MapReduce入门
Posted cangos
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MapReduce入门相关的知识,希望对你有一定的参考价值。
本文中的代码基于CDH的5.6版本编写
1、MrTest程序,模拟wordcount
输入文件:
hdfs文件路径:/tmp/test.txt 文件内容: hello world hello test test hadoop hadoop hdfs hive sql sqoop
代码:
package testhadoop; import java.io.IOException; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapred.JobConf; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
//定义类 public class MRTest { public static void main(String[] args){ Path inFile = new Path(args[0]); Path outFile = new Path(args[1]); Job job; try { job = Job.getInstance(); job.setJarByClass(testhadoop.MRTest.class); //设置传入文件路径 FileInputFormat.addInputPath(job , inFile);
//设置输出文件路径 FileOutputFormat.setOutputPath(job, outFile); //设置Reducer使用的类 job.setReducerClass(testhadoop.MRreducer.class);
//设置Mapper使用的类 job.setMapperClass(testhadoop.MRmapper.class); //设置Mapper输出的key的class job.setMapOutputKeyClass(Text.class);
//设置Mapper输出的value的class job.setMapOutputValueClass(IntWritable.class);
//设置Reducer输出的key的class job.setOutputKeyClass(Text.class);
//设置Reducer输出的value的class job.setOutputValueClass(IntWritable.class); try { job.waitForCompletion(true); } catch (ClassNotFoundException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (InterruptedException e) { // TODO Auto-generated catch block e.printStackTrace(); } } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } } class MRmapper extends Mapper<LongWritable, Text, Text, IntWritable>{ @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { // TODO Auto-generated method stub
//将value转化成string类的数组 String[] line = value.toString().split(" "); for(int i = 0 ; i< line.length-1 ;i++){ context.write(new Text(line[i]), new IntWritable(1)); } } } class MRreducer extends Reducer<Text, IntWritable, Text, IntWritable>{ @Override protected void reduce(Text arg0, Iterable<IntWritable> arg1, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { // TODO Auto-generated method stub int sum = 0; for(IntWritable i : arg1){ sum += i.get(); } context.write(arg0, new IntWritable(sum)); } }
导出成MRTest.jar并上传至服务器的/opt目录 执行: hadoop jar MRTest.jar "MRTest" "/tmp/test.txt" "/tmp/test/out" 再执行: hadoop fs -ls /tmp/test/out/* 查看输出的文件:
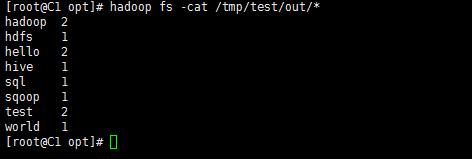
2、求最低温度
hdfs文件路径:/tmp/temp.txt 查看文件内容: 0067011990999991950051512004888888889999999N9+00221+9999999999999999999999 0067011990999991950051507004888888889999999N9+00001+9999999999999999999999 0067011990999991950051512004888888889999999N9+00221+9999999999999999999999 0067011990999991950051518004888888889999999N9-00111+9999999999999999999999 0067011990999991949032412004888888889999999N9+01111+9999999999999999999999 0067011990999991950032418004888888880500001N9+00001+9999999999999999999999 0067011990999991950051507004888888880500001N9+00781+9999999999999999999999
代码:
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Mapper.Context;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class TempTest {
public static void main(String[] args) {
// TODO Auto-generated method stub
Path fromPath = new Path(args[0]);
Path toPath = new Path(args[1]);
try {
Configuration conf = new Configuration();
Job job = Job.getInstance();
job.setJarByClass(TempTest.class);
FileInputFormat.setInputPaths(job, fromPath);
FileOutputFormat.setOutputPath(job, toPath);
job.setMapperClass(TempMapper.class);
job.setReducerClass(TempReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
try {
job.waitForCompletion(true);
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
class TempMapper extends Mapper<LongWritable,Text,Text,IntWritable>{
public static final int MISSING = 9999;
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
String line = value.toString();
String year = line.substring(15, 19);
String flag = line.substring(45,46);
int temp ;
if("+".equals(flag)){
temp = Integer.parseInt(line.substring(46,50));
}else{
temp = Integer.parseInt(line.substring(45,50));
}
String qua = line.substring(50,51);
if(temp != MISSING && qua.matches("[01459]")){
context.write(new Text(year), new IntWritable(temp));
}
}
}
class TempReducer extends Reducer<Text ,IntWritable ,Text,IntWritable>{
public static final Long MIN = Long.MIN_VALUE;
@Override
protected void reduce(Text arg0, Iterable<IntWritable> temp,
Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
// TODO Auto-generated method stub
int minValue = Integer.MAX_VALUE;
for(IntWritable t : temp){
minValue = Math.min(minValue, t.get());
}
context.write(arg0, new IntWritable(minValue));
}
}
导出成temp.jar并上传至服务器的/opt目录 执行: hadoop jar temp.jar "TempTest" "/tmp/temp.txt" "/tmp/temp/out" 再执行: hadoop fs -ls /tmp/temp/out/* 查看输出的文件:

以上是关于MapReduce入门的主要内容,如果未能解决你的问题,请参考以下文章