NOSQL数据模型和CAP原理
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NOSQL数据模型和CAP原理相关的知识,希望对你有一定的参考价值。
我本来一直觉得NoSQL其实很容易理解的,我本身也已经对NoSQL有了非常深入的研究,但是在最近准备YunTable的Chart的时候,发现NoSQL不仅非常博大精深,而且我个人对NoSQL的理解也只是皮毛而已,但我还算是一个“知耻而后勇”的人,所以经过一段时间的学习之后,从本系列第六篇开始,就将和大家聊聊NoSQL,而本篇将主要给大家做一下NoSQL数据库的综述。
首先将和大家聊聊为什么NoSQL会在关系型数据库已经非常普及的情况下异军突起?
诞生的原因
随着互联网的不断发展,各种类型的应用层出不穷,所以导致在这个云计算的时代,对技术提出了更多的需求,主要体现在下面这四个方面:
1. 低延迟的读写速度:应用快速地反应能极大地提升用户的满意度;
2. 支撑海量的数据和流量:对于搜索这样大型应用而言,需要利用PB级别的数据和能应对百万级的流量;
3. 大规模集群的管理:系统管理员希望分布式应用能更简单的部署和管理;
4. 庞大运营成本的考量:IT经理们希望在硬件成本、软件成本和人力成本能够有大幅度地降低;
虽然关系型数据库已经在业界的数据存储方面占据不可动摇的地位,但是由于其天生的几个限制,使其很难满足上面这几个需求:
1. 扩展困难:由于存在类似Join这样多表查询机制,使得数据库在扩展方面很艰难;
2. 读写慢:这种情况主要发生在数据量达到一定规模时由于关系型数据库的系统逻辑非常复杂,使得其非常容易发生死锁等的并发问题,所以导致其读写速度下滑非常严重;
3. 成本高:企业级数据库的License价格很惊人,并且随着系统的规模,而不断上升;
4. 有限的支撑容量:现有关系型解决方案还无法支撑Google这样海量的数据存储;
业界为了解决上面提到的几个需求,推出了多款新类型的数据库,并且由于它们在设计上和传统的NoSQL数据库相比有很大的不同,所以被统称为 “NoSQL”系列数据库。总的来说,在设计上,它们非常关注对数据高并发地读写和对海量数据的存储等,与关系型数据库相比,它们在架构和数据模型方量面做了“减法”,而在扩展和并发等方面做了“加法”。现在主流的NoSQL数据库有BigTable、HBase、Cassandra、SimpleDB、 CouchDB、MongoDB和Redis等。接下来,将关注NoSQL数据库到底存在哪些优缺点。
优缺点
在优势方面,主要体现在下面这三点:
1. 简单的扩展:典型例子是Cassandra,由于其架构是类似于经典的P2P,所以能通过轻松地添加新的节点来扩展这个集群;
3. 低廉的成本:这是大多数分布式数据库共有的特点,因为主要都是开源软件,没有昂贵的License成本;
但瑕不掩瑜,NoSQL数据库还存在着很多的不足,常见主要有下面这几个:
1. 不提供对SQL的支持:如果不支持SQL这样的工业标准,将会对用户产生一定的学习和应用迁移成本;
2. 支持的特性不够丰富:现有产品所提供的功能都比较有限,大多数NoSQL数据库都不支持事务,也不像MS SQL Server和Oracle那样能提供各种附加功能,比如BI和报表等;
3. 现有产品的不够成熟:大多数产品都还处于初创期,和关系型数据库几十年的完善不可同日而语;
上面NoSQL产品的优缺点都是些比较共通的,在实际情况下,每个产品都会根据自己所遵从的数据模型和CAP理念而有所不同,接下来,将给大家介绍NoSQL两个最重要的概念:数据模型和CAP理念,并在本文最后,对主流的NoSQL数据库进行分类。
数据模型
传统的数据库在数据模型方面,主要是关系型,它的特色是对Join类操作和ACID事务的支持。在NoSQL领域,主要有三种主流的数据模型:
Column-oriented(列式)
列式也主要使用Table这样的模型,但是它并不支持类似Join这样多表的操作,它的主要特点是在存储数据时,主要围绕着“列(Column)”,而不是像传统的关系型数据库那样根据“行(Row)”进行存储,也就是说,属于同一列的数据会尽可能地存储在硬盘同一个页(Page)中,而不是将属于同一个行的数据存放在一起,这样做的好处是,对于很多类似数据仓库(Data Warehouse)的应用,虽然每次查询都会处理很多数据,但是每次所涉及的列并没有很多,这样如果使用列式数据库的话,将会节省大量I/O,并且大多数列式数据库都支持Column Family这个特性,通过这个特性能将多个Column并为一个小组,这样做好处是能将相似Column放在一起存储,这样能提高这些Column的存储和查询效率。总体而言,这种数据模型的优点是比较适合汇总(Aggregation)和数据仓库这类应用。.
Key-value
虽然Key-value这种模型和传统的关系型相比较简单,有点类似常见的HashTable,一个Key对应一个Value,但是其能提供非常快的查询速度、大的数据存放量和高并发操作,并非常适合通过主键对数据进行查询和修改等操作,虽然不支持复杂的操作,但是可以通过上层的开发来弥补这个缺陷。
Document(文档)
CAP理论
这个理论是由美国著名科学家,同时也是著名互联网企业Inktomi的创始人Eric Brewer在2000年PODC(Symposium on Principles of Distributed Computing)大会上提出的,后来Seth Gilbert 和 Nancy lynch两人也证明了CAP理论的正确性,虽然在后来近十年的时间很多人对CAP理论提出了很多异议,但是在NoSQL的世界中,它还是非常有参考价值的。它的意思是,一个分布式系统不能同时满足一致性,可用性和分区容错性这三个需求,最多只能同时满足两个。
1. 一致性(Consistency):任何一个读操作总是能读取到之前完成的写操作结果,也就是在分布式环境中,多点的数据是一致的;
2. 可用性(Availability):每一个操作总是能够在确定的时间内返回,也就是系统随时都是可用的。
3. 分区容忍性(Partition Tolerance): 在出现网络分区(比如断网)的情况下,分离的系统也能正常运行。
由于一致性、可用性和分区容忍性这三方面只能选择两个,所以大多数NoSQL系统都会根据自己的设计理念来进行相应的选择,但由于许多NoSQL数据库都以水平扩展著称,所以在CAP的选择上面,都倾向于坚持分区容忍性,而放弃一致性或者可用性,它们的做法主要是通过消减关系型和事务相关的功能。
具体分类
下面的具体分类是来自于Visual Guide to NoSQL Systems一文,虽然对于这块分类我个人觉得还存在一些牵强的地方,比如将能支持多种CAP配置的Dynamo和其衍生产品Cassandra归类为 AP,但是总体而言,这个分类还是相当不错,在现阶段非常具有参考价值,在每个相关的数据库后面还会介绍对应的数据模型。
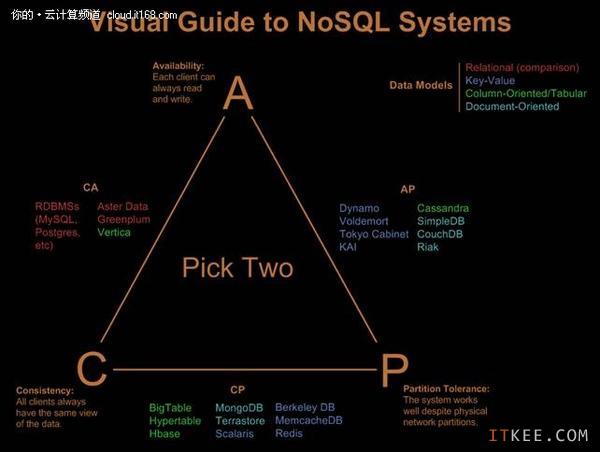
▲图1. NoSQL产品分类图(参考1)
NoSQL仅仅是一个概念,NoSQL数据库根据数据的存储模型和特点分为很多种类。
|
类型 |
部分代表 |
特点 |
|
列存储 |
Hbase Cassandra Hypertable |
顾名思义,是按列存储数据的。最大的特点是方便存储结构化和半结构化数据,方便做数据压缩,对针对某一列或者某几列的查询有非常大的IO优势。 |
|
文档存储 |
CouchDB |
文档存储一般用类似json的格式存储,存储的内容是文档型的。这样也就有有机会对某些字段建立索引,实现关系数据库的某些功能。 |
|
key-value存储 |
Tokyo Cabinet / Tyrant Berkeley DB MemcacheDB Redis |
可以通过key快速查询到其value。一般来说,存储不管value的格式,照单全收。(Redis包含了其他功能) |
|
图存储 |
Neo4J FlockDB |
图形关系的最佳存储。使用传统关系数据库来解决的话性能低下,而且设计使用不方便。 |
|
对象存储 |
db4o Versant |
通过类似面向对象语言的语法操作数据库,通过对象的方式存取数据。 |
|
xml数据库 |
Berkeley DB XML BaseX |
高效的存储XML数据,并支持XML的内部查询语法,比如XQuery,Xpath。 |
以上NoSQL数据库类型的划分并不是绝对,只是从存储模型上来进行的大体划分。它们之间没有绝对的分界,也有交差的情况,比如Tokyo Cabinet / Tyrant的Table类型存储,就可以理解为是文档型存储,Berkeley DB XML数据库是基于Berkeley DB之上开发的。
关注一致性和可用性的 (CA)
这些数据库对于分区容忍性方面比较不感冒,主要采用复制(Replication)这种方式来保证数据的安全性,常见的CA系统有:
1. 传统关系型数据库,比如Postgres和mysql等(Relational) ;
2. Vertica (Column-oriented) ;
3. Aster Data (Relational) ;
4. Greenplum (Relational) ;
关注一致性和分区容忍性的(CP)
这种系统将数据分布在多个网络分区的节点上,并保证这些数据的一致性,但是对于可用性的支持方面有问题,比如当集群出现问题的话,节点有可能因无法确保数据是一致性的而拒绝提供服务,主要的CP系统有:
2. Hypertable (Column-oriented);
3. HBase (Column-oriented) ;
4. MongoDB (Document) ;
5. Terrastore (Document) ;
6. Redis (Key-value) ;
7. Scalaris (Key-value) ;
8. MemcacheDB (Key-value) ;
9. Berkeley DB (Key-value) ;
关于可用性和分区容忍性的(AP)
这类系统主要以实现"最终一致性(Eventual Consistency)"来确保可用性和分区容忍性,AP的系统有:
1. Dynamo (Key-value);
2. Voldemort (Key-value) ;
3. Tokyo Cabinet (Key-value) ;
4. KAI (Key-value) ;
5. Cassandra (Column-oriented) ;
6. CouchDB (Document-oriented) ;
7. SimpleDB (Document-oriented) ;
8. Riak (Document-oriented) ;
以上是关于NOSQL数据模型和CAP原理的主要内容,如果未能解决你的问题,请参考以下文章