线上es报错异常分析
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了线上es报错异常分析相关的知识,希望对你有一定的参考价值。
参考技术A 起因:订单日志没有保存到es解决流程:
查看book3-message的报错日志
发现如下两种异常
第一种异常:
线程池的问题,EsThreadPoolExecutor[bulk, queue capacity = 50, org.elasticsearch.common.util.concurrent.EsThreadPoolExecutor@5e6ba269[Running, pool size = 16, active threads = 16, queued tasks = 56, completed tasks = 41706906]]];];req:org.elasticsearch.action.bulk.BulkRequestBuilder@27779be
修改了es的线程池配置,线程池的最大数要小于等于es所在服务器的cpu数量;
参考文档: https://www.cnblogs.com/kangoroo/p/7615833.html
第二种异常:
数据更新时版本不一致导致;解决方式:将更新es数据的方式从UpdateRequestBuilder改成UpdateByQueryRequestBuilder这种方式,主要是设置abortOnVersionConflict(false)这个参数;
参考文档:
https://blog.csdn.net/zhou_shaowei/article/details/80079162 为了防止版本冲突导致updateByQuery中止,设置终止冲突(false)
https://blog.csdn.net/qq_37502106/article/details/80604538
一次线程池引发的线上故障分析
点击关注“有赞coder”
获取更多技术干货哦~

一、问题背景
线上监控到大量接口报错,定位到异常机器,将异常机器隔离后,线上服务恢复正常。拿到业务报错日志如下:
 异常信息显示Dubbo线程池活跃线程数已经达到最大线程数200,说明线程池资源已经耗尽。
异常信息显示Dubbo线程池活跃线程数已经达到最大线程数200,说明线程池资源已经耗尽。
二、问题排查
线程池资源耗尽,猜测Dubbo线程都被某个耗时方法阻塞了,或者线上有异常突发流量。
查看线上监控,发现服务请求流量正常,猜测Dubbo线程是被阻塞住了。
2.1 Dubbo线程为何被阻塞?
通过 jstack获取Dubbo线程堆栈信息,发现大量Dubbo线程的线程状态都为WAITING状态,阻塞在 CompletableFuture#join。
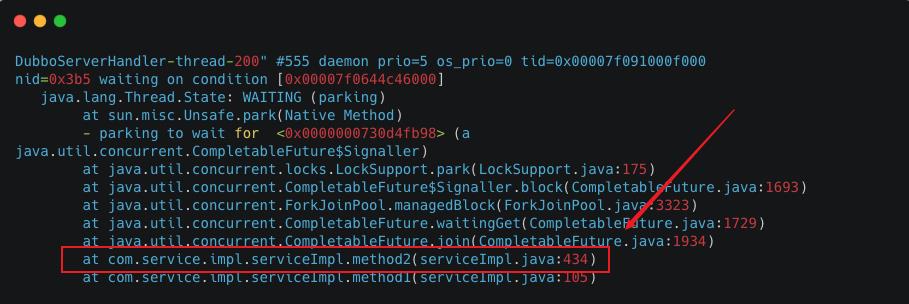 找到相关代码行,简化逻辑如下:
找到相关代码行,简化逻辑如下:
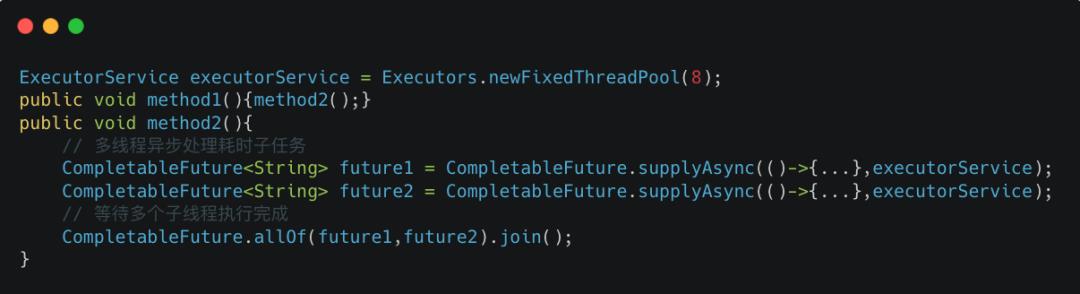
业务代码中自定义了一个线程数为8的固定线程池 executorService,为了方便表述,该线程池简称业务线程池,分配的线程简称业务线程。method2通过从该线程池中获取线程执行多个耗时的子任务,并 join阻塞等待多个线程执行结束。
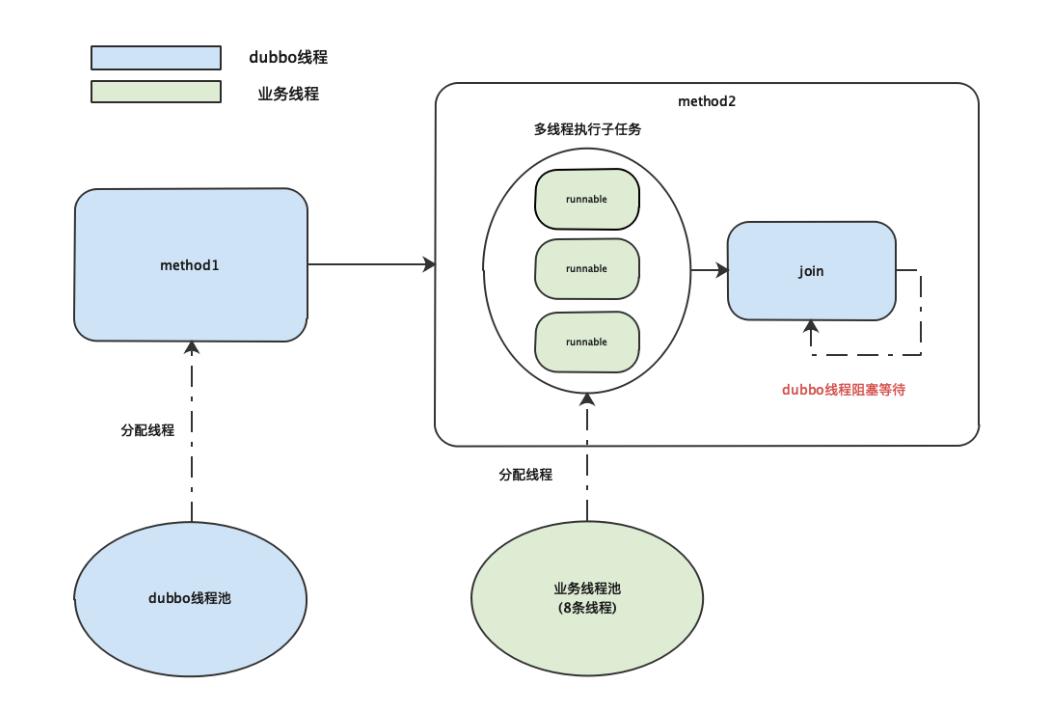 当接收到一个请求时,由Dubbo线程池分配线程执行
当接收到一个请求时,由Dubbo线程池分配线程执行 method1方法, method1调用 method2, method2从业务线程池中获取线程去执行子任务,并阻塞等待。
Dubbo线程都阻塞在method2,那么说明method2中的多个子任务一直没有执行完成,导致Dubbo线程一直阻塞等待。
那么method2中的子任务为什么一直没有执行完?是因为子任务执行得太慢吗?还是业务线程池出了什么问题?
2.2 子任务为什么一直没执行完成?
分析业务线程堆栈信息,发现8个业务线程都处于 WAITING状态,阻塞在 CompletableFuture#join方法。
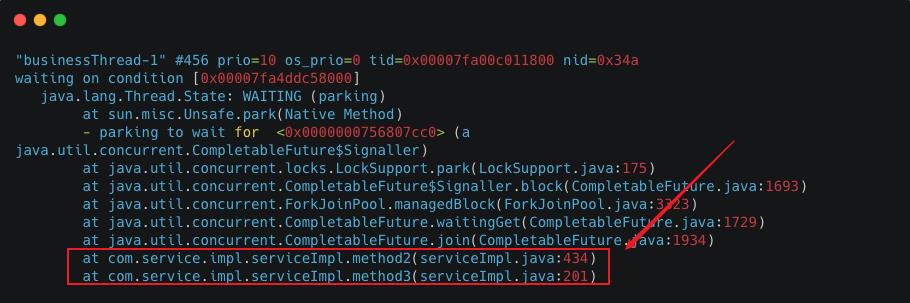 通过业务线程堆栈信息找到相关代码,并将代码简化如下:
通过业务线程堆栈信息找到相关代码,并将代码简化如下:
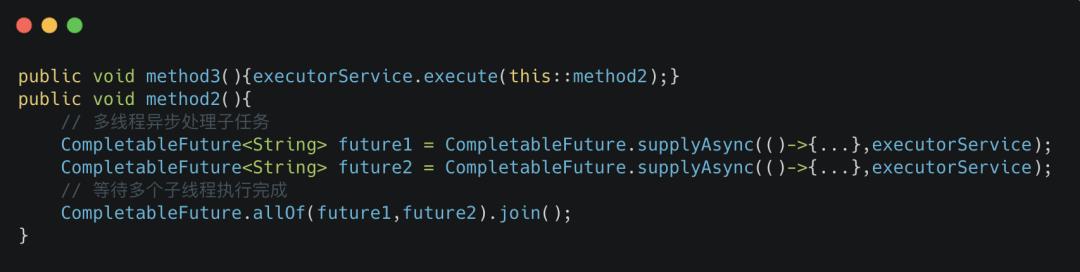
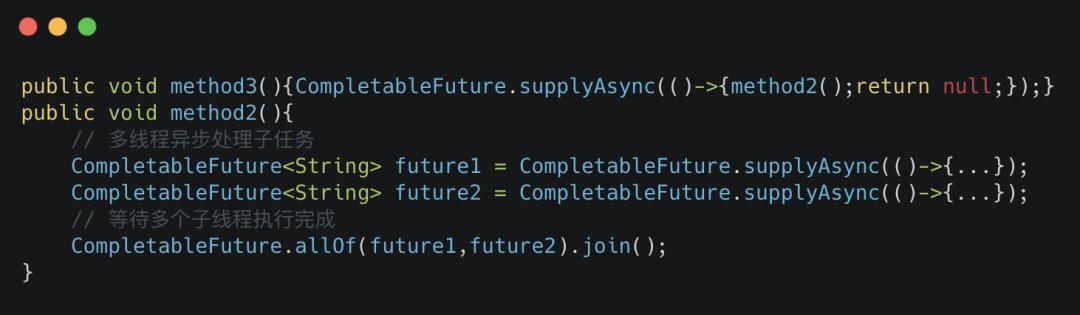
method3异步调用 method2,两个方法都用到了同一个业务线程池。
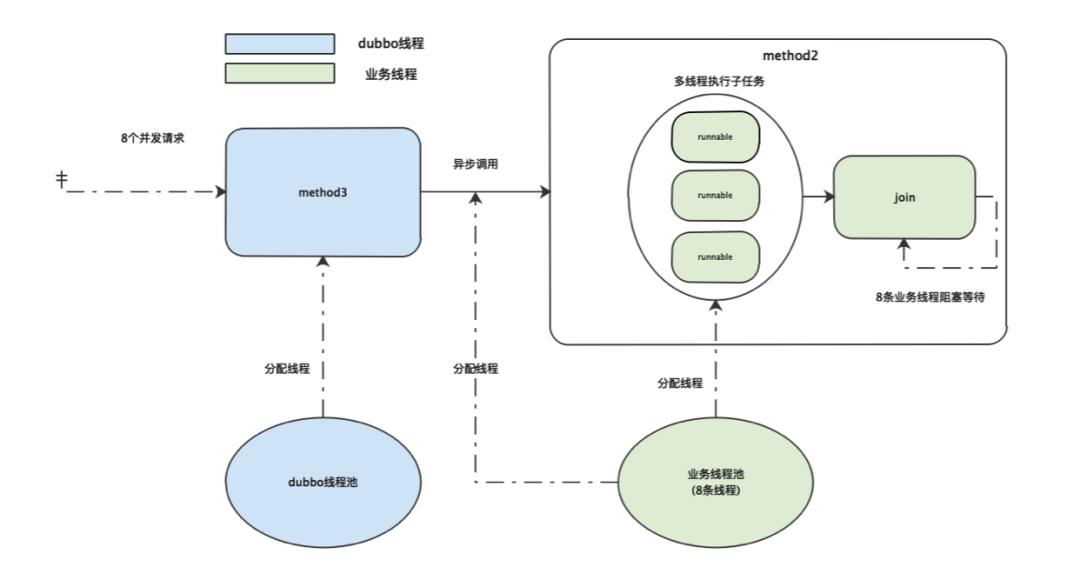
当 method3同时收到8个请求时,8条业务线程都被分配给 method3去异步调用 method2后,此时因为业务线程已经达到最大值, method2中的子任务会进入队列等待被业务线程拉取执行。而此时业务线程又都在 method2阻塞等待子任务执行完成,两边就陷入了相互等待的状态,因此业务线程陷入永久阻塞状态。
2.3 小结
结合以上分析,业务线程池的线程全部都被阻塞住,导致使用该业务线程池的Dubbo线程也全部阻塞。
三、问题解决
在真实的业务代码中其实远非简单的A调B,而是相对比较复杂的调用链:
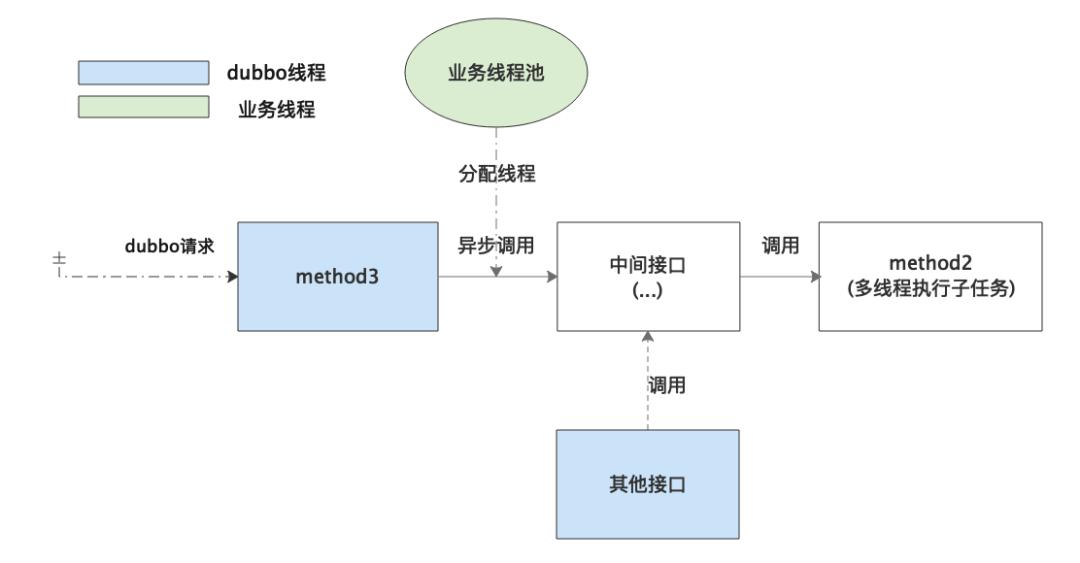
method3发起异步调用,经过多层中间接口调用到 method2。其他接口发起同步调用,同样经过多层中间接口调用到 method2。
因为经过多层中间接口,所以不能直接将 method2改成顺序执行多个子任务,会导致其他调用 method2的接口处理时间延长。抽出一个顺序执行子任务的方法也不太合适,因为涉及到改动多个中间接口,改动相对比较大。
解决方式是隔离线程池,将提交异步任务和多线程执行子任务拆分成两个线程池去处理。
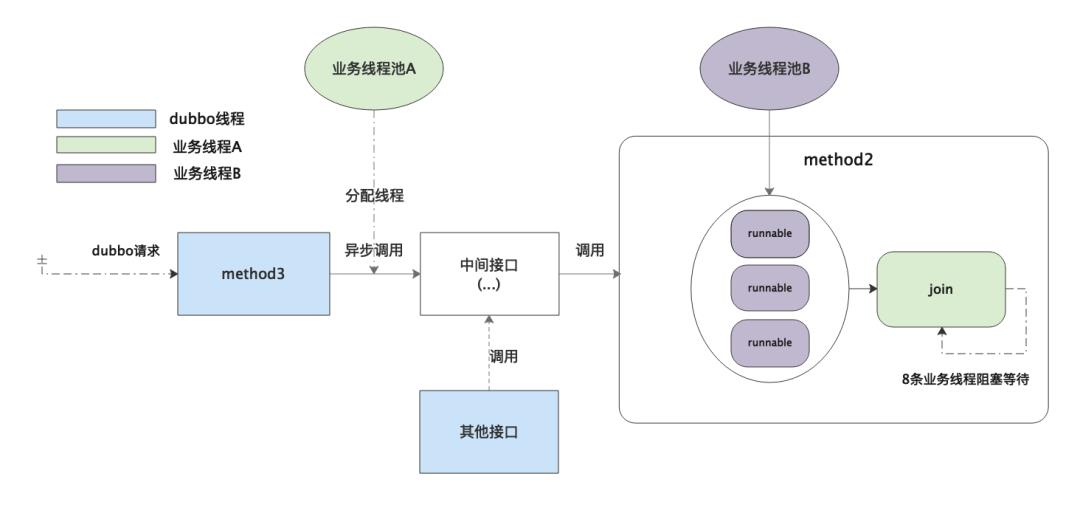 拆分成两个线程池之后,无论同时进来多少请求,在
拆分成两个线程池之后,无论同时进来多少请求,在 method2陷入阻塞的都是线程A,不会影响执行子任务的线程B。
将异步调用改成由一个新的线程池提交,这样影响范围就控制在 method3,改动也比较小,可以快速修复上线。
四、问题深究
查看代码提交记录,发现该业务是最近改成使用自定义线程池,之前是直接用 CompletableFuture的默认线程池,并且已经稳定运行了很长时间。
逻辑简化如下:
 那么问题来了,
那么问题来了, CompletableFuture的默认线程池也是共用的线程池,为什么可以正常执行?
4.1 使用默认线程池可以正常执行吗?
我们来验证一下,测试代码如下:
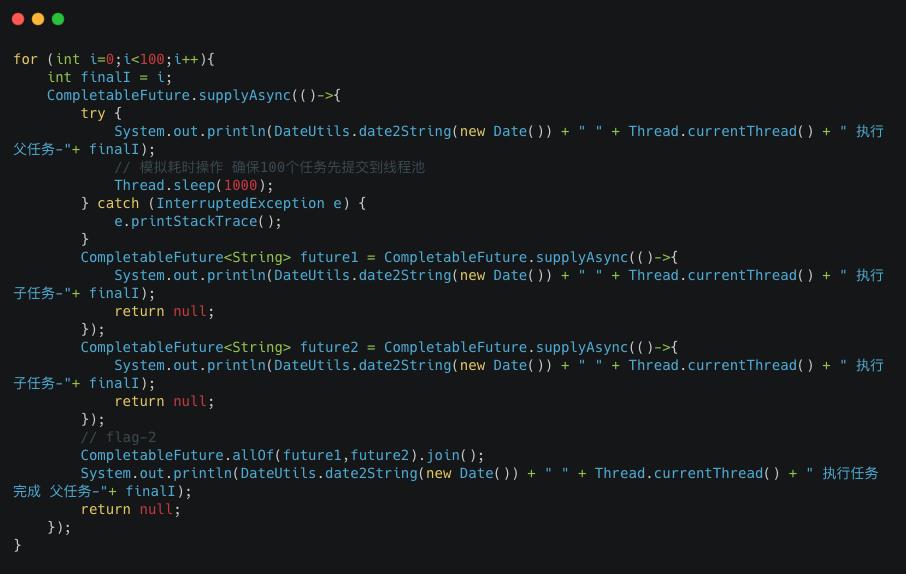 截取部分执行结果如下:
截取部分执行结果如下:
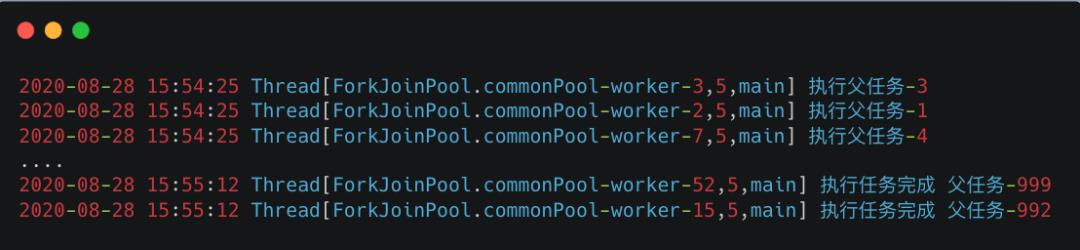
如输出结果所示,1000个任务都成功执行完成了,没有出现互相等待陷入阻塞的情况,说明可以正常执行完成。
4.2 为什么默认线程池可以正常执行完成?
CompletableFuture内部包含两种默认线程池,当 ForkJoinPool#getCommonPoolParallelism()大于1时使用 ForkJoinPool的 commonPool线程池,反之则使用内部类 ThreadPerTaskExecutor执行任务。
ThreadPerTaskExecutor每次执行都会创建线程,因此不会出现任务等待线程空闲的情况。commonPool是ForkJoinPool内部包含的默认线程池,一般情况下并行数为 cpu核心数-1。
ForkJoinPool#getCommonPoolParallelism()获取的就是 commonPool的并行数,我测试的机器获取到的 commonPool并行数为7,因此使用的是 ForkJoinPool线程池。
而 ForkJoinPool线程池之所以可以正常执行,关键在 CompletableFuture#join中的内部实现。截取 CompletableFuture#join解决此问题的关键时序图如下:
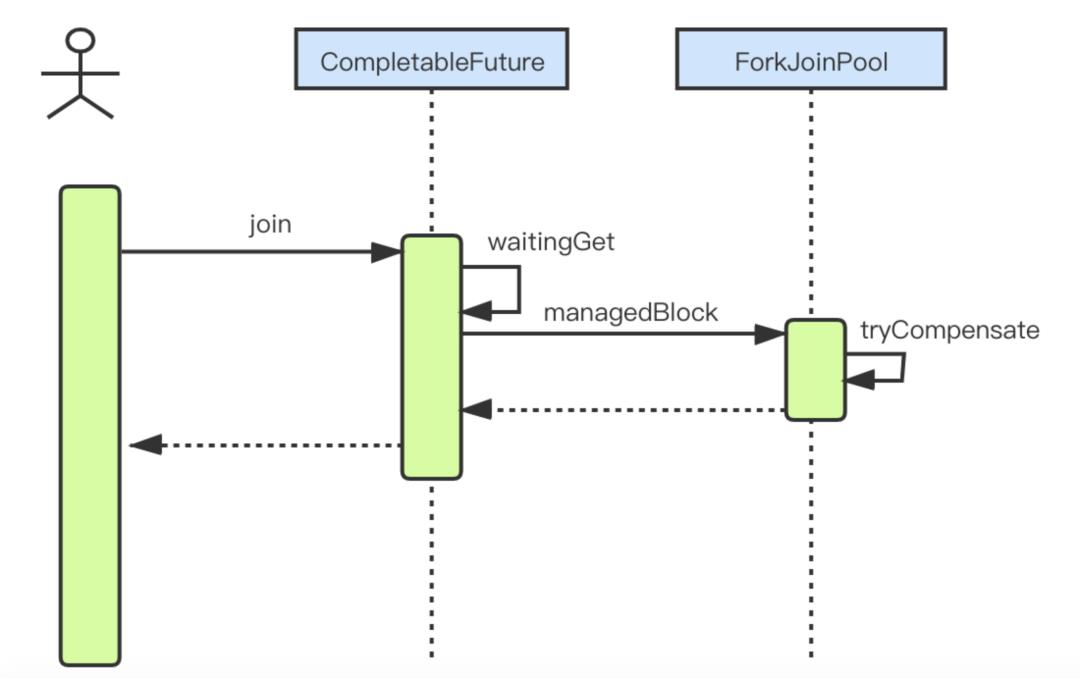 关键就在于
关键就在于 ForkJoinPool创建的线程为 ForkJoinWorkerThread类型,而 ForkJoinPool#managedBlock判断当前线程是 ForkJoinWorkerThread类型时会调用 tryCompensate方法,该方法在特定情况下会去补偿线程确保任务正常执行完成。
截取 tryCompensate源码如下:
根据 tryCompensate的源码可以得出:
tryCompensate在经过一系列校验,认为当前陷入阻塞会导致任务无法正常执行时,会尝试补偿创建一条新的线程,确保不出现上述的互等情况。普通
FokrJoinPool线程池最多会补偿到32767条线程。commonPool最多会补偿到并行数+256条工作线程,超过则会抛出异常。
因此 CompletableFuture线程池可以正常执行是因为使用 ThreadPerTaskExecutor时每次都会创建新的线程,而使用 commonPool时,在 CompletableFuture#join进入阻塞之前会去尝试补偿线程。但是也不是无限补偿,当补偿达到一定次数后就会抛出异常。
4.3 小结
使用 CompletableFuture的默认线程池之所以不会出现互等的情况,是因为提交任务时,如果内部使用的是 ThreadPerTaskExecutor是会不断创建新线程的,不会因为进入队列阻塞等待被执行而陷入等待。而如果内部使用的是 commonPool则 CompletableFuture#join方法在进入阻塞之前,判断当前线程是 ForkJoinWorkerThread线程则会在满足条件时先尝试补偿线程,确保有足够的线程去保证任务可以正常执行。
五、总结与思考
本次问题是父子任务都从同一个固定线程池中获取线程,并且父任务会等待子任务执行完成,在并发情况下触发了相互等待,最终导致线程池资源耗尽,从而影响到使用到该业务线程池的Dubbo请求正常执行。
因此项目中应该避免父子任务共用同一个线程池。通过线程池异步调用某个接口时,如果并不清楚接口的底层逻辑,要考虑底层有没有可能用到当前线程池,做好线程池隔离,避免触发此问题。
Vol.338
以上是关于线上es报错异常分析的主要内容,如果未能解决你的问题,请参考以下文章
rsyslog服务异常导致Python rpc服务启动异常的排查