Oracle批量导出存储过程(保持每个存储过程独立)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Oracle批量导出存储过程(保持每个存储过程独立)相关的知识,希望对你有一定的参考价值。
如有A,B,C三个存储过程希望被导出,导出时还是保持A.sql,B.sql,C.sql而不是全部导到一个text.sql当中。存储过程或者shell方式都可以
略微复杂,需要存储过程实现。
1、创建输出路径,比如你要在d盘test目录下输出,你就先在d盘根目录下建立一个test的目录。
2、sqlplus下以sysdba登录,执行以下语句
create or replace directory TMP as \'d:\\test\';grant read,write on directory TMP to scott; --比如我用的scott用户
alter system set utl_file_dir=\'d:\\test\' scope=spfile;
3、以上步骤执行完,需要重启数据库。
4、创建一个存储过程,代码如下(基本是不用改动,原封复制即可):
CREATE OR REPLACE PROCEDURE SP_OUTPUT_PROCEDURE isfile_handle utl_file.file_type;
Write_content VARCHAR2(1024);
Write_file_name VARCHAR2(50);
v_name varchar2(50);
v_text varchar2(2000);
cursor cur_procedure_name is
select distinct name from user_source where type = \'PROCEDURE\';
cursor cur_sp_out is
select t.text
from (select 0 line, \'CREATE OR REPLACE \' text
from dual
union
select line, text
from user_source
where type = \'PROCEDURE\'
and name = v_name) t
order by line;
begin
open cur_procedure_name;
loop
fetch cur_procedure_name
into v_name;
exit when cur_procedure_name%notfound;
write_file_name := v_name || \'.txt\';
open cur_sp_out;
loop
fetch cur_sp_out
into v_text;
exit when cur_sp_out%notfound;
file_handle := utl_file.fopen(\'TMP\', write_file_name, \'a\');
write_content := v_text;
--write file
IF utl_file.is_open(file_handle) THEN
utl_file.put_line(file_handle, write_content);
END IF;
--close file
utl_file.fclose(file_handle);
end loop;
close cur_sp_out;
end loop;
close cur_procedure_name;
end;
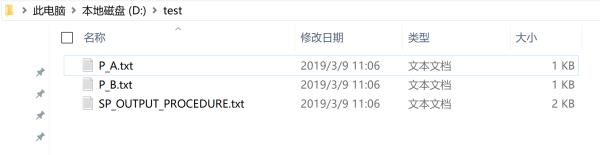
5、创建完毕执行存储过程,这个就不赘述了,执行完毕后,你会发现d盘test目录下的文件名就是以存储过程名命名的txt文件,如图:
6、里边内容(就是存储过程创建时的代码,可能排版看着难看点,但是不影响使用):

请问第31行里的a代表什么?
参考技术A 用plsql到出,十分方便mysql存储过程怎样批量插入数据
一下代码运行通过:
delimiter $$;create procedure lucia_proc16(count int)
begin
DECLARE name_proc VARCHAR(20) CHARACTER SET utf8;
DECLARE sex_proc VARCHAR(4) CHARACTER SET utf8;
DECLARE age_proc INT(10);
DECLARE class_proc VARCHAR(20) CHARACTER SET utf8;
DECLARE Addr_proc VARCHAR(50) CHARACTER SET utf8;
DECLARE i INT;
set i = 1;
set sex_proc = '女';
set age_proc = 20;
set class_proc = '山治班';
set Addr_proc = '北京市朝阳区';
while i<count do
set name_proc = CONCAT('露西亚',i);
insert into students(Name,Sex,age,class,Addr)values(name_proc,sex_proc,age_proc,class_proc,Addr_proc);
set i = i+1;
end while;
end
$$;
delimiter;
代码功能:
传入一个行数,控制插入多少条数据
运行效果:

用mysql储存过程批量插入数据
#数据表的结构为stu_id(学号) ,stu_name(姓名),stu_sex(性别),cla_id(班级编号),stu_phone(手机号)drop procedure if exists insertt;#如果存在储存过程则删除
delimiter $$ #创建一个储存过程
create procedure insertt()
begin
set @a=2000000001; #学号
set @d=20000001; #班级编号
set @e=18200000000; #手机号
while @a<2000010001 do #如果@a<2000010001则返回true,继续执行
set @b=rand_string(5); #姓名,随即赋值,值为5位a-zA-Z的任意组合
set @c=rand_sex(1); #性别,随即赋值,值为1位,0或者1
insert into students values(@a,@b,@c,@d,@e);
set @a=@a+1;
set @e=@e+1;
if @a%100=0
then
set @d=@d+1 ;
end if;
end while;
end$$
delimiter ;
#执行存储过程插入数据
call insertt();
#创建一个随机产生字符串的函数
set global log_bin_trust_function_creators = 1;
DROP FUNCTION IF EXISTS rand_string;
DELIMITER //
CREATE FUNCTION rand_string(n INT)
RETURNS VARCHAR(255)
BEGIN
DECLARE chars_str varchar(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ';
DECLARE return_str varchar(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
WHILE i < n DO
SET return_str = concat(return_str,substring(chars_str , FLOOR(1 + RAND()*52 ),1));#52代表在52个字母中随即找出一个
SET i = i +1;
END WHILE;
RETURN return_str;
END //
delimiter ;
#创建一个随机产生字符串的函数,0和1随机出现
set global log_bin_trust_function_creators = 1;
DROP FUNCTION IF EXISTS rand_sex;
DELIMITER //
CREATE FUNCTION rand_sex(n INT)
RETURNS VARCHAR(255)
BEGIN
DECLARE chars_str varchar(100) DEFAULT '01';
DECLARE return_str varchar(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
WHILE i < n DO
SET return_str = concat(return_str,substring(chars_str , FLOOR(1 + RAND()*2 ),1));
SET i = i +1;
END WHILE;
RETURN return_str;
END //
delimiter ;
以上是关于Oracle批量导出存储过程(保持每个存储过程独立)的主要内容,如果未能解决你的问题,请参考以下文章