北航编译原理总结 C文法
Posted superxiaoying
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了北航编译原理总结 C文法相关的知识,希望对你有一定的参考价值。
定位:传说中北航计算机学院最头疼课程其实也没有辣么难,一点点的完成,并不会出现传说中的刷夜~
0.pascal-s和PL/0编译器源码有必要结合编译器基础知识认真读一下,当然不必细枝末节,重点是看一下人家的编译器中所谓的“词法分析”“语法分析”等阶段以及符号表的建立需要什么量,每个量分别代表什么,以及运行栈出现在什么时候,如何设计(可以和后期优化结合起来~)等。
1.我的文法为 扩充c0文法-高,具体文法如下:
<加法运算符> ::= +|-
<乘法运算符> ::= *|/
<关系运算符> ::= <|<=|>|>=|!=|==
<字母> ::= _|a|...|z|A|...|Z
<数字> ::= 0|<非零数字>
<非零数字> ::= 1|...|9
<字符> ::= \'<加法运算符>\'|\'<乘法运算符>\'|\'<字母>\'|\'<数字>\'
<字符串> ::= "{十进制编码为32,33,35-126的ASCII字符}"
<程序> ::= [<常量说明>][<变量说明>]{<有返回值函数定义>|<无返回值函数定义>}<主函数>
<常量说明> ::= const<常量定义>;{ const<常量定义>;}
<常量定义> ::= int<标识符>=<整数>{,<标识符>=<整数>}
| char<标识符>=<字符>{,<标识符>=<字符>}
<无符号整数> ::= <非零数字>{<数字>}
<整数> ::= [+|-]<无符号整数>|0
<标识符> ::= <字母>{<字母>|<数字>}
<声明头部> ::= int<标识符>|char<标识符>
<变量说明> ::= <变量定义>;{<变量定义>;}
<变量定义> ::= <类型标识符>(<标识符>|<标识符>‘[’<无符号整数>‘]’){,(<标识符>|<标识符>‘[’<无符号整数>‘]’) }
<类型标识符> ::= int
| char
<有返回值函数定义> ::= <声明头部>‘(’<参数>‘)’ ‘{’<复合语句>‘}’
<无返回值函数定义> ::= void<标识符>‘(’<参数>‘)’‘{’<复合语句>‘}’
<复合语句> ::= [<常量说明>][<变量说明>]<语句列>
<参数> ::= <参数表>
<参数表> ::= <类型标识符><标识符>{,<类型标识符><标识符>}| <空>
<主函数> ::= void main‘(’‘)’ ‘{’<复合语句>‘}’
<表达式> ::= [+|-]<项>{<加法运算符><项>}
<项> ::= <因子>{<乘法运算符><因子>}
<因子> ::= <标识符>|<标识符>‘[’<表达式>‘]’|<整数>|<字符>|<有返回值函数调用语句>|‘(’<表达式>‘)’
<语句> ::= <条件语句>|<循环语句>|‘{’<语句列>‘}’|<有返回值函数调用语句>; |<无返回值函数调用语句>;|<赋值语句>;|<读语句>;|<写语句>;|<空>;|<返回语句>;
<赋值语句> ::= <标识符>=<表达式>|<标识符>‘[’<表达式>‘]’=<表达式>
<条件语句> ::= if ‘(’<条件>‘)’<语句>[else<语句>]
<条件> ::= <表达式><关系运算符><表达式>|<表达式>
<循环语句> ::= do<语句>while ‘(’<条件>‘)’ |for‘(’<标识符>=<表达式>;<条件>;<标识符>=<标识符>(+|-)<步长>‘)’<语句>
<步长>::= <无符号整数>
<有返回值函数调用语句> ::= <标识符>‘(’<值参数表>‘)’
<无返回值函数调用语句> ::= <标识符>‘(’<值参数表>‘)’
<值参数表> ::= <表达式>{,<表达式>}|<空>
<语句列> ::={<语句>}
<读语句> ::= scanf ‘(’<标识符>{,<标识符>}‘)’
<写语句> ::= printf‘(’<字符串>,<表达式>‘)’|printf ‘(’<字符串>‘)’|printf ‘(’<表达式>‘)’
<返回语句> ::= return[‘(’<表达式>‘)’]
附加说明:
(1)char类型的表达式,用字符的ASCII码对应的整数参加运算,在写语句中输出字符
(2)标识符区分大小写字母
(3)写语句中的字符串原样输出
(4)数组的下标从0开始
首先,你需要看懂你的文法,它就是一套编译世界运行的规则,包括一些细节的问题如:在规定的文法中do while 循环最后可以没有分号,不同于C语言标准文法。当然加上;也是可以的,因为文法中有<语句>=<空>;这么一条。
2.词法分析-->语法分析-->语义分析和代码生成-->优化后的代码生成.明确各个阶段干了什么,想清楚如何设计四元式,如何设计运行栈,再动手码代码。
词法分析:平日里运行的代码,其实就是一个个的字符组成的字符串。而词法分析的作用就是将这么个大的字符串分隔和组合成有意义的单词,并做相应的记录。
a.可以将输入的源代码出现的单词分为:关键字(即保留字,如char,int,main等)、单分界符、预读分界符、整数、标识符等。如下图所示,在下图中表格的帮助下,我们在语法分析阶段每获取有个单词,就知道他是什么性质,从而分析接下来源程序可能要干什么。
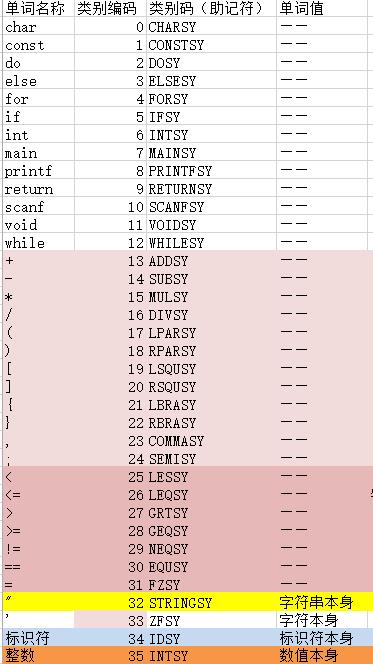
b.注意,有的时候需要预读字符才能知道 当前单词是什么性质的o~
如果下一个字符是回车,也要能够正确处理!
语法分析:结合文法规则和并调用词法分析程序,实现明确源代码语法成分分析。
如对于如下代码:const int a=0,b=2;
在读到第一逗号处,应当识别出是常量定义,在分号处应当识别出是又一个常量定义,并紧接着报告常量说明。我采用了如下的方式说明,比较清晰。
const CONSTSY
int INTSY
a DIENT
= EQUSY
0 INTSY
, --- 常量定义
b DIENT
= EQUSY
2 INTSY
; --- 常量定义
--- 常量说明
另外,这个阶段需要明确很多词的含义,并生成符号表,供之后使用。相信你已经看到书中对于Pascal-s编译器符号表的设计,其中对于符号表中的各个量的设计在不同的语言中不同,但是如果你能明白PASCAL-S符号表中各个量的含义,那对应你需要设计的应该没有问题,不懂的可以看书,书上有!细心看!
特别说明:符号表中addr 对于函数名代表其相应目标代码的入口地址,对于变量(数组同理,数组只不过是很多的变量)可以代表其在运行栈中的相对地址,对于常数,可以代表其实际对应的ASCII码值。
3.语义分析
这个最难想的一个阶段。符号表存储的信息和源代码生成四元式呢?
其实,语义分析和语法分析是紧密结合在一起的,“四元式在有当前期储备好的足够信息时,即可生成。”如下面比较复杂的转四元式的例子:
for(i=0①;②i<10③;④i=i+1⑤)
⑥
{
。。。
。。。
⑦
}
⑧
分别在for循环的7个地方需要生成相应的中间代码,其实生成中间代码的过程就是程序的执行流程。其中,标签的对应比较重要。
① :ASSIGN 0 i
① :SET label1
② :BGE i 10 label2 ;GOTO label3
③ :SET label4
④ :ADD i 1 $t1;ASSIGN $t1 i ;GOTO label1
⑤ :SET label3
⑥ :GOTO label4
⑧ :SET label2
可见,一个for循环框架在8处转化为若干条中间代码,即四元式。语义分析是在语义分析代码的基础上,各个细节处增加相应的代码即可。
四元式的设计可以参考如下:
四元式的数据结构如下:
struct {
char op[1000];
char op1[1000];
char op2[1000];
char res[1000];
}midCode[10000];
四元式的结构如下表所示:
|
分组 |
编号 |
四元式 |
说明 |
|
基本算术运算 |
1 |
ADD SRC1 SRC2 DST |
加:DST = SRC1 + SRC2 |
|
2 |
SUB SRC1 SRC2 DST |
减:DST = SRC1 - SRC2 |
|
|
3 |
MULT SRC1 SRC2 DST |
乘:DST = SRC1 * SRC2 |
|
|
4 |
DIV SRC1 SRC2 DST |
除:DST = SRC1 / SRC2 |
|
|
|
|
|
|
|
普通赋值 |
5 |
ASSIGN SRC1 DST ---- |
DST = SRC1 |
|
数组存取 |
6 |
STOA VALUE ARRAY OFF |
ARRAY[OFF] = VALUE |
|
7 |
GETA ARRAY OFF VALUE |
VALUE = ARRAY[OFF] |
|
|
函数调用 |
8 |
CALL SRC1 ---- ---- |
调用函数 |
|
逻辑判断跳转 |
9 |
BNE SRC1 SRC2 LABLE |
SRC1 != SRC2则跳转到LABEL |
|
10 |
BEQ SRC1 SRC2 LABLE |
SRC1 == SRC2则跳转到LABEL |
|
|
11 |
BLE SRC1 SRC2 LABLE |
SRC1 <= SRC2则跳转到LABEL |
|
|
12 |
BLT SRC1 SRC2 LABLE |
SRC1 < SRC2则跳转到LABEL |
|
|
13 |
BGE SRC1 SRC2 LABLE |
SRC1 >= SRC2则跳转到LABEL |
|
|
14 |
BGT SRC1 SRC2 LABLE |
SRC1 > SRC2则跳转到LABEL |
|
|
无条件跳转 |
15 |
GOTO LABLE ---- ---- |
跳转到LABEL |
|
传参数 |
16 |
PARA SRC DST ---- |
把SRC作为参数传给函数DST |
|
函数返回 |
17 |
RETURN DST ---- ---- |
DST作为返回值返回 |
|
18 |
RETURN ---- ---- ---- |
无返回值函数返回 |
|
|
函数结束 |
19 |
END ---- ---- ---- |
函数结束 |
|
读写指令 |
20 |
PRINTS DST ---- ---- |
写字符串 |
|
21 |
PRINTC DST ---- ---- |
写字符 |
|
|
22 |
PRINTF DST ---- ---- |
写整型 |
|
|
23 |
SCANC DST ---- ---- |
读字符 |
|
|
24 |
SCANF DST ---- ---- |
读整型 |
4.代码生成
目标代码生成是编译的最后阶段,将编译器此前生成的中间代码和符号表以及其他相关信息作为输入,输出与源程序语义等价的目标程序代码。
从四元式到目标代码的生成需要结合符号表,因为需要明确变量的作用域,检验是否满足语义规则等信息。对于跳转和返回,需要结合自己的运行栈设计结合以及符号表中存储的信息进行必要的运行栈加减操作。
具体实现举例:
ADD a b res
如果a,b,res都是局部变量,且保存在内存中那么汇编指令生成如下:
其中x表示在符号表中保存的a的相对偏移。y为b的相对偏移,z为res的相对偏移。
lw $s1,x($fp);
lw $s2,y($fp);
add $s1,$s2,$s3;
sw $s3,z($fp);
如果a,b,res分别分配了$s1,$s2,$s3寄存器,那么汇编指令如下:
add $s1,$s2,$s3;
如果a,b,res中有任何是全局变量,那么应当从相对于全局的位置中获取或保存。
我的运行栈设计如下:
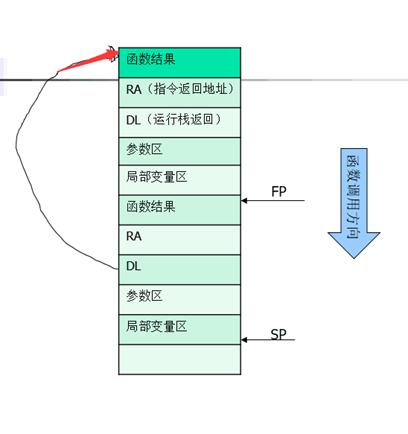
5.错误处理
由于错误处理要求,不遗漏错误且不能因为局部错误影响后续正确代码的判断。我处理的方式是,发生错误如遗漏分号,当做有分号已读取继续后面的分析。这样不会跳过太多的代码而导致漏诊。
6.我的编译器涉及到的MIPS指令
|
编号 |
指令 |
例子 |
例子说明 |
|
|
1 |
j |
j main |
跳转到main |
|
|
2 |
subi |
subi $sp, $sp, 4 |
$sp = $sp – 4 这个指令用于获取一段栈空间 |
|
|
3 |
sw |
sw $ra, 0($sp) |
把寄存器$ra中的值存到地址0($sp) |
|
|
4 |
bnez |
bnez $t1, label |
如果$t1 != 0, 则跳转到label |
|
|
5 |
beqz |
beqz $t1, label |
如果$t1 == 0, 则跳转到label |
|
|
6 |
bgez |
bgez $t1, label |
如果$t1 >= 0, 则跳转到label |
|
|
7 |
bgtz |
bgtz $t1, label |
如果$t1 > 0, 则跳转到label |
|
|
8 |
blez |
blez $t1, label |
如果$t1 <= 0, 则跳转到label |
|
|
9 |
bltz |
bltz $t1, label |
如果$t1 < 0, 则跳转到label |
|
|
10 |
li |
li $t0, 1 |
$t0 = 1 |
|
|
11 |
add |
add $t0, $t1, $t2 |
$t0 = $t1 + $t2 |
|
|
12 |
lw |
lw $t0, 0($sp) |
将地址0($sp)中的值加载到$t0 |
|
|
13 |
sub |
编译原理题目关于判断LL(1)文法的 | ||