机器学习十大算法
Posted mat_wu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习十大算法相关的知识,希望对你有一定的参考价值。
文章来源:https://www.dezyre.com/article/top-10-machine-learning-algorithms/202
本人自行翻译,如有错误,还请指出。后续会继续补充实例及代码实现。
3.机器学习算法概述
3.1 朴素贝叶斯分类器算法
手动分类网页,文档,电子邮件或任何其他冗长的文本注释将是困难且实际上不可能的。 这是朴素贝叶斯分类器机器学习算法来解决。 分类器是从可用类别之一分配总体的元素值的函数。 例如,垃圾邮件过滤是朴素贝叶斯分类器算法的流行应用程序。 此处的垃圾邮件过滤器是一种分类器,可为所有电子邮件分配“垃圾邮件”或“不垃圾邮件”标签。
朴素贝叶斯分类器算法是最受欢迎的学习方法之一,按照相似性分类,用流行的贝叶斯概率定理来建立机器学习模型,特别是用于疾病预测和文档分类。 它是基于贝叶斯概率定理的单词的内容的主观分析的简单分类。
什么时候使用机器学习算法 - 朴素贝叶斯分类器?
(1)如果您有一个中等或大的训练数据集。
(2)如果实例具有几个属性。
(3)给定分类参数,描述实例的属性应该是条件独立的。
A.朴素贝叶斯分类器的应用
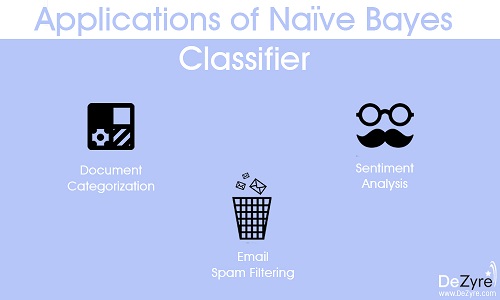
(1)情绪分析 - 用于Facebook分析表示积极或消极情绪的状态更新。
(2)文档分类 - Google使用文档分类来索引文档并查找相关性分数,即PageRank。 PageRank机制考虑在使用文档分类技术解析和分类的数据库中标记为重要的页面。
(3)朴素贝叶斯算法也用于分类关于技术,娱乐,体育,政治等的新闻文章。
(4)电子邮件垃圾邮件过滤 - Google Mail使用NaïveBayes算法将您的电子邮件归类为垃圾邮件或非垃圾邮件。
B.朴素贝叶斯分类器机器学习算法的优点
(1)当输入变量是分类时,朴素贝叶斯分类器算法执行得很好。
(2)当朴素贝叶斯条件独立假设成立时,朴素贝叶斯分类器收敛更快,需要相对较少的训练数据,而不像其他判别模型,如逻辑回归。
(3)使用朴素贝叶斯分类器算法,更容易预测测试数据集的类。 多等级预测的好赌注。
(4)虽然它需要条件独立假设,但是朴素贝叶斯分类器在各种应用领域都表现出良好的性能。
Python中的数据科学库实现NaïveBayes - Sci-Kit学习
数据科学图书馆在R实施朴素贝叶斯 - e1071
3.2 K均值聚类算法
K-means是用于聚类分析的普遍使用的无监督机器学习算法。 K-Means是一种非确定性和迭代的方法。 该算法通过预定数量的簇k对给定数据集进行操作。 K Means算法的输出是具有在簇之间分割的输入数据的k个簇。
例如,让我们考虑维基百科搜索结果的K均值聚类。 维基百科上的搜索词“Jaguar”将返回包含Jaguar这个词的所有页面,它可以将Jaguar称为Car,Jaguar称为Mac OS版本,Jaguar作为动物。 K均值聚类算法可以应用于对描述类似概念的网页进行分组。 因此,算法将把所有谈论捷豹的网页作为一个动物分组到一个集群,将捷豹作为一个汽车分组到另一个集群,等等。
A.使用K-means聚类机学习算法的优点
(1)在球状簇的情况下,K-Means产生比层级聚类更紧密的簇。
(2)给定一个较小的K值,K-Means聚类计算比大量变量的层次聚类更快。
B.K-Means聚类的应用
K Means Clustering算法被大多数搜索引擎(如Yahoo,Google)用于通过相似性对网页进行聚类,并识别搜索结果的“相关率”。 这有助于搜索引擎减少用户的计算时间。
Python中的数据科学库实现K均值聚类 - SciPy,Sci-Kit学习,Python包装
数据科学库中的R实现K均值聚类 - 统计
3.3 支持向量机学习算法
支持向量机是一种分类或回归问题的监督机器学习算法,其中数据集教导关于类的SVM,以便SVM可以对任何新数据进行分类。 它通过找到将训练数据集分成类的线(超平面)将数据分类到不同的类中来工作。 由于存在许多这样的线性超平面,SVM算法尝试最大化所涉及的各种类之间的距离,并且这被称为边际最大化。 如果识别出最大化类之间的距离的线,则增加对未看见数据良好推广的概率。
A.SVM分为两类:
线性SVM - 在线性SVM中,训练数据,即分类器由超平面分离。
非线性SVM在非线性SVM中,不可能使用超平面来分离训练数据。 例如,用于面部检测的训练数据由作为面部的一组图像和不是面部的另一组图像(换句话说,除了面部之外的所有其他图像)组成。 在这种条件下,训练数据太复杂,不可能找到每个特征向量的表示。 将面的集合与非面的集线性分离是复杂的任务。
B.使用SVM的优点
(1)SVM对训练数据提供最佳分类性能(精度)。
(2)SVM为未来数据的正确分类提供了更高的效率。
(3)SVM的最好的事情是它不对数据做任何强有力的假设。
(4)它不会过度拟合数据。
C.支持向量机的应用
(1)SVM通常用于各种金融机构的股票市场预测。 例如,它可以用来比较股票相对于同一行业中其他股票的表现的相对表现。 股票的相对比较有助于管理基于由SVM学习算法做出的分类的投资决策。
(2)Python中的数据科学库实现支持向量机-SciKit学习,PyML,SVMStruct Python,LIBSVM
(3)R中的数据科学库实现支持向量机 - klar,e1071
3.4 Apriori机器学习算法
Apriori算法是无监督机器学习算法,其从给定数据集生成关联规则。 关联规则意味着如果项目A出现,则项目B也以一定概率出现。 生成的大多数关联规则采用IF_THEN格式。 例如,如果人们买了一个iPad,他们还买了一个iPad保护套。 为了得到这样的结论的算法,它首先观察购买iPad的人购买iPad的人数。 这样一来,比例就像100个购买iPad的人一样,85个人还购买了一个iPad案例。
A.Apriori机器学习算法的基本原理:
如果项集合频繁出现,则项集合的所有子集也频繁出现。
如果项集合不经常出现,则项集合的所有超集都不经常出现。
B.先验算法的优点
(1)它易于实现并且可以容易地并行化。
(2)Apriori实现使用大项目集属性。
C.Apriori算法应用

检测不良药物反应
Apriori算法用于关于医疗数据的关联分析,例如患者服用的药物,每个患者的特征,不良的不良反应患者体验,初始诊断等。该分析产生关联规则,其帮助识别患者特征和药物的组合 导致药物的不良副作用。
市场篮子分析
许多电子商务巨头如亚马逊使用Apriori来绘制数据洞察,哪些产品可能是一起购买,哪些是最响应促销。 例如,零售商可能使用Apriori预测购买糖和面粉的人很可能购买鸡蛋来烘烤蛋糕。
自动完成应用程序
Google自动完成是Apriori的另一个流行的应用程序,其中 - 当用户键入单词时,搜索引擎寻找人们通常在特定单词之后键入的其他相关联的单词。
Python中的数据科学库实现Apriori机器学习算法 - 在PyPi中有一个python实现Apriori
数据科学库在R中实现Apriori机器学习算法 – arules
3.5 线性回归机器学习算法
线性回归算法显示了2个变量之间的关系,以及一个变量中的变化如何影响另一个变量。 该算法显示了在改变自变量时对因变量的影响。 自变量被称为解释变量,因为它们解释了因变量对因变量的影响。 依赖变量通常被称为感兴趣的因子或预测因子。
A.线性回归机器学习算法的优点
(1)它是最可解释的机器学习算法之一,使得它很容易解释给别人。
(2)它易于使用,因为它需要最小的调谐。
(3)它是最广泛使用的机器学习技术运行快。
B.线性回归算法应用

估计销售额
线性回归在业务中有很大的用途,基于趋势的销售预测。如果公司每月的销售额稳步增长 - 对月度销售数据的线性回归分析有助于公司预测未来几个月的销售额。
风险评估
线性回归有助于评估涉及保险或金融领域的风险。健康保险公司可以对每个客户的索赔数量与年龄进行线性回归分析。这种分析有助于保险公司发现,老年顾客倾向于提出更多的保险索赔。这样的分析结果在重要的商业决策中起着至关重要的作用,并且是为了解决风险。
Python中的数据科学库实现线性回归 - statsmodel和SciKit
R中的数据科学库实现线性回归 - 统计
3.6 决策树机器学习算法
你正在制作一个周末计划,去访问最好的餐馆在城里,因为你的父母访问,但你是犹豫的决定在哪家餐厅选择。每当你想去一家餐馆,你问你的朋友提利昂如果他认为你会喜欢一个特定的地方。为了回答你的问题,提利昂首先要找出,你喜欢的那种餐馆。你给他一个你去过的餐馆列表,告诉他你是否喜欢每个餐厅(给出一个标记的训练数据集)。当你问提利昂你是否想要一个特定的餐厅R,他问你各种问题,如“是”R“屋顶餐厅?”,“餐厅”R“服务意大利菜吗?”,现场音乐?“,”餐厅R是否营业至午夜?“等等。提利昂要求您提供几个信息问题,以最大限度地提高信息收益,并根据您对问卷的答案给予YES或NO回答。这里Tyrion是你最喜欢的餐厅偏好的决策树。
决策树是一种图形表示,其使用分支方法来基于某些条件来例示决策的所有可能的结果。在决策树中,内部节点表示对属性的测试,树的每个分支表示测试的结果,叶节点表示特定类标签,即在计算所有属性之后作出的决定。分类规则通过从根到叶节点的路径来表示。
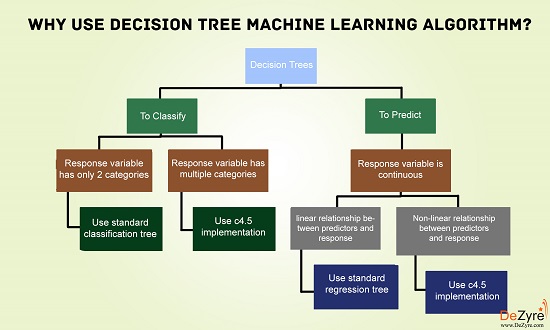
A.决策树的类型
(1)分类树 - 这些被视为用于基于响应变量将数据集分成不同类的默认种类的决策树。 这些通常在响应变量本质上是分类时使用。
(2)回归树 - 当响应或目标变量是连续或数字时,使用回归树。 与分类相比,这些通常用于预测类型的问题。
根据目标变量的类型 - 连续变量决策树和二进制变量决策树,决策树也可以分为两种类型。 它是有助于决定对于特定问题需要什么样的决策树的目标变量。
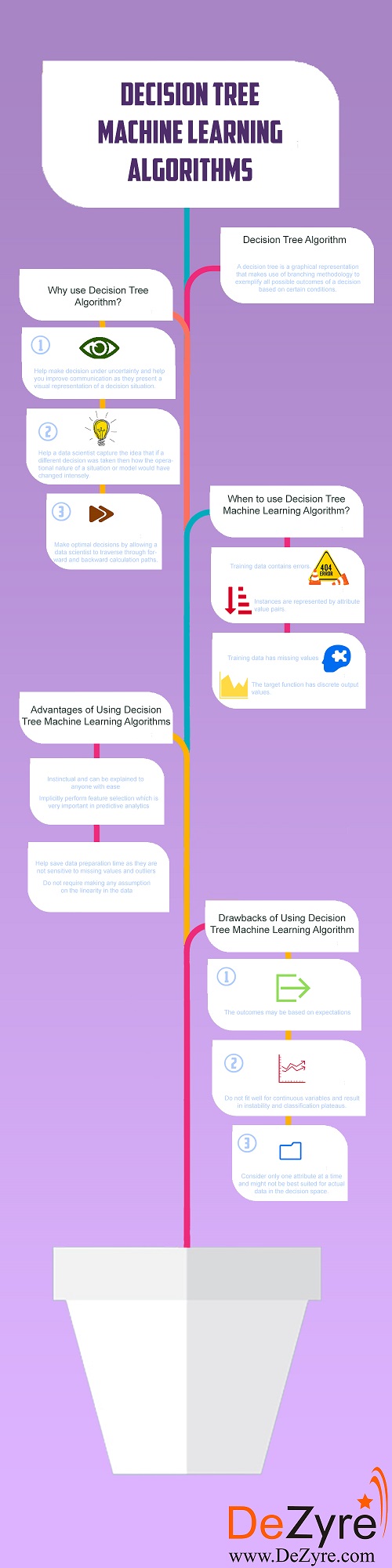
B.为什么选择决策树算法?
(1)这些机器学习算法有助于在不确定性下作出决策,并帮助您改善沟通,因为他们提供了决策情况的可视化表示。
(2)决策树机器学习算法帮助数据科学家捕获这样的想法:如果采取了不同的决策,那么情境或模型的操作性质将如何剧烈变化。
(3)决策树算法通过允许数据科学家遍历前向和后向计算路径来帮助做出最佳决策。
C.何时使用决策树机器学习算法
(1)决策树对错误是鲁棒的,并且如果训练数据包含错误,则决策树算法将最适合于解决这样的问题。
(2)决策树最适合于实例由属性值对表示的问题。
(3)如果训练数据具有缺失值,则可以使用决策树,因为它们可以通过查看其他列中的数据来很好地处理丢失的值。
(4)当目标函数具有离散输出值时,决策树是最适合的。
D.决策树的优点
(1)决策树是非常本能的,可以向任何人轻松解释。来自非技术背景的人,也可以解释从决策树绘制的假设,因为他们是不言自明的。
(2)当使用决策树机器学习算法时,数据类型不是约束,因为它们可以处理分类和数值变量。
(3)决策树机器学习算法不需要对数据中的线性进行任何假设,因此可以在参数非线性相关的情况下使用。这些机器学习算法不对分类器结构和空间分布做出任何假设。
(4)这些算法在数据探索中是有用的。决策树隐式执行特征选择,这在预测分析中非常重要。当决策树适合于训练数据集时,在其上分割决策树的顶部的节点被认为是给定数据集内的重要变量,并且默认情况下完成特征选择。
(5)决策树有助于节省数据准备时间,因为它们对缺失值和异常值不敏感。缺少值不会阻止您拆分构建决策树的数据。离群值也不会影响决策树,因为基于分裂范围内的一些样本而不是准确的绝对值发生数据分裂。
E.决策树的缺点
(1)树中决策的数量越多,任何预期结果的准确性越小。
(2)决策树机器学习算法的主要缺点是结果可能基于预期。当实时做出决策时,收益和产生的结果可能与预期或计划不同。有机会,这可能导致不现实的决策树导致错误的决策。任何不合理的期望可能导致决策树分析中的重大错误和缺陷,因为并不总是可能计划从决策可能产生的所有可能性。
(3)决策树不适合连续变量,并导致不稳定性和分类高原。
(4)与其他决策模型相比,决策树很容易使用,但是创建包含几个分支的大决策树是一个复杂和耗时的任务。
(5)决策树机器学习算法一次只考虑一个属性,并且可能不是最适合于决策空间中的实际数据。
(6)具有多个分支的大尺寸决策树是不可理解的,并且造成若干呈现困难。
F.决策树机器学习算法的应用
(1)决策树是流行的机器学习算法之一,它在财务中对期权定价有很大的用处。
(2)遥感是基于决策树的模式识别的应用领域。
(3)银行使用决策树算法按贷款申请人违约付款的概率对其进行分类。
(4)Gerber产品公司,一个流行的婴儿产品公司,使用决策树机器学习算法来决定他们是否应继续使用塑料PVC(聚氯乙烯)在他们的产品。
(5)Rush大学医学中心开发了一个名为Guardian的工具,它使用决策树机器学习算法来识别有风险的患者和疾病趋势。
Python语言中的数据科学库实现决策树机器学习算法是 - SciPy和Sci-Kit学习。
R语言中的数据科学库实现决策树机器学习算法是插入符号。
3.7 随机森林机器学习算法
让我们继续我们在决策树中使用的同样的例子,来解释随机森林机器学习算法如何工作。提利昂是您的餐厅偏好的决策树。然而,提利昂作为一个人并不总是准确地推广你的餐厅偏好。要获得更准确的餐厅推荐,你问一对夫妇的朋友,并决定访问餐厅R,如果大多数人说你会喜欢它。而不是只是问Tyrion,你想问问Jon Snow,Sandor,Bronn和Bran谁投票决定你是否喜欢餐厅R或不。这意味着您已经构建了决策树的合奏分类器 - 也称为森林。
你不想让所有的朋友给你相同的答案 - 所以你提供每个朋友略有不同的数据。你也不确定你的餐厅偏好,是在一个困境。你告诉提利昂你喜欢开顶屋顶餐厅,但也许,只是因为它是在夏天,当你访问的餐厅,你可能已经喜欢它。在寒冷的冬天,你可能不是餐厅的粉丝。因此,所有的朋友不应该利用你喜欢打开的屋顶餐厅的数据点,以提出他们的建议您的餐厅偏好。
通过为您的朋友提供略微不同的餐厅偏好数据,您可以让您的朋友在不同时间向您询问不同的问题。在这种情况下,只是稍微改变你的餐厅偏好,你是注入随机性在模型级别(不同于决策树情况下的数据级别的随机性)。您的朋友群现在形成了您的餐厅偏好的随机森林。
随机森林是一种机器学习算法,它使用装袋方法来创建一堆随机数据子集的决策树。模型在数据集的随机样本上进行多次训练,以从随机森林算法中获得良好的预测性能。在该整体学习方法中,将随机森林中所有决策树的输出结合起来进行最终预测。随机森林算法的最终预测通过轮询每个决策树的结果或者仅仅通过使用在决策树中出现最多次的预测来导出。
例如,在上面的例子 - 如果5个朋友决定你会喜欢餐厅R,但只有2个朋友决定你不会喜欢的餐厅,然后最后的预测是,你会喜欢餐厅R多数总是胜利。
A.为什么使用随机森林机器学习算法?
(1)有很多好的开源,在Python和R中可用的算法的自由实现。
(2)它在缺少数据时保持准确性,并且还能抵抗异常值。
(3)简单的使用作为基本的随机森林算法可以实现只用几行代码。
(4)随机森林机器学习算法帮助数据科学家节省数据准备时间,因为它们不需要任何输入准备,并且能够处理数字,二进制和分类特征,而无需缩放,变换或修改。
(5)隐式特征选择,因为它给出了什么变量在分类中是重要的估计。
B.使用随机森林机器学习算法的优点
(1)与决策树机器学习算法不同,过拟合对随机森林不是一个问题。没有必要修剪随机森林。
(2)这些算法很快,但不是在所有情况下。随机森林算法当在具有100个变量的数据集的800MHz机器上运行时,并且50,000个案例在11分钟内产生100个决策树。
(3)随机森林是用于各种分类和回归任务的最有效和通用的机器学习算法之一,因为它们对噪声更加鲁棒。
(4)很难建立一个坏的随机森林。在随机森林机器学习算法的实现中,容易确定使用哪些参数,因为它们对用于运行算法的参数不敏感。一个人可以轻松地建立一个体面的模型没有太多的调整
(5)随机森林机器学习算法可以并行生长。
(6)此算法在大型数据库上高效运行。
(7)具有较高的分类精度。
C.使用随机森林机器学习算法的缺点
他们可能很容易使用,但从理论上分析它们是很困难的。
随机森林中大量的决策树可以减慢算法进行实时预测。
如果数据由具有不同级别数量的分类变量组成,则算法会偏好具有更多级别的那些属性。 在这种情况下,可变重要性分数似乎不可靠。
当使用RandomForest算法进行回归任务时,它不会超出训练数据中响应值的范围。
D.随机森林机器学习算法的应用
(1)随机森林算法被银行用来预测贷款申请人是否可能是高风险。
(2)它们用于汽车工业中以预测机械部件的故障或故障。
(3)这些算法用于医疗保健行业以预测患者是否可能发展成慢性疾病。
(4)它们还可用于回归任务,如预测社交媒体份额和绩效分数的平均数。
(5)最近,该算法也已经被用于预测语音识别软件中的模式并对图像和文本进行分类。
Python语言中的数据科学库实现随机森林机器学习算法是Sci-Kit学习。
R语言的数据科学库实现随机森林机器学习算法randomForest。

3.8逻辑回归
这个算法的名称可能有点混乱,在逻辑回归机器学习算法是分类任务,而不是回归问题的意义上。名称“回归”在这里意味着线性模型拟合到特征空间中。该算法将逻辑函数应用于特征的线性组合,以基于预测变量来预测分类依赖变量的结果。
描述单个试验的结果的几率或概率被建模为解释变量的函数。逻辑回归算法有助于基于给定的预测变量估计落入分类依赖变量的特定级别的概率。
假设你想预测明天在纽约是否会有降雪。这里,预测的结果不是连续的数字,因为将存在降雪或没有降雪,因此不能应用线性回归。这里的结果变量是几个类别之一,并使用逻辑回归有帮助。
(剩余内容等待更新后继续补充)
以上是关于机器学习十大算法的主要内容,如果未能解决你的问题,请参考以下文章