某人在企业中遇到的Spark问题记录[持续更新]
Posted 十光年
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了某人在企业中遇到的Spark问题记录[持续更新]相关的知识,希望对你有一定的参考价值。
https://github.com/ssg-7max/ssg
- 目前 ssg内公司内部 spark streaming 处理数据源是kafka
- 目前遇到最大的问题是,会延迟,例如我们配置1分钟让窗口计算一次,很有可能随着数据量大,我们计算时间会超过1分钟,这样就会导致卡死在哪里,streaming一直累计算出不了结果,而且从监控还看不出有问题,只有从结果监控发现结果出不来。 解决方案:增加kafka的partition配置,配合streaming的线程数,可以加快执行速度
- 使用createStream接受消息,升级kafka的API后遇到receiver无声无色地死掉的情况 解决方案:改为KafkaUtils.createDirectStream 要配置kafka的参数:metadata.broker.list val kafkaParams = MapString, Stringauto.offset.reset,这个参数是,切换groupid之后,重头开始获取数据 val registerDS = KafkaUtils.createDirectStreamString, String, StringDecoder, StringDecoder.map(_._2)
- yarn分配executor时,会比较集中在一些机器上,如下面的图,集中到026上面了。
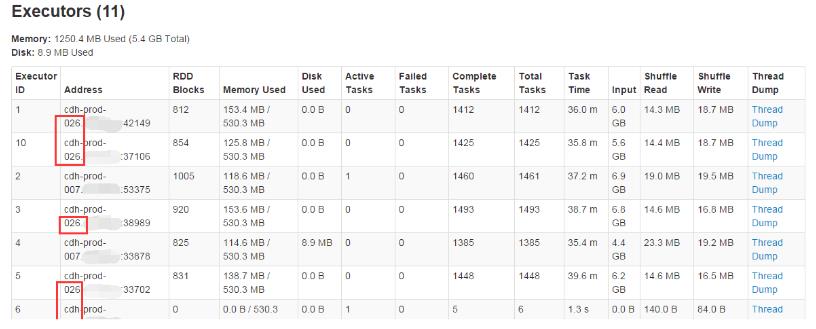
解决方案:目前还没有找问题解决方案,属于yarn的分配策略 - 对于连接池,为了提高效率,方面复用,可以通过广播变量方式 解决方案:广播变量不可以实现,在streaming中,而且executor之间传递这个,是需要序列化的,序列化一个已经连接的东西,是不行的,实际上是每个executor都去连接一下db, 最后结果不大,产生的连接数也不会多, 这样每个RDD都要去建立连接,insert DB。如果rdd过多,每次去连接是很浪费资源的,那缩减RDD的数量,当结果集很小的时候,通过reparation来处理,这样的话,就只有一个RDD在连接db。连接池解决资源复用的问题,根本上还是要控制发起连接的RDD数量,建议参考:http://blog.csdn.net/kntao/article/details/45364761
- kafka的partition数量和什么有关系? 解决方案:kafka的partition数量跟broker ×每个broker中的partition 有关 ,默认 不配置 每个broker partition是1
- spark streming运行时候报错“DStream checkpointing has been enabled but the DStreams with their functions are not serializable” 代码截图:
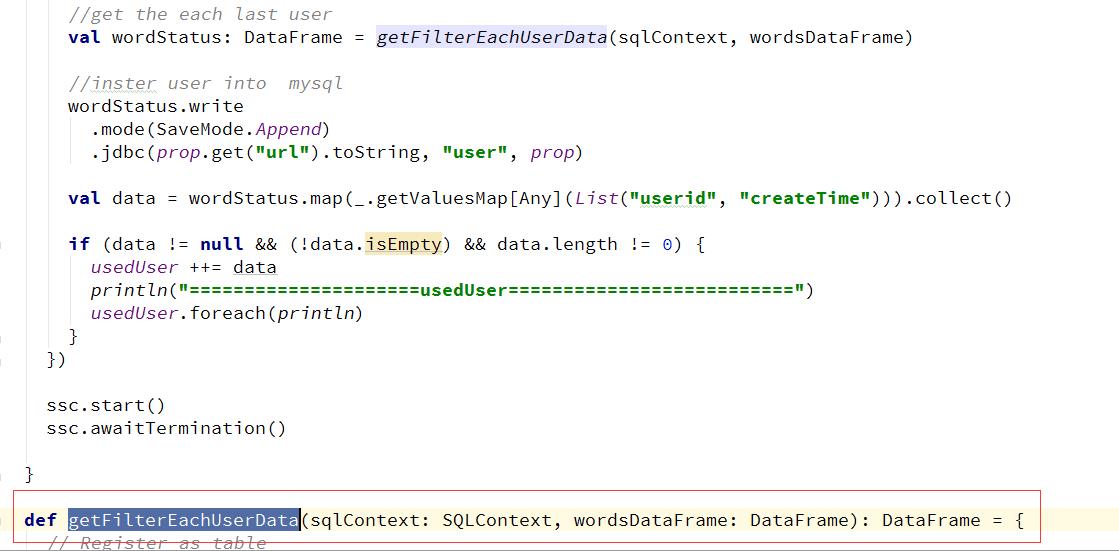 解决方案:通过跟群里面人讨论,发现getFilterEachUserData(),第一个参数sqlContext是没有序列化的,去掉第一个参数后,不再包此错误
解决方案:通过跟群里面人讨论,发现getFilterEachUserData(),第一个参数sqlContext是没有序列化的,去掉第一个参数后,不再包此错误 - spark streaming 不能toDF? 代码截图:
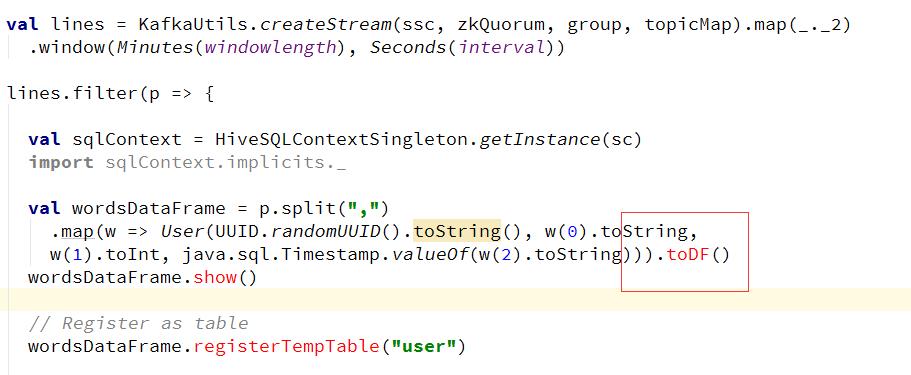 解决方案:filter 方法中,p不是rdd,要想转成rdd需要使用transform这个方法 修改后代码截图:
解决方案:filter 方法中,p不是rdd,要想转成rdd需要使用transform这个方法 修改后代码截图: 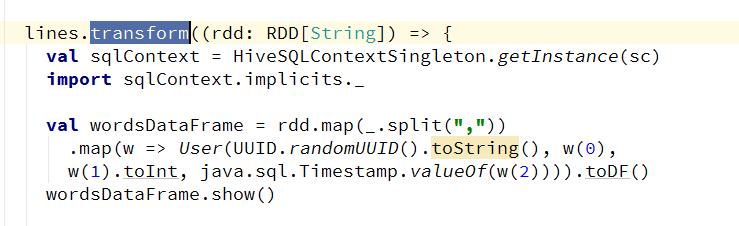
- 群中有人说spark streaming中不能同时使用广播变量和checkpoint? 解决方案:这个问题需要有待核实
- Couldn\'t find leader offsets for Set ([luwc_test,0],[luwc_test,1]) 异常问题截图:
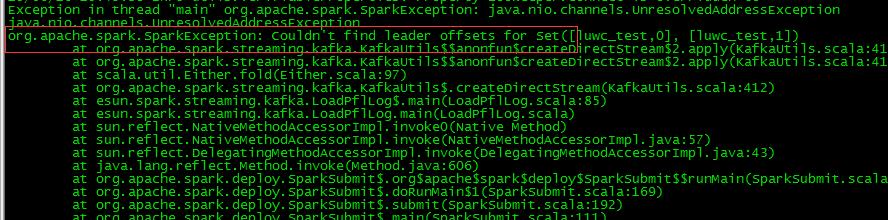 解决方案:要在kafka集群的hosts要配到spark的Driver的hosts里面去,用zk管kafka的话,是可以获取到Partition信息的,但是解析地址会失败,把hosts配成一致就可以了,直接用domain是不行的
解决方案:要在kafka集群的hosts要配到spark的Driver的hosts里面去,用zk管kafka的话,是可以获取到Partition信息的,但是解析地址会失败,把hosts配成一致就可以了,直接用domain是不行的 - spark 编译源码 增加hive模块 解决方案:export MAVEN_OPTS="-Xmx2g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m" mvn -Pyarn -Phadoop-2.3 -Dhadoop.version=2.3.0-cdh5.1.0 -Phive -Dhive-version=0.12.0-cdh5.1.0 -Phive-thriftserver -Pspark-ganglia-lgpl -DskipTests clean package OR ./make-distribution.sh --name 2.3.0 --tgz -Phadoop-2.3 -Dhadoop.version=2.3.0-cdh5.1.0 -Pyarn -Phive -Dhive-version=0.12.0-cdh5.1.0 -Phive-thriftserver -Pspark-ganglia-lgpl -DskipTests clean package
以上是关于某人在企业中遇到的Spark问题记录[持续更新]的主要内容,如果未能解决你的问题,请参考以下文章