[How to] 使用HBase协处理器---Endpoint客户端代码的实现
Posted 小马过溪
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[How to] 使用HBase协处理器---Endpoint客户端代码的实现相关的知识,希望对你有一定的参考价值。
1.简介
不同于Observer协处理器,EndPoint由于需要同region进行rpc服务的通信,以及客户端出数据的归并,需要自行实现客户端代码。
基于[How to] 使用HBase协处理器---Endpoint服务端的实现这篇文章,我们继续实现其客户端代码。
2.客户端代码实现方式介绍
目前基于HBase1.0.0的版本客户端一共可以基于以下五个API来实现:
1. Table.coprocessorService(byte[])
基于单个region的服务请求,参数为rowKey值,被请求的对象为此rowKey值参数所在的region
2. Table.coprocessorService(Class, byte[], byte[],Batch.Call)
基于rowKey范围的服务请求,第二和第三个参数为startKey和stopKey,被请求的region为rowkey范围内的region。
客户端并行的通过Class类型获取服务类型,通过Batch.Call调用服务接口,然后在客户端进行返回值的结果归并计算。
3. Table.coprocessorService(Class, byte[], byte[], Batch.Call, Batch.Callback)
与上述2类似,只是使用到了Batch.Callback方式,具体差异见后文分析。
4. Table.batchCoprocessorService(MethodDescriptor methodDescriptor, Message request, byte[] startKey, byte[] endKey, R responsePrototype)
批处理方式获取值,他将在regionserver上开启代理,代理将会调用当前regionserver上的目标region的服务接口。最后代理将归并这些值,然后返回给客户端。
5. Table.batchCoprocessorService(MethodDescriptor methodDescriptor, Message request, byte[] startKey, byte[] endKey, R responsePrototype, Callback<R> callback)
与4方法类似,具体差异见后文分析
3. 测试数据的准备
在coprocessor_table表中我们插入如下数据:
hbase(main):038:0> put \'coprocessor_table\',\'row1\',\'F:A\',\'1\' 0 row(s) in 0.0100 seconds hbase(main):039:0> put \'coprocessor_table\',\'row2\',\'F:A\',\'2\' 0 row(s) in 0.0050 seconds hbase(main):040:0> put \'coprocessor_table\',\'row3\',\'F:A\',\'3\' 0 row(s) in 0.0070 seconds hbase(main):041:0> put \'coprocessor_table\',\'row4\',\'F:A\',\'4\' 0 row(s) in 0.0050 seconds hbase(main):042:0> put \'coprocessor_table\',\'row5\',\'F:A\',\'5\' 0 row(s) in 0.0060 seconds hbase(main):006:0> put \'coprocessor_table\',\'row6\',\'F:A\',\'6\' 0 row(s) in 0.1370 seconds hbase(main):013:0> scan \'coprocessor_table\' ROW COLUMN+CELL row1 column=F:A, timestamp=1469853041043, value=1 row1 column=F:B, timestamp=1469853041043, value=1 row2 column=F:A, timestamp=1469853048597, value=2 row2 column=F:B, timestamp=1469853048597, value=2 row3 column=F:A, timestamp=1469853056871, value=3 row3 column=F:B, timestamp=1469853056871, value=3 row4 column=F:A, timestamp=1469853062544, value=4 row4 column=F:B, timestamp=1469853062544, value=4 row5 column=F:A, timestamp=1469853069914, value=5 row5 column=F:B, timestamp=1469853069914, value=5 row6 column=F:A, timestamp=1469859595584, value=6 row6 column=F:B, timestamp=1469859595584, value=6
由于受到Observer协处理器的影响B列也会被插入值。
为了后续测试的需要,我们将此表的region按照如下进行切割:

4. Table.coprocessorService(byte[])方式客户端代码实现
其原理为通过参数的rowKey值进行region的定位,通过向此region请求服务进行计算,计算的数据范围仅限此region。

其实现方法,注解见代码注解。
/** * 通过CoprocessorRpcChannel coprocessorService(byte[] row); 请求单region服务 * * 客户端通过rowKey的指定,指向rowKey所在的region进行服务请求,所以从数据上来说只有这个region所包含的数据范围 * 另外由于只向单个region请求服务,所以在客户端也没有必要在做归并操作。 * * @param config * @param tableName * @param rowkey * @param type * @param famillyName * @param columnName * @return * @throws IOException */ private static long singleRegionStatistics(Configuration config, String tableName, String rowkey, String type, String famillyName, String columnName) throws IOException { long result = 0; Table table = null; Connection connection = null; try { connection = ConnectionFactory.createConnection(config); table = connection.getTable(TableName.valueOf(tableName)); // 每一个region都加载了Endpoint协处理器,换句话说每一个region都能提供rpc的service服务,首先确定调用的范围 // 这里只通过一个rowkey来确定,不管在此表中此rowkey是否存在,只要某个region的范围包含了这个rowkey,则这个region就为客户端提供服务 CoprocessorRpcChannel channel = table.coprocessorService(rowkey .getBytes()); // 因为在region上可能会有很多不同rpcservice,所以必须确定你需要哪一个service MyStatisticsInterface.myStatisticsService.BlockingInterface service = MyStatisticsInterface.myStatisticsService .newBlockingStub(channel); // 构建参数,设置 RPC 入口参数 MyStatisticsInterface.getStatisticsRequest.Builder request = MyStatisticsInterface.getStatisticsRequest .newBuilder(); request.setType(type); if (null != famillyName) { request.setFamillyName(famillyName); } if (null != columnName) { request.setColumnName(columnName); } // 调用 RPC MyStatisticsInterface.getStatisticsResponse ret = service .getStatisticsResult(null, request.build()); // 解析结果,由于只向一个region请求服务,所以在客户端也就不存在去归并的操作 result = ret.getResult(); } catch (Exception e) { e.printStackTrace(); } finally { if (null != table) { table.close(); } if (null != connection) { connection.close(); } } return result; }
测试代码:
// 通过CoprocessorRpcChannel coprocessorService(byte[] row) // 请求单个region的rpc服务 System.out.println("singleRegionStatistics COUNT = " + singleRegionStatistics(config, "coprocessor_table", "row2", "COUNT", null, null)); System.out.println("singleRegionStatistics SUM = " + singleRegionStatistics(config, "coprocessor_table", "row2", "SUM", "F", "A"));
测试结果:
singleRegionStatistics COUNT = 2
singleRegionStatistics SUM = 3
结果分析:
因为我们指定的rowkey是row2,而这个rowkey是在第一个region上的,根据数据插入可知这个上面的数据如下(row3作为endkey并不属于当前region)。
所以其一共有两行数据,对于A列的加和为 1+2=3,结果正确。
row1 column=F:A, timestamp=1469853041043, value=1 row1 column=F:B, timestamp=1469853041043, value=1 row2 column=F:A, timestamp=1469853048597, value=2 row2 column=F:B, timestamp=1469853048597, value=2
5. Table.coprocessorService(Class, byte[], byte[],Batch.Call) 方式客户端代码实现
通过Table.coprocessorService(byte[])方式可以直接连到一个region,但是如果我们需要进行多个region的数据查询呢,甚至我们需要进行全表的数据查询呢?
我们可以简单的查找目标region的startKey然后在分别取调用Table.coprocessorService(byte[]),得到的结果值进行归并,这也可以,但是从效率和代码量维护性上来说都不是很好。HBase针对这种情况开放了Table.coprocessorService(Class, byte[], byte[],Batch.Call)这个API。
在这个API参数列表中,
Class代表所需要请求的服务,当前是我们定义在proto中的myStatisticsService服务。
byte[], byte[]参数指明了startRowKey和endRowKey,当都为null的时候即进行全表的全region的数据计算。
Batch.Call:需要自定义,API会根据如上参数信息并行的连接各个region,来执行这个参数中定义的call方法来执行接口方法的调用查询
此API会将各个region上的信息放入Map<regionname,result>的结构中,搜集所有的结果后返回给调用者,调用者在循环进行归并计算。
其基本的运行原理如图:

其实现方法如下,具体解释见代码注解。(照葫芦画瓢即可)
/** * 通过Table.coprocessorService(Class, byte[], byte[],Batch.Call) 请求多region服务 * * 在这个API参数列表中, * Class代表所需要请求的服务,当前是我们定义在proto中的myStatisticsService服务。 * byte[], byte[]参数指明了startRowKey和endRowKey,当都为null的时候即进行全表的全region的数据计算。 * Batch.Call:需要自定义,API会根据如上参数信息并行的连接各个region,来执行这个参数中定义的call方法来执行接口方法的调用查询 * 此API会将各个region上的信息放入Map<regionname,result>的结构中,搜集所有的结果后返回给调用者,调用者在循环进行归并计算。 * * @param config * @param tableName * @param startRowkey * @param endRowkey * @param type * @param famillyName * @param columnName * @return * @throws Throwable */ private static long multipleRegionsStatistics(Configuration config, String tableName, String startRowkey, String endRowkey, final String type, final String famillyName, final String columnName) throws Throwable { long result = 0; Table table = null; Connection connection = null; // 返回值接收,Map<region名称,计算结果> Map<byte[], getStatisticsResponse> results = null; try { connection = ConnectionFactory.createConnection(config); table = connection.getTable(TableName.valueOf(tableName)); // 第四个参数是接口类 Batch.Call。它定义了如何调用协处理器,用户通过重载该接口的 call() 方法来实现客户端的逻辑。在 call() 方法内,可以调用 RPC,并对返回值进行任意处理。 Batch.Call<myStatisticsService, getStatisticsResponse> callable = new Batch.Call<myStatisticsService, getStatisticsResponse>() { ServerRpcController controller = new ServerRpcController(); // 定义返回 BlockingRpcCallback<getStatisticsResponse> rpcCallback = new BlockingRpcCallback<getStatisticsResponse>(); // 下面重载 call 方法,API会连接到region后会运行call方法来执行服务的请求 @Override public getStatisticsResponse call(myStatisticsService instance) throws IOException { // Server 端会进行慢速的遍历 region 的方法进行统计 MyStatisticsInterface.getStatisticsRequest.Builder request = MyStatisticsInterface.getStatisticsRequest .newBuilder(); request.setType(type); if (null != famillyName) { request.setFamillyName(famillyName); } if (null != columnName) { request.setColumnName(columnName); } // RPC 接口方法调用 instance.getStatisticsResult(controller, request.build(), rpcCallback); // 直接返回结果,即该 Region 的 计算结果 return rpcCallback.get(); } }; /** * 通过Table.coprocessorService(Class, byte[], byte[],Batch.Call) 请求多region服务 * * 在这个API参数列表中, * Class代表所需要请求的服务,当前是我们定义在proto中的myStatisticsService服务。 * byte[], byte[]参数指明了startRowKey和endRowKey,当都为null的时候即进行全表的全region的数据计算。 * Batch.Call:需要自定义,API会根据如上参数信息并行的连接各个region,来执行这个参数中定义的call方法来执行接口方法的调用查询 * 此API会将各个region上的信息放入Map<regionname,result>的结构中,搜集所有的结果后返回给调用者,调用者在循环进行归并计算。 */ results = table.coprocessorService(myStatisticsService.class, Bytes.toBytes(startRowkey), Bytes.toBytes(endRowkey), callable); // 取得结果值后循环将结果合并,即得到最终的结果 Collection<getStatisticsResponse> resultsc = results.values(); for (getStatisticsResponse r : resultsc) { result += r.getResult(); } } catch (Exception e) { e.printStackTrace(); } finally { if (null != table) { table.close(); } if (null != connection) { connection.close(); } } return result; }
测试代码:
// 通过Table.coprocessorService(Class, byte[], byte[],Batch.Call) // 请求多个region的rpc服务 // 计算指定rowkey范围所在的region上的数据行数 System.out.println("multipleRegionsStatistics COUNT = " + multipleRegionsStatistics(config, "coprocessor_table", "row1","row3", "COUNT", null, null)); // 计算指定rowkey范围所在的region上的F列族下的A列的值得求和 System.out.println("multipleRegionsStatistics SUM = " + multipleRegionsStatistics(config, "coprocessor_table", "row1","row3", "SUM", "F", "A"));
解释结果:
multipleRegionsStatistics COUNT = 4
multipleRegionsStatistics SUM = 10
结果分析:
如上API中都指定的开始key为row1,结束key为3,根据region的key分布可知其包含两个rengion,这个两个region根据key分布可知其key范围为:[null,row5),
根据之前插入记录可知为如下数据:
row1 column=F:A, timestamp=1469853041043, value=1 row1 column=F:B, timestamp=1469853041043, value=1 row2 column=F:A, timestamp=1469853048597, value=2 row2 column=F:B, timestamp=1469853048597, value=2 row3 column=F:A, timestamp=1469853056871, value=3 row3 column=F:B, timestamp=1469853056871, value=3 row4 column=F:A, timestamp=1469853062544, value=4 row4 column=F:B, timestamp=1469853062544, value=4
所以行数计算结果为4,sum计算结果为1+2+3+4=10,结果正确。
6. Table.coprocessorService(Class, byte[], byte[], Batch.Call, Batch.Callback) 客户端代码实现
Table.coprocessorService(Class, byte[], byte[],Batch.Call)方式为我们提供了多region的调用实现,其这个API会搜集各个region上服务的返回数据然后加到Map中并返回,这是他的默认行为,Table.coprocessorService(Class, byte[], byte[], Batch.Call, Batch.Callback)可以让我们有机会通过实现Callback来改变这样的数据搜集行为,比如我们可以不放到Map中,直接进行加和,加和完毕后直接返回结果值即可,调用者也不必劳神去循环取得进行加和处理了,系统也不必额外的去为数据集进行内存开销。
下面是这个API的运行原理图:
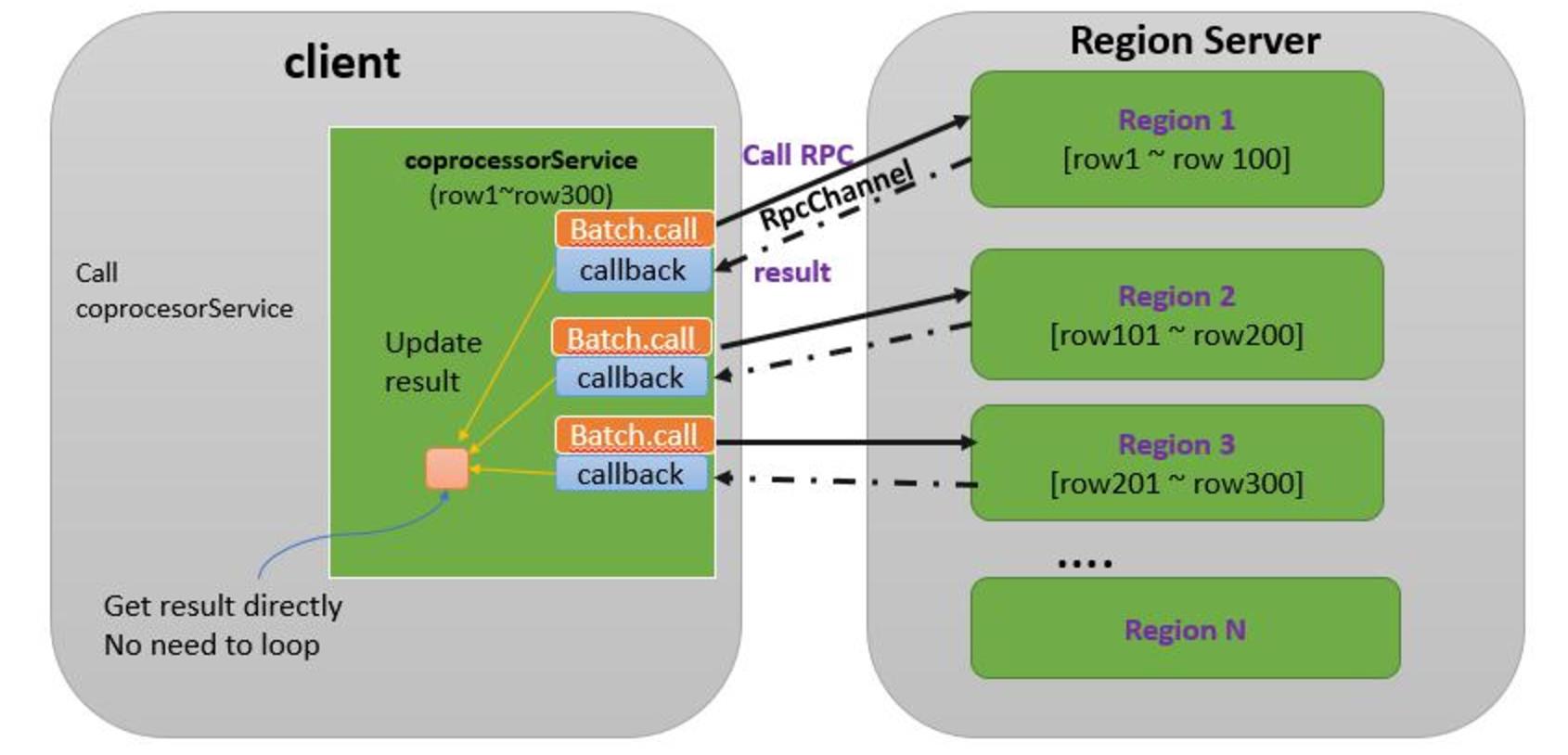
其实现方法如下,具体解释见代码注解。(照葫芦画瓢即可)
/** * 通过Table.coprocessorService(Class, byte[], byte[], Batch.Call, * Batch.Callback) 请求多region服务 * * 在这个API参数列表中, * Class代表所需要请求的服务,当前是我们定义在proto中的myStatisticsService服务。 * * byte[], * byte[]参数指明了startRowKey和endRowKey,当都为null的时候即进行全表的全region的数据计算。 * * Batch. * Call:需要自定义,API会根据如上参数信息并行的连接各个region,来执行这个参数中定义的call方法来执行接口方法的调用查询 * 此API会将各个region上的信结果信息放入Map通过Callback定义进行处理,处理完所有所有的结果后返回给调用者。 * * @param config * @param tableName * @param startRowkey * @param endRowkey * @param type * @param famillyName * @param columnName * @return * @throws Throwable */ private static long multipleRegionsCallBackStatistics(Configuration config, String tableName, String startRowkey, String endRowkey, final String type, final String famillyName, final String columnName) throws Throwable { final AtomicLong atoResult = new AtomicLong(); Table table = null; Connection connection = null; try { connection = ConnectionFactory.createConnection(config); table = connection.getTable(TableName.valueOf(tableName)); // 第四个参数是接口类 Batch.Call。它定义了如何调用协处理器,用户通过重载该接口的 call() 方法来实现客户端的逻辑。在 // call() 方法内,可以调用 RPC,并对返回值进行任意处理。 Batch.Call<myStatisticsService, getStatisticsResponse> callable = new Batch.Call<myStatisticsService, getStatisticsResponse>() { ServerRpcController controller = new ServerRpcController(); // 定义返回 BlockingRpcCallback<getStatisticsResponse> rpcCallback = new BlockingRpcCallback<getStatisticsResponse>(); // 下面重载 call 方法,API会连接到region后会运行call方法来执行服务的请求 @Override public getStatisticsResponse call(myStatisticsService instance) throws IOException { // Server 端会进行慢速的遍历 region 的方法进行统计 MyStatisticsInterface.getStatisticsRequest.Builder request = MyStatisticsInterface.getStatisticsRequest .newBuilder(); request.setType(type); if (null != famillyName) { request.setFamillyName(famillyName); } if (null != columnName) { request.setColumnName(columnName); } // RPC 接口方法调用 instance.getStatisticsResult(controller, request.build(), rpcCallback); // 直接返回结果,即该 Region 的 计算结果 return rpcCallback.get(); } }; // 定义 callback Batch.Callback<getStatisticsResponse> callback = new Batch.Callback<getStatisticsResponse>() { @Override public void update(byte[] region, byte[] row, getStatisticsResponse result) { // 直接将 Batch.Call 的结果,即单个 region 的 计算结果 累加到 atoResult atoResult.getAndAdd(result.getResult()); } }; /** * 通过Table.coprocessorService(Class, byte[], * byte[],Batch.Call,Batch.Callback) 请求多region服务 * * 在这个API参数列表中, * * Class代表所需要请求的服务,当前是我们定义在proto中的myStatisticsService服务。 * * byte[], * byte[]参数指明了startRowKey和endRowKey,当都为null的时候即进行全表的全region的数据计算。 * * Batch.Call:需要自定义,API会根据如上参数信息并行的连接各个region, * 来执行这个参数中定义的call方法来执行接口方法的调用查询 * 此API会将各个region上的信结果信息放入Map通过Callback定义进行处理,处理完所有所有的结果后返回给调用者。 */ table.coprocessorService(myStatisticsService.class, Bytes.toBytes(startRowkey), Bytes.toBytes(endRowkey), callable, callback); } catch (Exception e) { e.printStackTrace(); } finally { if (null != table) { table.close(); } if (null != connection) { connection.close(); } } return atoResult.longValue(); }
上述代码和非call方式上差别不大,唯一的差别是定义Batch.Callback实例,通过此实例进行结果值得加和处理,由于直接进行了处理,所以这个方法是没有返回值的,调用者需要在调用侧开启一个保存结果的实例,调用完毕后直接返回这个结果实例即可。
测试和验证方法同 Table.coprocessorService(Class, byte[], byte[],Batch.Call)
6. Table.batchCoprocessorService(MethodDescriptor methodDescriptor, Message request, byte[] startKey, byte[] endKey, R responsePrototype)实现
7. Table.batchCoprocessorService(MethodDescriptor methodDescriptor, Message request, byte[] startKey, byte[] endKey, R responsePrototype, Callback<R> callback)实现
如前所述,客户端会直接通过网络调用region进行服务请求,如果表比较大,region比较多,这个时候势必会对网络IO造成压力,上述两个方法的原理即是通过在目标region所在的regionserver上开启调用代理,由代理来调用region上的服务,并归并结果后返回客户端,好处在于客户端只要少量的网络请求即可。减小带宽压力。
基本原理:

实现方法:
略。
8.总结:
使用框架则必须准守框架规定,框架是固定的,所以上述代码中对于框架的代码都可重用。
HBase的协处理器为客户端在不修改和重编译源码的情况下增加定制功能,还是很强大的,但是协处理器的增加势必湖造成性能的降低,如Observer协处理器过多的话那么对于插入读取都会有影响,所以不能再协处理器中加入过多逻辑,简单化是必须的。
参考:
http://www.ibm.com/developerworks/cn/opensource/os-cn-hbase-coprocessor2/index.html
代码下载:
https://github.com/xufeng79x/Test-HBase-Endpoint
以上是关于[How to] 使用HBase协处理器---Endpoint客户端代码的实现的主要内容,如果未能解决你的问题,请参考以下文章