设计模式总结对常用设计模式的一些思考(未完待续。。。)
Posted 五月的仓颉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了设计模式总结对常用设计模式的一些思考(未完待续。。。)相关的知识,希望对你有一定的参考价值。
前言
在【Java设计模式】系列中,LZ写了十几篇关于设计模式的文章,大致是关于每种设计模式的作用、写法、优缺点、应用场景。
随着LZ自身的成长,再加上在工作中会从事一定的架构以及底层代码设计的原因,在近半年的实践中,对于设计模式的理解又有了新的认识,因此有了此文,目的是和网友朋友们分享自己对于设计模式的一些思考。LZ本人水平有限,抛砖引玉,写得不对的地方希望网友朋友们指正,也可留言相互讨论。
设计模式用不用?如何用?
标题是两个问题:
1、什么情况下使用设计模式?
2、使用哪种设计模式?
首先回答一下对于第一个问题我的个人理解:
对于代码来说,即使完全不使用设计模式,也是可以将整个流程写出来,将整个功能实现出来。
使用设计模式的内因,主要来源于开发者对于设计模式本身的理解,因此谈论这个问题,首先要自问:我了解或者说熟悉几种设计模式?毕竟,懂都不懂,如何使用设计模式?
使用设计模式的外因,主要来源于开发者对于代码可维护性、可扩展性的理解。比如使用某个类调用方法,不存在线程安全的问题,可以考虑单例模式,避免对象重复创建;比如多重if...else,可以尝试提取公共的返回,使用工厂模式。
对于第二个问题的回答,首先是基于第一个问题的,在第一个问题回答的基础上,如何用设计模式我再提出一点个人的见解:
使用设计模式最怕的是把简单问题复杂化,为了使用设计模式而使用设计模式。
需要注意的是,使用设计模式,是为了提高代码的可用性、可维护性、扩展性,而不是为了展示个人的技术有多么高深。代码写出来最终还是要给别人看,可能写这段代码的人不在了,需要给别人维护的,因此切记,适当的地方使用适当的设计模式,不一定非得用上设计模式。至于具体如何用,就看个人水平的高低以及实践经验的多少了,当然必不可少的,还有平时的思考与总结。
另外,有一个比较实用的技巧,使用设计模式的时候,将类的命名体现出设计模式的思想,比如*Proxy、*Factory、*Observer,这样会让他人更方便地可以理解你代码的意图。
抽象类还是接口?
大多数的设计模式,都是通过引入抽象层,将模块与模块之间解耦实现的。这里的抽象层,在Java中的表现就是抽象类或者接口,尽管每种设计模式都有一定的套路(固定写法),但是必然也要随着需求的变化而变化,并不是套路是什么就怎么写。那么我们在设计模式具体写的时候,应该使用的到底是抽象类还是接口呢?说一下我的看法。
首先,从一个比较理论的角度来分析这个问题,从抽象类和接口语义来看:
- 抽象类表示的是一种A是B的关系
- 接口表示的是一种A有B的行为的关系
所以,碰到具体的情况,可以先分析一下,你抽象出来的模块之间的关系表示的是一种什么是什么的关系,还是什么有什么的行为的关系。
当然,大多数情况下,上面的分析法,是分析不出来到底使用抽象类还是接口的,因为太理论了,从实践的角度来看,使用抽象类或者接口,我们可以考虑几个问题:
- 优先使用接口,因为接口是一种完全的抽象且接口允许多实现
- 你抽象出来的核心模块中,有没有实例字段?
- 你抽象出来的核心模块中,需不需要普通方法?
- 你抽象出来的核心模块中,需不需要构造函数进行必要的传参?
如果后三点在你抽象出来的核心模块中,必须要使用到其中的一点或者几点,那么就是用抽象类,否则,接口必然是一种更好的选择。
简单工厂模式
首先是简单工厂模式。
对于简单工厂模式的作用描述,LZ当时是这么写的:
原因很简单:解耦。 A对象如果要调用B对象,最简单的做法就是直接new一个B出来。这么做有一个问题,假如C类和B类实现了同一个接口/继承自同一个类,系统需要把B类修改成C类,程序不得不重写A类代码。如果程序中有100个地方new了B对象,那么就要修改100处。 这就是典型的代码耦合度太高导致的"牵一发动全身"。所以,有一个办法就是写一个工厂IFactory,A与IFactory耦合,修改一下,让所有的类都实现C接口并且IFactory生产出C的实例就可以了。
感谢@一线码农的指正,原来我以为这段话是有问题的,现在仔细思考来看这段话没问题。举个最简单的代码例子,定义一个工厂类:
1 public class ObjectFactory { 2 3 public static Object getObject(int i) { 4 if (i == 1) { 5 return new Random(); 6 } else if (i == 2) { 7 return Runtime.getRuntime(); 8 } 9 10 return null; 11 } 12 13 }
调用方假如不使用工厂模式,那么我定义一段代码:
1 public class UseObject { 2 3 public void funtionA() { 4 Object obj = new Random(); 5 } 6 7 public void funtionB() { 8 Object obj = new Random(); 9 } 10 11 public void funtionC() { 12 Object obj = new Random(); 13 } 14 15 }
假如现在我不想用Random类了,我想用Runtime类了,此时三个方法都需要把"Object obj = new Random()"改为"Object obj = Runtime.getRuntime();",如果类似的代码有100处、1000处,那么得改100处、1000处,非常麻烦,使用了工厂方法就不一样了,调用方完全可以这么写:
1 public class UseObject { 2 3 private static Properties properties; 4 5 static { 6 // 加载配置文件 7 } 8 9 public void funtionA() { 10 Object obj = ObjectFactory.getObject(Integer.parseInt(properties.getProperty("XXX"))); 11 } 12 13 public void funtionB() { 14 Object obj = ObjectFactory.getObject(Integer.parseInt(properties.getProperty("XXX"))); 15 } 16 17 public void funtionC() { 18 Object obj = ObjectFactory.getObject(Integer.parseInt(properties.getProperty("XXX"))); 19 } 20 21 }
搞一个配置文件,每次调用方从配置文件中读出一个枚举值,然后根据这个枚举值去ObjectFactory里面拿一个Object对象实例出来。这样,未来不管是3处还是100处、1000处,如果要修改,只需要修改一次配置文件即可,不需要所有地方都修改,这就是使用工厂模式带来的好处。
不过简单工厂模式这边自身还有一个小问题,就是如果工厂这边新增加了一种对象,那么工厂类必须同步新增if...else...分支,不过这个问题对于Java语言不难解决,只要定义好包路径,完全可以通过反射的方式获取到新增的对象而不需要修改工厂自身的代码。
上面的讲完,LZ觉得简单工厂模式的主要作用还有两点:
(1)隐藏对象构造细节
(2)分离对象使用方与对象构造方,使得代码职责更明确,使得整体代码结构更优雅
先看一下第一点,举几个例子,比如JDK自带的构造不同的线程池,最终获取到的都是ExecutorService接口实现类:
1 @Test 2 public void testExecutors() { 3 ExecutorService es1 = Executors.newCachedThreadPool(); 4 ExecutorService es2 = Executors.newFixedThreadPool(10); 5 ExecutorService es3 = Executors.newSingleThreadExecutor(); 6 System.out.println(es1); 7 System.out.println(es2); 8 System.out.println(es3); 9 }
这个方法构造线程池是比较简单的,复杂的比如Spring构造一个Bean对象:
1 @Test 2 public void testSpring() { 3 ClassPathXmlApplicationContext applicationContext = new ClassPathXmlApplicationContext("classpath:spring.xml"); 4 Object obj = applicationContext.getBean(Object.class); 5 System.out.println(obj); 6 7 applicationContext.close(); 8 9 }
中间流程非常长(有兴趣的可以看下我写的Spring源码分析的几篇文章),构造Bean的细节不需要也没有必要暴露给Spring使用者(当然那些想要研究框架源代码以便更好地使用框架的除外),使用者关心的只是调用工厂类的某个方法可以获取到想要的对象即可。
至于前面说的第二点,可以用设计模式六大原则的单一职责原则来理解:
单一职责原则(SRP): 1,SRP(Single Responsibilities Principle)的定义:就一个类而言,应该仅有一个引起它变化的原因。简而言之,就是功能要单一 2,如果一个类承担的职责过多,就等于把这些职责耦合在一起,一个职责的变化可能会削弱或者抑制这个类完成其它职责的能力。这种耦合会导致脆弱的设计,当变化发生时,设计会遭受到意想不到的破坏 3,软件设计真正要做的许多内容,就是发现职责并把那些职责相互分离
把这段话加上我的理解就是:该使用的地方只关注使用,该构造对象的地方只关注构造对象,不需要把两段逻辑联系在一起,保持一个类或者一个方法100~200行左右的代码量,能描述清楚要做的一件事情即可。
单例模式
第二点讲讲单例模式。
拿我比较喜欢的饿汉式单例模式的写法举例吧:
1 public class Object { 2 3 private static final Object instance = new Object(); 4 5 private Object() { 6 7 } 8 9 public static Object getInstance() { 10 return instance; 11 } 12 13 public void functionA() { 14 15 } 16 17 public void functionB() { 18 19 } 20 21 public void functionC() { 22 23 } 24 25 }
然后我们调用的时候,会使用如下的方式调用functionA()、functionB()、functionC()三个方法:
1 @Test 2 public void testSingleton() { 3 Object.getInstance().functionA(); 4 Object.getInstance().functionB(); 5 Object.getInstance().functionC(); 6 }
这么做是没有问题,使用单例模式可以保证Object类在对象池(也就是堆)中只被创建一次,节省了系统的开销。但是问题是:是否需要使用单例模式,为什么一定要把Object这个对象实例化出来?
意思是Java里面有static关键字,如果将functionA()、functionB()、functionC()都加上static关键字,那么调用方完全可以使用如下方式调用:
1 @Test 2 public void testSingleton() { 3 Object.functionA(); 4 Object.functionB(); 5 Object.functionC(); 6 }
对象都不用实例化出来了,岂不是更加节省空间?
这个问题总结起来就到了使用static关键字调用方法和使用单例模式调用方法的区别上了,关于这两种做法有什么区别,我个人的看法是没什么区别。所谓区别,说到底,也就是两种,哪种消耗内存更少,哪种调用效率更高对吧,逐一看一下:
- 从内存消耗上来看,真没什么区别,static方法也好,实例方法也好,都是占用一定的内存的,但这些方法都是类初始化的时候被加载,加载完毕被存储在方法区中
- 从调用效率上来看,也没什么区别,方法最终在解析阶段被翻译为直接引用,存储在方法区中,然后调用方法的时候拿这个直接引用去调用方法(学过C、C++的可能会比较好理解这一点,这叫做函数指针,意思是每个方法在内存中都有一个地址,可以直接通过这个地址拿到方法的起始位置,然后开始调用方法)
所以,无论从内存消耗还是调用效率上,通过static调用方法和通过单例模式调用方法,都没多大区别,所以,我认为这种单例的写法,也是完全可以把所有的方法都直接写成静态的。使用单例模式,无非是更加符合面向对象(OO)的编程原则而已。
写代码这个事情,除了让代码更优雅、更简洁、更可维护、更可复用这些众所周知的之外,不就是图个简单吗,怎么写得简单怎么来,所以用哪种方式调用方法在我个人看来真的是纯粹看个人喜好,说一下我个人的原则:整个类代码比较少的,一两百行乃至更少的,使用static直接调方法,不实例化对象;整个类代码比较多的,逻辑比较复杂的,使用单例模式。
毕竟,单例单例,这个对象还是存在的,那必然可以继承。整个类代码比较多的,其中有一个或者多个方法不符合我当前业务逻辑,没法继承,使用静态方法直接调用的话,得把整个类都复制一遍,然后改其中几个方法,相对麻烦;使用单例的话,其中有一个或者多个方法不符合我当前业务逻辑,直接继承一下改这几个方法就可以了。类代码比较少的类,反正复制黏贴改一下也无所谓。
模板模式
接着是模板模式,模板模式我本人并没有专门写过文章,因此这里网上找了一篇我认为把模板模式讲清楚的文章。
对于一个架构师、CTO,反正只要涉及到写底层代码的程序员而言,模板模式都是非常重要的。模板模式简单说就是代码设计人员定义好整个代码处理流程,将变化的地方抽象出来,交给子类去实现。根据我自己的经验,模板模式的使用,对于代码设计人员来说有两个难点:
(1)主流程必须定义得足够宽松,保证子类有足够的空间去扩展
(2)主流程必须定义得足够严谨,保证抽离出来的部分都是关键的部分
这两点看似有点矛盾,其实是不矛盾的。第一点是站在扩展性的角度而言,第二点是站在业务角度而言的。假如有这么一段模板代码:
1 public abstract class Template { 2 3 protected abstract void a(); 4 protected abstract void b(); 5 protected abstract void c(); 6 7 public void process(int i, int j) { 8 if (i == 1 || i == 2 || i == 3) { 9 a(); 10 } else if (i == 4 || i == 5 || i == 6) { 11 if (j > 1) { 12 b(); 13 } else { 14 a(); 15 } 16 } else if (i == 6) { 17 if (j < 10) { 18 c(); 19 } else { 20 b(); 21 } 22 } else { 23 c(); 24 } 25 } 26 27 }
我不知道这段代码例子举得妥当不妥当,但我想说说我想表达的意思:这段模板代码定义得足够严谨,但是缺乏扩展性。因为我认为在抽象方法前后加太多的业务逻辑,比如太多的条件、太多的循环,会很容易将一些需要抽象让子类自己去实现的逻辑放在公共逻辑里面,这样会导致两个问题:
(1)抽象部分细分太厉害,导致扩展性降低,子类只能按照定义死的逻辑去写,比如a()方法中有一些值需要在c()方法中使用就只能通过ThreadLocal或者某些公共类去实现,反而增加了代码的难度
(2)子类发现该抽象的部分被放到公共逻辑里面去了,无法完成代码要求
最后提一点,我认为模板模式对梳理代码思路是非常有用的。因为模板模式的核心是抽象,因此在遇到比较复杂的业务流程的时候,不妨尝试一下使用模板模式,对核心部分进行抽象,以梳理逻辑,也是一种不错的思路,至少我用这种方法写出过一版比较复杂的代码。
策略模式
策略模式,一种可以认为和模板模式有一点点像的设计模式,至于策略模式和模板模式之间的区别,后面视篇幅再聊。
策略模式其实比较简单,但是在使用中我有一点点的新认识,举个例子吧:
1 public void functionA() { 2 // 一段逻辑,100行 3 4 System.out.println(); 5 System.out.println(); 6 System.out.println(); 7 System.out.println(); 8 System.out.println(); 9 System.out.println(); 10 }
一个很正常的方法funtionA(),里面有段很长(就假设是这里的100行的代码),以后改代码的时候发现这100行代码写得有点问题,这时候怎么办,有两种做法:
(1)直接删除这100行代码。但是直接删除的话,有可能后来写代码的人想查看以前写的代码,怎么办?肯定有人提出用版本管理工具SVN、Git啊,不都可以查看代码历史记录吗?但是,一来这样比较麻烦每次都要查看代码历史记录,二来如果当时的网络不好无法查看代码历史记录呢?
(2)直接注释这100行代码,在下面写新的逻辑。这样的话,可以是可以查看以前的代码了,但是长长的百行注释放在那边,非常影响代码的可读性,非常不推荐
这个时候,就推荐使用策略模式了,这100行逻辑完全可以抽象为一段策略,所有策略的实现放在一个package下,这样既把原有的代码保留了下来,可以在同一个package下方便地查看,又可以根据需求更换策略,非常方便。
应网友朋友要求,补充一下代码,这样的,functionA()可以这么改,首先定义一段抽象策略:
1 package org.xrq.test.design.strategy; 2 3 public interface Strategy { 4 5 public void opt(); 6 7 }
然后定义一个策略A:
1 package org.xrq.test.design.strategy.impl; 2 3 import org.xrq.test.design.strategy.Strategy; 4 5 public class StrategyA implements Strategy { 6 7 @Override 8 public void opt() { 9 10 } 11 12 }
用的时候这么使用:
1 public class UseStrategy { 2 3 private Strategy strategy; 4 5 public UseStrategy(Strategy strategy) { 6 this.strategy= strategy; 7 } 8 9 public void function() { 10 strategy.opt(); 11 12 System.out.println(); 13 System.out.println(); 14 System.out.println(); 15 System.out.println(); 16 System.out.println(); 17 System.out.println(); 18 } 19 20 }
使用UseStrategy类的时候,只要在构造函数中传入new StrategyA()即可。此时,如果要换策略,可以在同一个package下定义一个策略B:
1 package org.xrq.test.design.strategy.impl; 2 3 import org.xrq.test.design.strategy.Strategy; 4 5 public class StrategyB implements Strategy { 6 7 @Override 8 public void opt() { 9 10 } 11 12 }
使用使用UseStrategy类的时候,需要更换策略,可在构造函数中传入new StrategyB()。这样一种写法,就达到了我说的目的:
1、代码的实现更加优雅,调用方只需要传入不同的Strategy接口的实现即可
2、原有的代码被保留了下来,因为所有的策略都放在同一个package下,可以方便地查看原来的代码是怎么写的
适配器模式
适配器模式,这种设计模式有一定的写法,但是从我的实践经验以及对Jdk源码阅读的思考来说,适配器模式以一种思想的角度来理解似乎更为合适,其思想的核心就是:将一个接口通过某种方式转换为另一种接口。
比如我们说到Java IO使用了适配器模式,典型场景就是字节流和字符流的转换,看一下源码:
1 public class InputStreamReader extends Reader { 2 3 private final StreamDecoder sd; 4 5 /** 6 * Creates an InputStreamReader that uses the default charset. 7 * 8 * @param in An InputStream 9 */ 10 public InputStreamReader(InputStream in) { 11 super(in); 12 try { 13 sd = StreamDecoder.forInputStreamReader(in, this, (String)null); // ## check lock object 14 } catch (UnsupportedEncodingException e) { 15 // The default encoding should always be available 16 throw new Error(e); 17 } 18 } 19 20 ....
看到,输入的是一个InputStream即字节输入流,但输出的是InputStreamReader即字符输入流,两个接口的转换是通过StreamDecoder来进行转换的,但是这里我们说字节流与字符流的转换使用到了适配器模式。
再比如说Arrays这个数组工具类,可传入一个数组,返回一个List:
1 public static <T> List<T> asList(T... a) { 2 return new ArrayList<>(a); 3 }
这里实现了数组(T... a这种不可变参数的写法,在JVM层面就是转换为数组进行处理的)到接口的转换,我们也认为是一种适配器模式。
就这两个例子来看,并没有遵从适配器模式的写法,所以,我认为不用太过于纠结适配器模式的写法,将适配器模式换一个角度,认为是一种思想,或许能更好地理解Java中的适配器。
装饰器模式与代理模式的差别
代理模式与装饰器模式,我在博客里面都有写过相关的文章,比较详细地写明了两种设计模式是什么、如何写。观察仔细或者喜欢思考的朋友们一定会注意到这两种设计模式是非常相似的两种设计模式,其核心归纳起来都可以表示为这样一种流程:
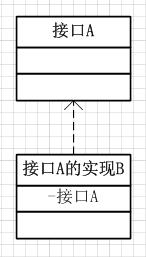
解释起来就是三句话:
- 定义一个顶层的抽象
- 实现顶层的抽象
- 实现顶层的的类中持有顶层抽象的一个引用
因此,这两种设计模式的实现机制基本是一致的。既然如此,那么他们的区别在哪呢?就这个问题说说我个人的思考,分别是从使用和语义的角度来说。
从使用的角度来说:
- 装饰器模式通过构造函数递归地创建对象
- 代理模式(动态代理,静态代理一来不常用、二来和装饰器模式差不多)通过Jdk自带的InvocationHandler与Proxy创建被代理对象的代理对象,并通过代理对象控制被代理对象的访问
从语义的角度来说:
- 装饰器模式强调的是给对象增加功能
- 代理模式强调的是控制对象的访问
举个例子,一个西瓜:
- 我们可以给西瓜加上冰,成为冰镇西瓜,让西瓜更可口,这是装饰,我们不会说加冰这个动作是为了控制西瓜的访问
- 我们买西瓜可以通过中间商帮我们去买,因为有可能以更便宜的价格拿到西瓜,这是代理,我们不会说中间商增加了西瓜的功能,因为西瓜还是那个西瓜
因此,相当于说代理模式,被代理对象功能没有变化,还是那个功能;装饰器模式,被装饰对象的功能是增强了的。
从问题的语义上,我们应当比较好判断应当使用装饰器模式还是代理模式去解决此问题。
结语
IT圈流传着一句话:“Talk is cheap,show me the code”。本文的内容都是基于个人平时工作经验,对于设计模式使用的总结,一切来源于实践又回归于实践,网友朋友们平时一定要多用、多想,一定会有更大的收获,对设计模式也才会有更多的思考。
以上是关于设计模式总结对常用设计模式的一些思考(未完待续。。。)的主要内容,如果未能解决你的问题,请参考以下文章