flink - sink - hive
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了flink - sink - hive相关的知识,希望对你有一定的参考价值。
参考技术A 以下依赖均可以放到flink lib中,然后在pom中声明为providedflink对hive的核心依赖
没有hadoop环境时可以用此依赖代替
hive的依赖,此依赖应该放在flink-shaded-hadoop后面,让工程优先访问flink-shaded-hadoop的依赖
dataStream转为flink table,再通过hive catalog写入到hive表中
23.Flink-高级特性-新特性-Streaming Flie Sink介绍代码演示Flink-高级特性-新特性-FlinkSQL整合Hive添加依赖和jar包和配置
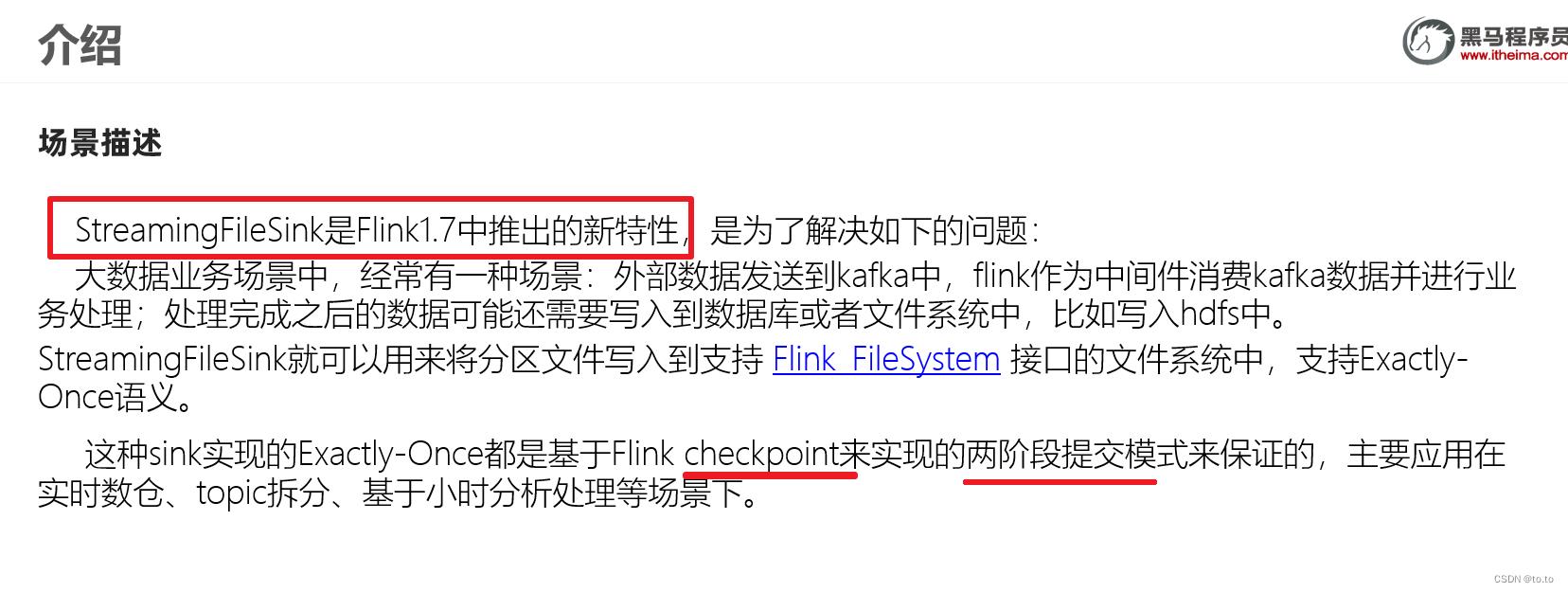
23.Flink-高级特性-新特性-Streaming Flie Sink
23.1.介绍
23.2.代码演示
24.Flink-高级特性-新特性-FlinkSQL整合Hive
24.1.介绍
24.2.版本
24.3.添加依赖和jar包和配置
24.4.FlinkSQL整合Hive-CLI命令行整合
24.5.FlinkSQL整合Hive-代码整合
23.Flink-高级特性-新特性-Streaming Flie Sink
23.1.介绍
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/connectors/streamfile_sink.html
https://blog.csdn.net/u013220482/article/details/100901471
23.2.代码演示
import org.apache.commons.lang3.SystemUtils;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.core.fs.Path;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.OutputFileConfig;
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink;
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy;
import org.apache.flink.util.Collector;
import java.util.concurrent.TimeUnit;
/**
* 演示Flink StreamingFileSink将流式数据写入到HDFS 数据一致性由Checkpoint + 两阶段提交保证
*
* @author tuzuoquan
* @date 2022/6/21 20:05
*/
public class StreamingFileSinkDemo
public static void main(String[] args) throws Exception
//TODO 0.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//开启Checkpoint
//===========类型1:必须参数=============
//设置Checkpoint的时间间隔为1000ms做一次Checkpoint/其实就是每隔1000ms发一次Barrier!
env.enableCheckpointing(1000);
if (SystemUtils.IS_OS_WINDOWS)
env.setStateBackend(new FsStateBackend("file:///D:/ckp"));
else
env.setStateBackend(new FsStateBackend("hdfs://node1:8020/flink-checkpoint/checkpoint"));
//===========类型2:建议参数===========
//设置两个Checkpoint 之间最少等待时间,如设置Checkpoint之间最少是要等 500ms(为了避免每隔1000ms做一次Checkpoint的时候,前一次太慢和后一次重叠到一起去了)
//如:高速公路上,每隔1s关口放行一辆车,但是规定了两车之前的最小车距为500m
//默认是0
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
//设置如果在做Checkpoint过程中出现错误,是否让整体任务失败:true是 false不是
//env.getCheckpointConfig().setFailOnCheckpointingErrors(false);//默认是true
//默认值为0,表示不容忍任何检查点失败
env.getCheckpointConfig().setTolerableCheckpointFailureNumber(10);
//设置是否清理检查点,表示 Cancel 时是否需要保留当前的 Checkpoint,默认 Checkpoint会在作业被Cancel时被删除
//ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION:true,当作业被取消时,删除外部的checkpoint(默认值)
//ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION:false,当作业被取消时,保留外部的checkpoint
env.getCheckpointConfig().enableExternalizedCheckpoints(
CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//===================类型3:直接使用默认即可===============================
//设置checkpoint的执行模式为EXACTLY_ONCE(默认)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//设置checkpoint的超时时间,如果 Checkpoint在 60s内尚未完成说明该次Checkpoint失败,则丢弃。
//默认10分钟
env.getCheckpointConfig().setCheckpointTimeout(60000);
//设置同一时间有多少个checkpoint可以同时执行
//默认为1
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
//TODO 1.source
DataStream<String> lines = env.socketTextStream("node1", 9999);
//TODO 2.transformation
//注意:下面的操作将上面的2步合成了1步,直接切割单词并记为1返回
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = lines.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>()
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception
String[] arr = value.split(" ");
for (String word : arr)
out.collect(Tuple2.of(word, 1));
);
SingleOutputStreamOperator<String> result = wordAndOne.keyBy(t -> t.f0).sum(1)
.map(new MapFunction<Tuple2<String, Integer>, String>()
@Override
public String map(Tuple2<String, Integer> value) throws Exception
return value.f0 + ":" + value.f1;
);
//TODO 3.sink
result.print();
//使用StreamingFileSink将数据sink到HDFS
OutputFileConfig config = OutputFileConfig
.builder()
//设置文件前缀
.withPartPrefix("prefix")
//设置文件后缀
.withPartSuffix(".txt")
.build();
StreamingFileSink<String> streamingFileSink = StreamingFileSink.
forRowFormat(new Path("hdfs://node1:8020/FlinkStreamFileSink/parquet"), new SimpleStringEncoder<String>("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
//每隔15分钟生成一个新文件
.withRolloverInterval(TimeUnit.MINUTES.toMillis(15))
//每隔5分钟没有新数据到来,也把之前的生成一个新文件
.withInactivityInterval(TimeUnit.MINUTES.toMillis(5))
.withMaxPartSize(1024 * 1024 * 1024)
.build())
.withOutputFileConfig(config)
.build();
result.addSink(streamingFileSink);
//TODO 4.execute
env.execute();
24.Flink-高级特性-新特性-FlinkSQL整合Hive
24.1.介绍

24.2.版本
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/connectors/hive/

24.3.添加依赖和jar包和配置
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hive_2.12</artifactId>
<version>$flink.version</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-metastore</artifactId>
<version>2.1.0</version>
<exclusions>
<exclusion>
<artifactId>hadoop-hdfs</artifactId>
<groupId>org.apache.hadoop</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>2.1.0</version>
</dependency>
上传资料hive中的jar包到flink/lib中

24.4.FlinkSQL整合Hive-CLI命令行整合
1.修改hive-site.xml
<property>
<name>hive.metastore.uris</name>
<value>thrift://node3:9083</value>
</property>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node3:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>node3</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://node3:9083</value>
</property>
</configuration>
2.启动元数据服务
nohup /export/server/hive/bin/hive --service metastore &
3.修改flink/conf/sql-client-defaults.yaml
catalogs:
- name: myhive
type: hive
hive-conf-dir: /export/server/hive/conf
default-database: default
4.分发
5.启动flink集群
/export/server/flink/bin/start-cluster.sh
6.启动flink-sql客户端-hive在哪就在哪启动
/export/server/flink/bin/sql-client.sh embedded
7.执行sql:
show catalogs;
use catalog myhive;
show tables;
select * from person;
24.5.FlinkSQL整合Hive-代码整合
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/connectors/hive/
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.api.TableResult;
import org.apache.flink.table.catalog.hive.HiveCatalog;
/**
* @author tuzuoquan
* @date 2022/6/21 23:15
*/
public class HiveDemo
public static void main(String[] args)
//TODO 0.env
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//TODO 指定hive的配置
String name = "myhive";
String defaultDatabase = "default";
String hiveConfDir = "./conf";
//TODO 根据配置创建hiveCatalog
HiveCatalog hive = new HiveCatalog(name, defaultDatabase, hiveConfDir);
//注册catalog
tableEnv.registerCatalog("myhive", hive);
//使用注册的catalog
tableEnv.useCatalog("myhive");
//向Hive表中写入数据
String insertSQL = "insert into person select * from person";
TableResult result = tableEnv.executeSql(insertSQL);
System.out.println(result.getJobClient().get().getJobStatus());
以上是关于flink - sink - hive的主要内容,如果未能解决你的问题,请参考以下文章