间隔2分钟60秒
(3)SELECT DATE_SUB("1998-01-01 00:00:00",INTERVAL "-1 1 1" DAY_SECOND);
//间隔一小时一分一秒,天数为空 默认取0.expr前可加"-"
(4)SELECT EXTRACT(HOUR_SECOND FROM NOW());//结果102111,表示10点21分11秒.
--PERIOD_ADD(P,N)
添加N个月到阶段P(以格式YYMM或YYYYMM)。以格式YYYYMM返回值。
注意阶段參数P不是日期值。
样例:SELECT PERIOD_ADD(9801,2);//结果199803
--PERIOD_DIFF(P1,P2)
返回在时期P1和P2之间月数,P1和P2应该以格式YYMM或YYYYMM。注意,时期參数P1和P2不是日期值。
样例:SELECT PERIOD_DIFF(9802,199703);//结果11
--TO_DAYS(date) 给出一个日期date,返回一个天数(从0年的天数)。
样例:SELECT TO_DAYS(950501);//结果728779
样例:SELECT TO_DAYS(‘1997-10-07‘); //结果729669
--FROM_DAYS(N)
给出一个天数N,返回一个DATE值。
样例:SELECT FROM_DAYS(366);//结果0001-01-01
--DATE_FORMAT(date,fmt) 按照指定的fmt格式格式化日期date值.
--TIME_FORMAT(time,format)处理包括小时、分钟和秒的那些格式修饰符。其它修饰符产生一个NULL值或0。
%W 星期名字(Sunday……Saturday)
%D 有英语前缀的月份的日期(1st, 2nd, 3rd, 等等。
)
%Y 年, 数字, 4 位
%y 年, 数字, 2 位
%a 缩写的星期名字(Sun……Sat)
%d 月份中的天数, 数字(00……31)
%e 月份中的天数, 数字(0……31)
%m 月, 数字(01……12)
%c 月, 数字(1……12)
%b 缩写的月份名字(Jan……Dec)
%j 一年中的天数(001……366)
%H 小时(00……23)
%k 小时(0……23)
%h 小时(01……12)
%I 小时(01……12)
%l 小时(1……12)
%i 分钟, 数字(00……59)
%r 时间,12 小时(hh:mm:ss [AP]M)
%T 时间,24 小时(hh:mm:ss)
%S 秒(00……59)
%s 秒(00……59)
%p AM或PM
%w 一个星期中的天数(0=Sunday ……6=Saturday )
%U 星期(0……52), 这里星期天是星期的第一天
%u 星期(0……52), 这里星期一是星期的第一天
%% 一个文字“%”。
--DAYOFYEAR(date) 返回date是一年的第几天(1~366)
样例:SELECT DAYOFYEAR(‘2015-07-27‘);//208
--DAYOFMONTH(date)或DAY() 返回date是一个月的第几天(1~31)
样例:SELECT DAYOFMONTH(‘2015-07-27‘);//27
--DAYOFWEEK(date) 返回date所代表的一星期中的第几天(1~7)
样例:SELECT DAYOFWEEK(‘2015-07-27‘);//2星期一为第二天.
--WEEKDAY(date) 返回date的星期索引(0=星期一,1=星期二, ……6= 星期天)。
样例:SELECT WEEKDAY(‘2015-07-27 10:09:08‘);//0表示星期一
--DAYNAME(date) 返回date的星期名.
样例:SELECT DAYNAME(‘2015-07-27 10:09:08‘);//Monday
--MONTHNAME(date) 返回date的月份名.
样例:SELECT MONTHNAME(‘2015-07-27 10:09:08‘);//July
--LAST_DAY(date )
函数使用说明:获取一个日期或日期时间值,返回该月最后一天相应的值。
若參数无效。则返回 NULL 。
样例:SELECT LAST_DAY(‘2015-02-1 10:09:08‘);//2015-02-28
--YEAR(date) 返回日期date的年份(1000~9999)
样例:SELECT YEAR(‘2015-07-27 10:09:08‘);//2015
--QUARTER(date) 返回date在一年中的季度(1~4)
样例:SELECT QUARTER(‘2015-07-27 10:09:08‘);//3
--MONTH(date) 返回date的月份值(1~12)
样例:SELECT MONTH(‘2015-07-27 10:09:08‘);//7
--WEEK(date) 返回日期date为一年中第几周(0~52)
样例:SELECT WEEK(‘2015-07-27 10:09:08‘);//30
--WEEK(date,first)
对于星期天是一周的第一天的地方,有一个单个參数。返回date的周数。
范围在0到52。2个參数形式WEEK()同意你指定星期是否開始于星期天或星期一。
假设第二个參数是0,星期从星期天開始。假设第二个參数是1,从星期一開始。
样例:SELECT WEEK(‘2015-07-27 10:09:08‘,1);//31
--HOUR(time) 返回time的小时值(0~23)
样例:SELECT HOUR(‘2015-07-27 10:09:08‘);//10
--MINUTE(time) 返回time的分钟值(0~59)
样例:SELECT MINUTE(‘2015-07-27 10:09:08‘);//9
--SECOND(time) 返回time的秒数,范围是0到59。
样例:SELECT SECOND(‘2015-07-27 10:09:08‘);//8
五、控制流函数
CASE WHEN[test1] THEN [result1]...ELSE [default] END假设testN是真,则返回resultN。否则返回default
CASE [test] WHEN[val1] THEN [result]...ELSE [default]END 假设test和valN相等,则返回resultN。否则返回default
IF(test,t,f) 假设test是真,返回t;否则返回f
IFNULL(arg1,arg2) 假设arg1不是空,返回arg1。否则返回arg2
NULLIF(arg1,arg2) 假设arg1=arg2返回NULL;否则返回arg1
原创来自:http://beadlechen.github.io/content/blog.html#category=software#article=mysql_function
以上是关于php与mysql表中如何求递归求和汇总?的主要内容,如果未能解决你的问题,请参考以下文章
如何把EXCEL表中的数据进行按多个条件进行分类汇总,并统计出个数,并求和?