MLlib特征变换方法
Posted Tensor
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MLlib特征变换方法相关的知识,希望对你有一定的参考价值。
Spark1.6.2.2.3
PCA
算法介绍:
主成分分析是一种统计学方法,它使用正交转换从一系列可能相关的变量中提取线性无关变量集,提取出的变量集中的元素称为主成分。使用PCA方法可以对变量集合进行降维。下面的示例将会展示如何将5维特征向量转换为3维主成分向量。
scala代码
import org.apache.spark.ml.feature.PCA import org.apache.spark.ml.linalg.Vectors val data = Array( Vectors.sparse(5, Seq((1, 1.0), (3, 7.0))), Vectors.dense(2.0, 0.0, 3.0, 4.0, 5.0), Vectors.dense(4.0, 0.0, 0.0, 6.0, 7.0) ) val df = spark.createDataFrame(data.map(Tuple1.apply)).toDF("features") val pca = new PCA() .setInputCol("features") .setOutputCol("pcaFeatures") .setK(3) .fit(df) val pcaDF = pca.transform(df) val result = pcaDF.select("pcaFeatures") result.show()
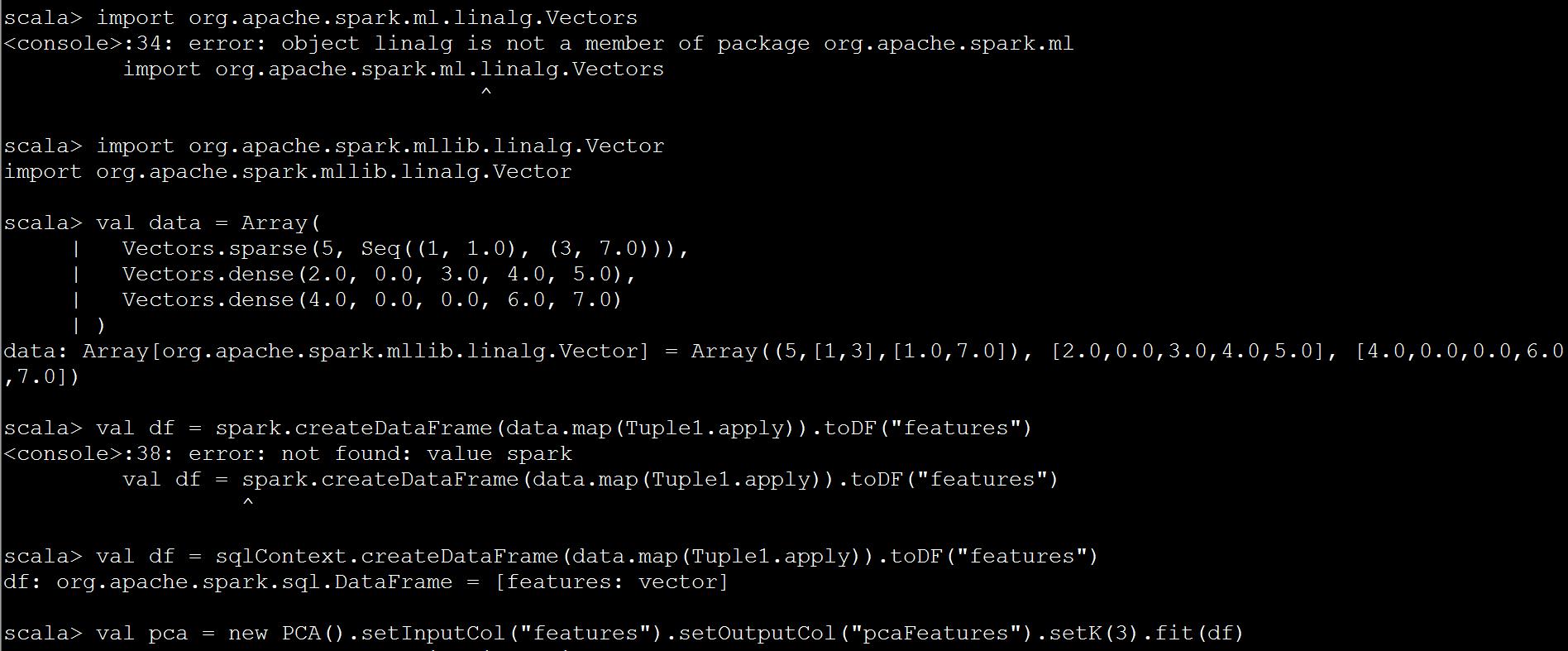
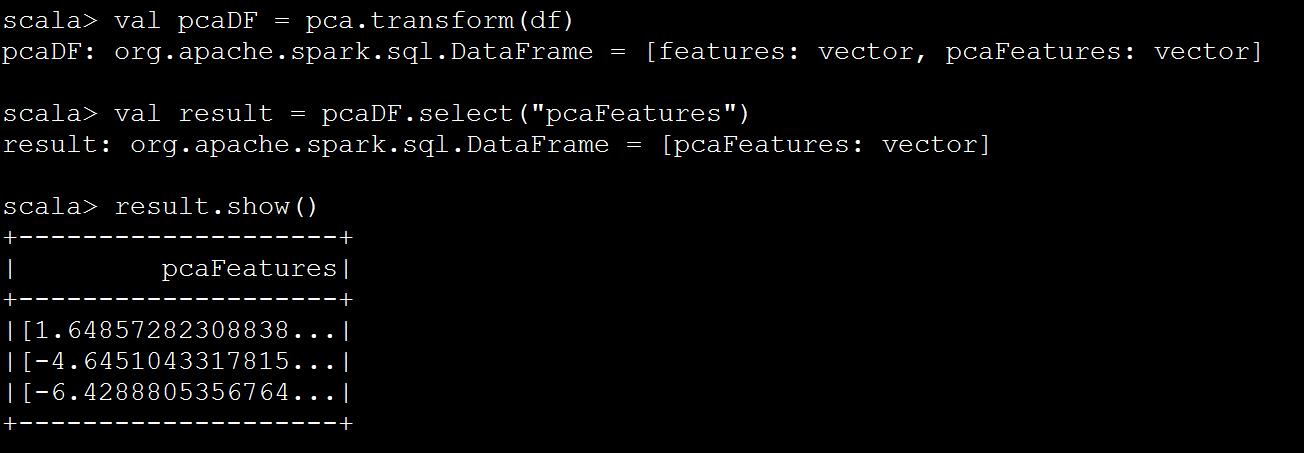
由于是spark1.6.2。api有些不能用。
OneHotEncoder
算法介绍:
独热编码将标签指标映射为二值向量,其中最多一个单值。这种编码被用于将种类特征使用到需要连续特征的算法,如逻辑回归等。
scala代码
import org.apache.spark.ml.feature.{OneHotEncoder, StringIndexer} val df = spark.createDataFrame(Seq( (0, "a"), (1, "b"), (2, "c"), (3, "a"), (4, "a"), (5, "c") )).toDF("id", "category") val indexer = new StringIndexer() .setInputCol("category") .setOutputCol("categoryIndex") .fit(df) val indexed = indexer.transform(df) val encoder = new OneHotEncoder() .setInputCol("categoryIndex") .setOutputCol("categoryVec") val encoded = encoder.transform(indexed) encoded.select("id", "categoryVec").show()

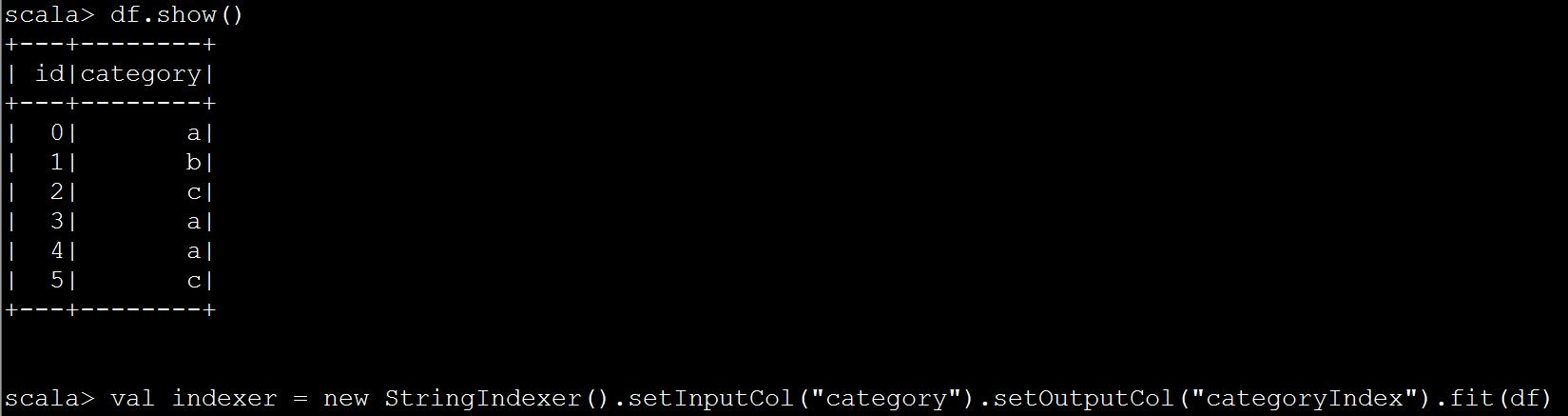
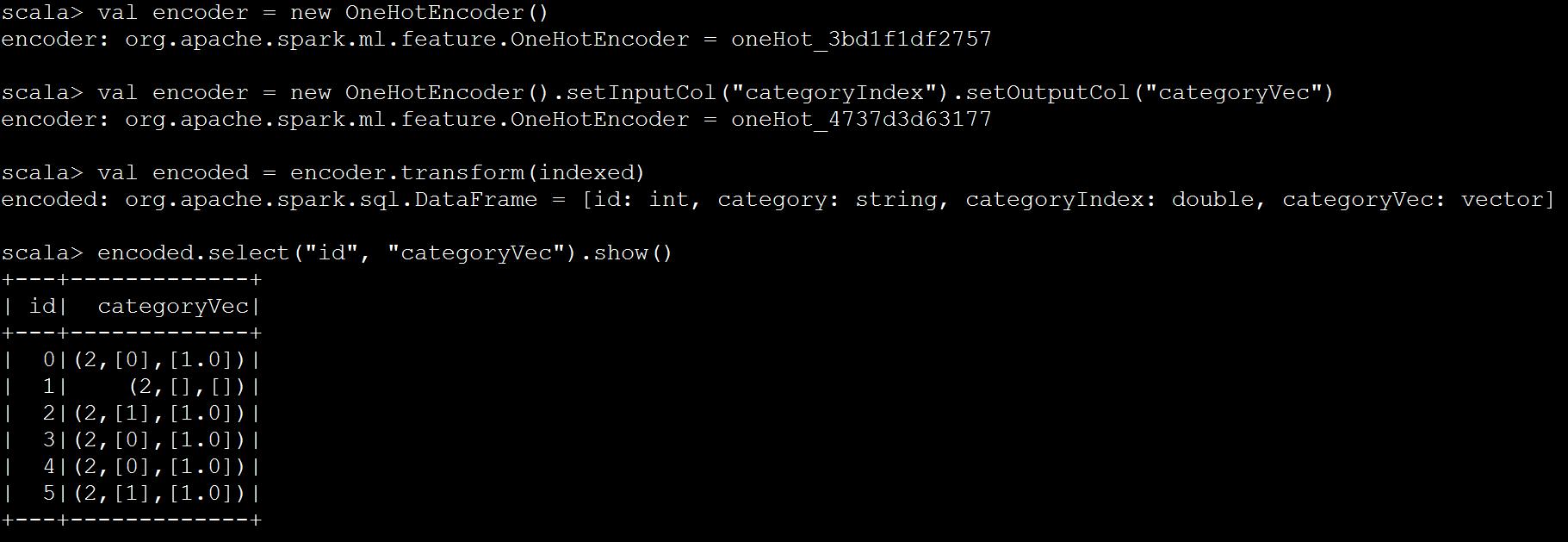
参考网址:http://blog.csdn.net/liulingyuan6/article/details/53397780
以上是关于MLlib特征变换方法的主要内容,如果未能解决你的问题,请参考以下文章
在pyspark中编写自定义NER和POS标记器,以在管道方法中用于文本输入的特征提取