决策树算法原理
Posted Little_Rookie
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了决策树算法原理相关的知识,希望对你有一定的参考价值。
转载于:http://www.cnblogs.com/pinard/p/6050306.html (楼主总结的很好,就拿来主义了,不顾以后还是多像楼主学习)
决策树算法在机器学习中算是很经典的一个算法系列了。它既可以作为分类算法,也可以作为回归算法,同时也特别适合集成学习比如随机森林。本文就对决策树算法原理做一个总结,上篇对ID3, C4.5的算法思想做了总结,下篇重点对CART算法做一个详细的介绍。决策树根据一步步地属性分类可以将整个特征空间进行划分,从而区别出不同的分类样本
1. 决策树ID3算法的信息论基础
机器学习算法其实很古老,作为一个码农经常会不停的敲if, else if, else,其实就已经在用到决策树的思想了。只是你有没有想过,有这么多条件,用哪个条件特征先做if,哪个条件特征后做if比较优呢?怎么准确的定量选择这个标准就是决策树机器学习算法的关键了。1970年代,一个叫昆兰的大牛找到了用信息论中的熵来度量决策树的决策选择过程,方法一出,它的简洁和高效就引起了轰动,昆兰把这个算法叫做ID3。下面我们就看看ID3算法是怎么选择特征的。
首先,我们需要熟悉信息论中熵的概念。熵度量了事物的不确定性,越不确定的事物,它的熵就越大。具体的,随机变量X的熵的表达式如下:
其中n代表X的n种不同的离散取值。而pipi代表了X取值为i的概率,log为以2或者e为底的对数。举个例子,比如X有2个可能的取值,而这两个取值各为1/2时X的熵最大,此时X具有最大的不确定性。值为H(X)=−(12log12+12log12)=log2H(X)=−(12log12+12log12)=log2。如果一个值概率大于1/2,另一个值概率小于1/2,则不确定性减少,对应的熵也会减少。比如一个概率1/3,一个概率2/3,则对应熵为H(X)=−(13log13+23log23)=log3−23log2<log2)H(X)=−(13log13+23log23)=log3−23log2<log2).
熟悉了一个变量X的熵,很容易推广到多个个变量的联合熵,这里给出两个变量X和Y的联合熵表达式:
有了联合熵,又可以得到条件熵的表达式H(X|Y),条件熵类似于条件概率,它度量了我们的X在知道Y以后剩下的不确定性。表达式如下:
好吧,绕了一大圈,终于可以重新回到ID3算法了。我们刚才提到H(X)度量了X的不确定性,条件熵H(X|Y)度量了我们在知道Y以后X剩下的不确定性,那么H(X)-H(X|Y)呢?从上面的描述大家可以看出,它度量了X在知道Y以后不确定性减少程度,这个度量我们在信息论中称为互信息,,记为I(X,Y)。在决策树ID3算法中叫做信息增益。ID3算法就是用信息增益来判断当前节点应该用什么特征来构建决策树。信息增益大,则越适合用来分类。
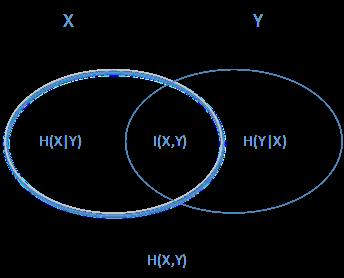
上面一堆概念,大家估计比较晕,用下面这个图很容易明白他们的关系。左边的椭圆代表H(X),右边的椭圆代表H(Y),中间重合的部分就是我们的互信息或者信息增益I(X,Y), 左边的椭圆去掉重合部分就是H(X|Y),右边的椭圆去掉重合部分就是H(Y|X)。两个椭圆的并就是H(X,Y)。
信息熵(Entropy)、信息增益(Information Gain)概念解释
1、 信息熵:H(X) 描述X携带的信息量。 信息量越大(值变化越多),则越不确定,越不容易被预测。
对于抛硬币问题,每次有2种情况,信息熵为1
对于投骰子问题,每次有6中情况,信息熵为1.75
下面为公式:

其中log2(p)可以理解为p这个需要用几个bit位表示。如p(x1)=1/2, p(x2)=1/4, p(x3)=1/8, p(x4)=1/8,
可以用x1: 1, x2: 10, x3: 110, x4: 111表示,因为为了让平均的bit位最少,概率越大的bit为设的越短。而-log2(p)正好对应bit位数。
那么H(X)可以理解为比特位的期望值。
信息熵特点:(以概率和为1为前提哈)
a) 不同类别的概率分布越均匀,信息熵越大;
b) 类别个数越多,信息熵越大;
c) 信息熵越大,越不容易被预测;(变化个数多,变化之间区分小,则越不容易被预测)(对于确定性问题,信息熵为0;p=1; E=p*logp=0)
2、 信息增益IG(Y|X): 衡量一个属性(x)区分样本(y)的能力。 当新增一个属性(x)时,信息熵H(Y)的变化大小即为信息增益。 IG(Y|X)越大表示x越重要。
条件熵:H(Y|X),当X条件下Y的信息熵
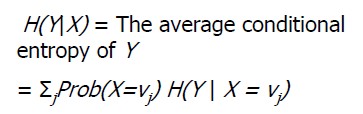
信息增益: IG(Y|X)=H(Y)-H(Y|X)
熵(entropy):在信息论和概率统计中,熵是表示随机变量不确定性的度量
条件熵(conditional entropy):表示在一直随机变量X的条件下随机变量Y的不确定性度量。
信息增益(information gain):信息增益表示得知特征X的信息而使得类Y的信息的不确定性减少的程度。
信息增益比(information gain ratio):其信息增益g(D, A)与训练数据集D关于特征A的值的熵HA(D)之比
基尼指数(gini index):基尼指数Gini(D)表示集合D的不确定性,基尼指数越大,样本集合的不确定性也就越大,这一点与熵相似。
2. 决策树ID3算法的思路
上面提到ID3算法就是用信息增益大小来判断当前节点应该用什么特征来构建决策树,用计算出的信息增益最大的特征来建立决策树的当前节点。这里我们举一个信息增益计算的具体的例子。比如我们有15个样本D,输出为0或者1。其中有9个输出为0, 6个输出为1。 样本中有个特征A,取值为A1,A2和A3。在取值为A1的样本的输出中,有3个输出为1, 2个输出为0,取值为A2的样本输出中,2个输出为1,3个输出为0, 在取值为A3的样本中,4个输出为1,1个输出为0.
样本D的熵为: H(D)=−(915log2915+615log2615)=0.971H(D)=−(915log2915+615log2615)=0.971
样本D在特征下的条件熵为: H(D|A)=515H(D1)+515H(D2)+515H(D3)H(D|A)=515H(D1)+515H(D2)+515H(D3)
=−515(35log235+25log225)−515(25log225+35log235)−515(45log245+15log215)=0.888=−515(35log235+25log225)−515(25log225+35log235)−515(45log245+15log215)=0.888
对应的信息增益为 I(D,A)=H(D)−H(D|A)=0.083I(D,A)=H(D)−H(D|A)=0.083
下面我们看看具体算法过程大概是怎么样的。
输入的是m个样本,样本输出集合为D,每个样本有n个离散特征,特征集合即为A,输出为决策树T。
算法的过程为:
1)初始化信息增益的阈值ϵϵ
2)判断样本是否为同一类输出DiDi,如果是则返回单节点树T。标记类别为DiDi
3) 判断特征是否为空,如果是则返回单节点树T,标记类别为样本中输出类别D实例数最多的类别。
4)计算A中的各个特征(一共n个)对输出D的信息增益,选择信息增益最大的特征AgAg
5) 如果AgAg的信息增益小于阈值ϵϵ,则返回单节点树T,标记类别为样本中输出类别D实例数最多的类别。
6)否则,按特征AgAg的不同取值AgiAgi将对应的样本输出D分成不同的类别DiDi。每个类别产生一个子节点。对应特征值为AgiAgi。返回增加了节点的数T。
7)对于所有的子节点,令D=Di,A=A−{Ag}D=Di,A=A−{Ag}递归调用2-6步,得到子树TiTi并返回。
3. 决策树ID3算法的不足
ID3算法虽然提出了新思路,但是还是有很多值得改进的地方。
a)ID3没有考虑连续特征,比如长度,密度都是连续值,无法在ID3运用。这大大限制了ID3的用途。
b)ID3采用信息增益大的特征优先建立决策树的节点。很快就被人发现,在相同条件下,取值比较多的特征比取值少的特征信息增益大。比如一个变量有2个值,各为1/2,另一个变量为3个值,各为1/3,其实他们都是完全不确定的变量,但是取3个值的比取2个值的信息增益大。如果校正这个问题呢?
c) ID3算法对于缺失值的情况没有做考虑
d) 没有考虑过拟合的问题
ID3 算法的作者昆兰基于上述不足,对ID3算法做了改进,这就是C4.5算法,也许你会问,为什么不叫ID4,ID5之类的名字呢?那是因为决策树太火爆,他的ID3一出来,别人二次创新,很快 就占了ID4, ID5,所以他另辟蹊径,取名C4.0算法,后来的进化版为C4.5算法。下面我们就来聊下C4.5算法
4. 决策树C4.5算法的改进
上一节我们讲到ID3算法有四个主要的不足,一是不能处理连续特征,第二个就是用信息增益作为标准容易偏向于取值较多的特征,最后两个是缺失值处理的问和过拟合问题。昆兰在C4.5算法中改进了上述4个问题。
对于第一个问题,不能处理连续特征, C4.5的思路是将连续的特征离散化。比如m个样本的连续特征A有m个,从小到大排列为a1,a2,...,ama1,a2,...,am,则C4.5取相邻两样本值的中位数,一共取得m-1个划分点,其中第i个划分点Ti表示Ti表示为:Ti=ai+ai+12Ti=ai+ai+12。对于这m-1个点,分别计算以该点作为二元分类点时的信息增益。选择信息增益最大的点作为该连续特征的二元离散分类点。比如取到的增益最大的点为atat,则小于atat的值为类别1,大于atat的值为类别2,这样我们就做到了连续特征的离散化。要注意的是,与离散属性不同的是,如果当前节点为连续属性,则该属性后面还可以参与子节点的产生选择过程。
对于第二个问题,信息增益作为标准容易偏向于取值较多的特征的问题。我们引入一个信息增益比的变量IR(X,Y)IR(X,Y),它是信息增益和特征熵的比值。表达式如下:
其中D为样本特征输出的集合,A为样本特征,对于特征熵HA以上是关于决策树算法原理的主要内容,如果未能解决你的问题,请参考以下文章