SQL查询满足两个条件的重复记录只显示2条记录的方法
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL查询满足两个条件的重复记录只显示2条记录的方法相关的知识,希望对你有一定的参考价值。
图1
图2
SQL查询满足两个条件的重复记录只显示2条记录的方法,如图1,条件1:QB列前8位数一样,条件2:name内容一样,只显示符合条件的两条.要达到的目的如图2
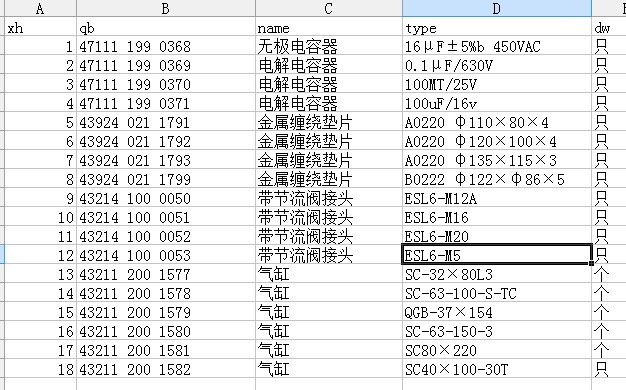
其次,需要合并重复的资料,即group by a ;
最后,只显示2条记录,即top 2;
整条sql就是:
select top 2 * from table where a=b and c=d group by a;
上面是a字段有重复的情况,若多个字段有重复,则:
select top 2 * from table where a=b and c=d group by a,b,c; 参考技术A
sqlserver写法
select t.xh,t.qb,t.name,t.type,t.dwfrom
(select 表名.*,row_number() over (partition by substring(qb,1,8),name order by xh desc) rn from 表名) t
where rn<=2
oracle的话substring(qb,1,8)改成substr(qb,1,8),其他数据库另说
本回答被提问者采纳 参考技术B 只以用游标来做,单纯的SQL语句无法实现。sql查询两个字段相同的记录
比如字段是id uid time这么一张表
id uid time
1 1 1
2 2 1
3 1 1
4 1 2
5 1 3
我想查询的是uid重复并且time也是重复的记录,比如上面的查出来的是 id = 1 3 的两条记录。
两种方法,一种是查询重复的数据,只查询重复记录,不管其余信息,如ID什么的:
select uid, time from ztest GROUP BY uid, time having count(*)>1;查出结果是
uid time
1 1
还有一种是查询你指定信息,可以查询出ID信息:
查询结果是:
id uid time
1 1 1
3 1 1
1select uid, time from ztest GROUP BY uid, time having count(*)>1;
查出结果是
uid time
1 1
2、SQL语言,是结构化查询语言(Structured Query Language)的简称。SQL语言是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统;同时也是数据库脚本文件的扩展名。
3、SQL语言是高级的非过程化编程语言,允许用户在高层数据结构上工作。它不要求用户指定对数据的存放方法,也不需要用户了解具体的数据存放方式,所以具有完全不同底层结构的不同数据库系统可以使用相同的结构化查询语言作为数据输入与管理的接口。SQL语言语句可以嵌套,这使他具有极大的灵活性和强大的功能。 参考技术B 1。先通过mssqlserver来学习,因为mssql有事件探查器,所有访问数据库的语句都会显示出来,mysql也有,但是比mssql麻烦,所以学习嘛,选mssql;
2。找一个商用的进销存软件,或者erp软件或者财务软件,只要是连mssql都都行。
3。打开事件探查器,监听。
4。做录入,更新,删除等操作,对比自己已学习的内容,提升经验。
5。尽量多做数据模拟,最好软件当中每个模块都有数据,这样你在查询软件某个功能是时候,就能通过事件探查器获取到查询语句。
6。把查询语句放在查询分析中,分析写法,不明白的地方查百度,研究明白了以后尝试自己模拟这种写法查询其他数据库表。
7。及时做好笔记。
这样一套下来应该就差触发器和存储过程了。
触发器和存储过程我个人觉得是需要先学写法的,cdsn上很多,会了简单写法以后,最好是在开发过程中,实践着写触发器和存储过程。
1. 库操作(创建,使用,删除,改名等)
2. 表/视图操作(创建,删除,复制,清空,查看)
3. 字段操作(主键操作,字段类型,添加字段,删除字段,修改字段,查看字段,约束操作和字段默认值)
4. INSERT(增加),SELECT(查询),UPDATE(修改),DELETE(删除)
其中 SELECT 查询还要重点掌握如下知识点:
a. 基础字段查询及CASE-WHEN/IF等条件查询
b. DISTINCT去重查询(理解它与GROUP BY的区别)
c. WHERE条件中的 AND,OR,NOT,LIKE,BETWEEN,IS NULL/IS NOT NULL,REGEXP等
d. ORDER BY排序
e. 使用MAX,MIN,SUM,AVG,COUNT聚合函数,及配合GROUP BY实现分组查询(WITH ROLLUP也可顺便学习下,配合GROUP BY效果更佳)
f. 掌握分组后的条件过滤HAVING的用法
g. 连接查询(SQL92和SQL99内连接,左右外连接,全外连接,自连接,4交叉连接)
h. 子查询(SELECT中的子查询,WHERE中的子查询,FROM中的子查询,嵌套递归子查询)
i. LIMIT(常用于分页查询或查询指定条数)
j. UNION/UNION ALL(联合查询)
h. 各种函数(日期时间,字符串截取,类型转换,四舍五入等)
开发必备:
1. 事务(隔离级别)和锁处理机制
2. 事件和触发器的使用(非必须,有余力可学习)
3. 自定义函数和存储过程的使用(非必须,有余力可学习)
性能优化必备:
1. 索引的各种用法
2. EXPLAIN执行计划分析
3. 二进制及慢查询日志分析
运维/DBA必备:
1. 安装数据库服务端
2. 权限分配与收回
3. 各种日志分析
4. 参数调优
5. 备份/恢复/查找数据
6. 锁表/解锁表
7. 配合开发实现分库分表,读写分离等 参考技术C EXCEL中用VBA连接ACCESS数据库
有如下一张表,要分别查找出所有同名的人、所有同名并且学号也一样的人以及所有同名但不同学号的人。
查询所有同名人员
select * from [18年考试成绩] where [姓名] in (SELECT [姓名] FROM [18年考试成绩] group by [姓名] having count(姓名)>1)
查询结果:
查找所有姓名和学号两个字段都重复的人
select * from [18年考试成绩] where [姓名] in (SELECT [姓名] FROM [18年考试成绩] group by [姓名] having count(姓名)>1) and [学号] in (SELECT [学号] FROM [18年考试成绩] group by [学号] having count(学号)>1)
查询结果:
查找所有姓名重复但学号不重复的人
select * from [18年考试成绩] where [姓名] in (SELECT [姓名] FROM [18年考试成绩] group by [姓名] having count(姓名)>1) and [学号] not in (SELECT [学号] FROM [18年考试成绩] group by [学号] having count(学号)>1)
注意:要把SELECT查询子句配合in或not in 操作符使用,SELECT查询子句只能有一列内容。
查询结果:
其中子句 “SELECT [姓名] FROM [18年考试成绩] group by [姓名] having count(姓名)>1”是显示所有重复的姓名,如果如下:
如果要知道重复出现次数,则可以这样写:
SELECT [姓名],count(姓名) as 出现次数 FROM [18年考试成绩] group by [姓名] having count(姓名)>1
结果如下:
查找唯一记录
group by [姓名],意思是按姓名分组,having count(姓名)>1 是分组条件,意思是姓名次数出现2次以上的重复内容以姓名进行分组,前面的count(姓名)是对分组以后的姓名统计出现次数。在后面要使用函数条件时应该使用having,而不是使用where
查找唯一值,比如本例的班级中,只有一个“四班”,要把这个四班的所有字段显示出来可以这样:
select * from [18年考试成绩] where 班级 not in (SELECT 班级 FROM [18年考试成绩] group by 班级 having count(班级)>1)
结果:
如果使用“SELECT DISTINCT 班级 FROM [18年考试成绩]”语句查询唯一值,结果将会如下:
DISTINCT 会显示不重复的值,如果有重复的,只显示第一个,所以如果需要显示仅出现一次的值并不适合使用SELECT DISTINCT语句
分组查询语句:
比如要班级为单位,查询每个班的总人数,科目总分,科目平均分等
SELECT [班级],count(姓名) as 班级人数,sum(语文) as 语文总成绩,sum(数学) as 数学总成绩,ROUND(avg(语文),1) as 语文平均分,ROUND(avg(数学),1) as 数学平均分 FROM [18年考试成绩] group by [班级]
查询结果如下:
注意:如果使用函数的字段,不使用AS指定别名,将会自动生成一个字段名,第一列名字Expr1000,第二列名为Expr1001,第三列名为Expr1002,以此类推
如:
SELECT [班级],count(姓名),sum(语文),sum(数学),ROUND(avg(语文),1) ,ROUND(avg(数学),1) FROM [18年考试成绩] group by [班级]
查询结果如下:
如果不指定别名,你将无法清楚在查询结果中知道每一列是干什么的。
如果需要再细分,查询每个班女生总人数和科目平均分,只需要再加一个where条件就可以了
SELECT [班级],count(姓名) as 班级女性人数,ROUND(avg(语文),1) as 语文平均分,ROUND(avg(数学),1) as 数学平均分 FROM [18年考试成绩] where 性别='女' group by [班级] 参考技术D sql查询两个字段相同的记录?1、查询重复的数据,只查询重复记录,不管其余信息,如ID什么的:
1select uid, time from ztest GROUP BY uid, time having count(*)>1;
查出结果是
uid time
1 1
2、SQL语言,是结构化查询语言(Structured Query Language)的简称。SQL语言是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统;同时也是数据库脚本文件的扩展名。
3、SQL语言是高级的非过程化编程语言,允许用户在高层数据结构上工作。它不要求用户指定对数据的存放方法,也不需要用户了解具体的数据存放方式,所以具有完全不同底层结构的不同数据库系统可以使用相同的结构化查询语言作为数据输入与管理的接口。SQL语言语句可以嵌套,这使他具有极大的灵活性和强大的功能。
以上是关于SQL查询满足两个条件的重复记录只显示2条记录的方法的主要内容,如果未能解决你的问题,请参考以下文章