CTR预估--正则,交叉验证特征提取变量分类
Posted 罐装可乐
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CTR预估--正则,交叉验证特征提取变量分类相关的知识,希望对你有一定的参考价值。
1、主要内容
2、梯度下降
(1)、批量梯度下降

2、随机梯度下降

区别:就是更新变量时使用全部的数据还是一个样本进行更新
当都是凸函数的两者鲜果相同,当使用神经网络时使用SGD可以跳出局部最优解,批量梯度下降则不行;
3、mini-batch 梯度下降

噪声随着样本数量的增加而减少;
3、正则
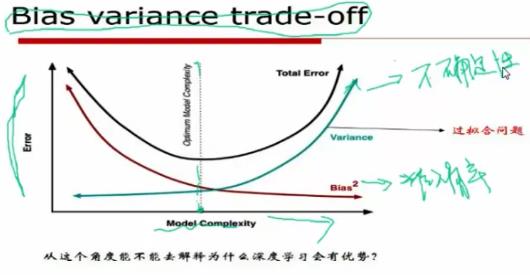
bias就表示模型在训练时与训练数据的切合程度也就是训练模型对训练数据的准确性,bias越小契合程度就越高,当bias为0时表示所有的训练数据都可以被模型表示,但是这样也表示了一旦将模型应用新的数据集上可能产生的error就很大,表明了模型的不确定定性;
对于过拟合问题:

正则化的重要作用:

加入正则项对bias的影响:

加入正则后,模型的参数选择变小,因此其bias的值会变大,然后减少了过拟合的产生。
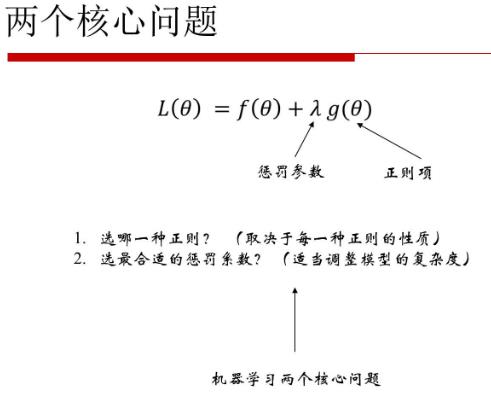
1、如何选择正则?

两个同等问题可以使用拉格朗日乘子法进行转化。
L1和L2的区别:主要区别就是限制条件的不同,L2采用平方,L1使用绝对值;

在进行参数选择时,w不断的去逼近这个限制条件,那么优化目标与限制条件必然会相交,对于L2来说最后交点在圆上的某一点,而L1正则交点在某条直线上因此才会有稀疏性;


4、交叉验证
引入正则后,正则方式已经确定,但是惩罚系数怎么去选,这就是引入交叉验证来选取最好的惩罚系数:
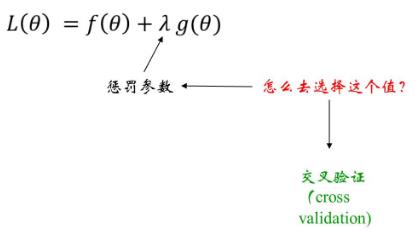
交叉验证的流程:


得出准确率之后如何选择lamdba:


5、特征选择


其中最常用的是关联分析:


枚举特征组合,这个只有在特征很少时才能使用,当有d个特征时,其组合数为2d-1,因此当d很大时,枚举特征就无法使用;
贪心法进行特征选择:

循环的条件condition怎么设置:
特征数量的限制:
1、当特征数量为d,就是特征集的长度时循环停止;
2、模型的准确率不再提高时也可以停止;
6、变量种类


以上是关于CTR预估--正则,交叉验证特征提取变量分类的主要内容,如果未能解决你的问题,请参考以下文章