es 无日志,logstash 报错
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了es 无日志,logstash 报错相关的知识,希望对你有一定的参考价值。
参考技术A 通过kibana看不到日志看管道监控,发现日志写入速率为0
然后看logstash日志,发现报错
通过百度,查到的原因是:
是因为一次请求中批量插入的数据条数巨多,以及短时间内的请求次数巨多引起ES节点服务器内存超过限制,ES主动给索引上锁。
解决方案是:
Linux企业运维——ELK日志分析平台(中)ES节点优化logstash数据采集过滤插件
Linux企业运维——ELK日志分析平台(中)ES节点优化、logstash数据采集、过滤插件
文章目录
一、ES节点优化
1.1、ES节点角色
- Master: 主要负责集群中索引的创建、删除以及数据的Rebalance等操作。Master不负责数据的索引和检索,所以负载较轻。当Master节点失联或者挂掉的时候,ES集群会自动从其他Master节点选举出一个Leader。
- Data Node: 主要负责集群中数据的索引和检索,一般压力比较大。
- Coordinating Node: 原来的Clientnode的,主要功能是来分发请求和合并结果的。所有节点默认就是Coordinatingnode,且不能关闭该属性。
- Ingest Node: 专门对索引的文档做预处理
1.2、节点角色属性
在生产环境下,如果不修改elasticsearch节点的角色信息,在高数据量,高并发的场景下集群容易出现脑裂等问题。
默认情况下,elasticsearch集群中每个节点都有成为主节点的资格,也都存储数据,还可以提供查询服务。
节点角色是由以下属性控制:
node.master: false|true
node.data: true|false
node.ingest: true|false
search.remote.connect: true|false
默认情况下这些属性的值都是true。
| 属性名称 | 属性作用 |
|---|---|
| node.master | 这个属性表示节点是否具有成为主节点的资格 |
| node.data | 这个属性表示节点是否存储数据 |
| node.ingest | 是否对文档进行预处理 |
| search.remote.connect | 是否禁用跨集群查询 |
注意:
node.master属性的值为true,并不意味着这个节点就是主节点。因为真正的主节点,是由多个具有主节点资格的节点进行选举产生的。
1.3、属性组合方式
组合一:
默认
node.master: true
node.data: true
node.ingest: true
search.remote.connect: true
这种组合表示这个节点即有成为主节点的资格,又存储数据。
如果某个节点被选举成为了真正的主节点,那么他还要存储数据,这样对于这个节点的压力就比较大了。
测试环境下这样做没问题,但实际工作中不建议这样设置。
组合二:
Data Node
node.master: false
node.data: true
node.ingest: false
search.remote.connect: false
这种组合表示这个节点没有成为主节点的资格,也就不参与选举,只会存储数据。
这个节点称为data(数据)节点。在集群中需要单独设置几个这样的节点负责存储数据。后期提供存储和查询服务。
组合三:
Master Node
node.master: true
node.data: false
node.ingest: false
search.remote.connect: false
这种组合表示这个节点不会存储数据,有成为主节点的资格,可以参与选举,有可能成为真正的主节点。
这个节点我们称为master节点。
组合四:
Coordinating Node
node.master: false
node.data: false
node.ingest: false
search.remote.connect: false
这种组合表示这个节点即不会成为主节点,也不会存储数据,
这个节点的意义是作为一个协调节点,主要是针对海量请求的时候可以进行负载均衡。
组合五:
Ingest Node
node.master: false
node.data: false
node.ingest: true
search.remote.connect: false
这种组合表示这个节点即不会成为主节点,也不会存储数据,
这个节点的意义是ingest节点,对索引的文档做预处理。
1.4、节点职责划分
生产集群中可以对这些节点的职责进行划分:
- 建议集群中设置3台以上的节点作为master节点,这些节点只负责成为主节点,维护整个集群的状态。
- 再根据数据量设置一批data节点,这些节点只负责存储数据,后期提供建立索引和查询索引的服务,这样的话如果用户请求比较频繁,这些节点的压力也会比较大。
- 所以在集群中建议再设置一批协调节点,这些节点只负责处理用户请求,实现请求转发,负载均衡等功能。
ES通过shared分片将数据分散到不同的节点上,分片从角色上分为主分片primary shared和辅助分片replica shared,数据会先写入主分片,然后同步到辅助分片中,主分片和辅助分片不能分配到同一个节点上,通过“分”的思想,突破单机在存储空间和处理性能上的限制,这是分布式系统的核心目的。分片可以在客户端进行设置,当主分片数据丢失或被删除时,辅助分片会升级为主分片。分片在集群节点上会自动迁移,尤其是在节点重启时。
节点需求
- master节点:普通服务器即可(CPU、内存 消耗一般)
- data节点:主要消耗磁盘、内存。 path.data: data1,data2,data3 这样的配置可能会导致数据写入不均匀,建议只指定一个数据路径,磁盘可以使用raid0阵列,而不需要成本高的ssd。
- Coordinating节点:对cpu、memory要求较高。
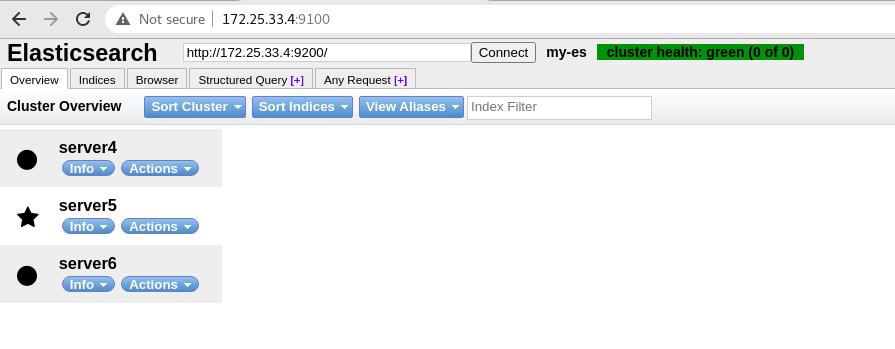
server4进入到elasticsearch-head-master目录下,使用cnpm run start &运行head插件,运行在本地9100端口

使用浏览器访问server4的9100端口可以看到显示server5为master节点,当前只有三个节点,保留当前的master节点,集群中至少留一个master,做预处理

选择server4节点禁用数据节点参数重启服务,如果该节点已有部分共享数据重启会失败(图形界面的绿色方框-副本/分片),可以查看日志清理该节点数据,注意清理时es服务要停掉,此时该节点数据/副本会迁移到其他主机上
server4进入/etc/elasticsearch/目录下,编辑elasticsearch.yml配置文件,将node.data属性置为false
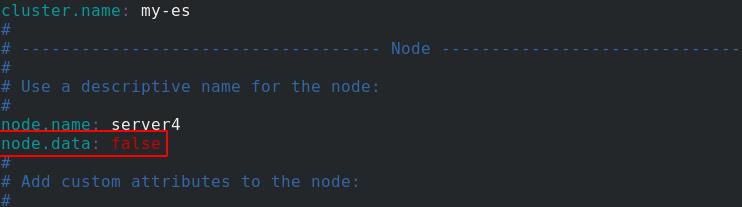
重新启动es服务

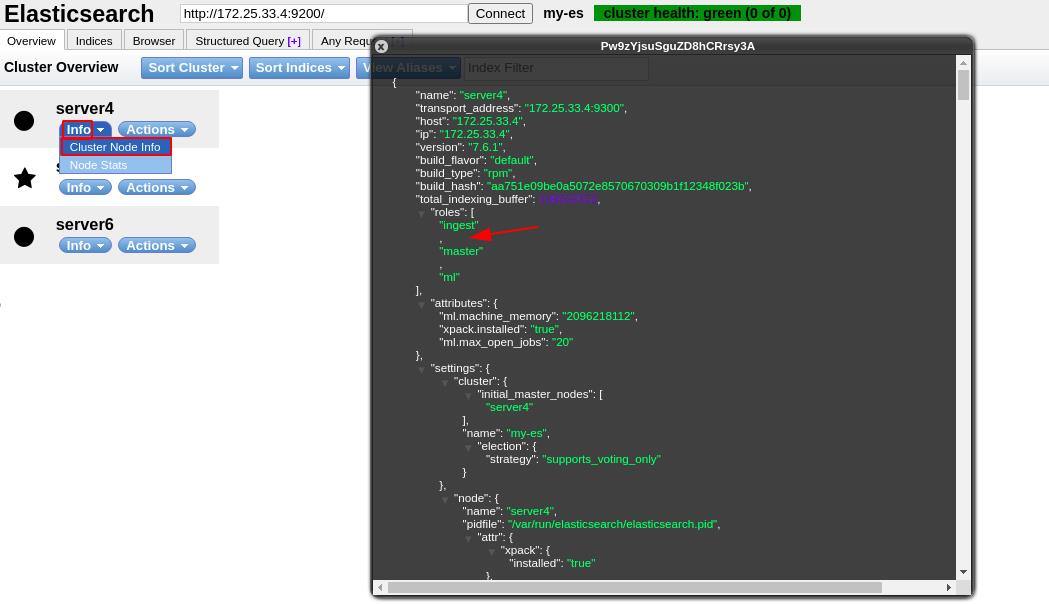
在网页管理界面查看server4的集群节点信息,此时server4中role角色有 Ingest(预处理),Master(整个集群的master),ml(机器学习),data已经被关闭了
二、logstash数据采集
2.1、logstash简介
Logstash是一个开源的服务器端数据处理管道。
logstash拥有200多个插件,能够同时从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的 “存储库” 中。(大多都是 Elasticsearch。)
Logstash管道有两个必需的元素,输入和输出,以及一个可选元素过滤器。

输入:
采集各种样式、大小和来源的数据
Logstash 支持各种输入选择 ,同时从众多常用来源捕捉事件。
能够以连续的流式传输方式,轻松地从您的日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据。

过滤器:
实时解析和转换数据
数据从源传输到存储库的过程中,Logstash 过滤器能够解析各个事件,识别已命名的字段以构建结构,并将它们转换成通用格式,以便更轻松、更快速地分析和实现商业价值。
• 利用 Grok 从非结构化数据中派生出结构
• 从 IP 地址破译出地理坐标
• 将 PII 数据匿名化,完全排除敏感字段
• 简化整体处理,不受数据源、格式或架构的影响
输出:
选择您的存储库,导出您的数据
尽管 Elasticsearch 是我们的首选输出方向,能够为我们的搜索和分析带来无限可能,但它并非唯一选择。
Logstash 提供众多输出选择,您可以将数据发送到您要指定的地方,并且能够灵活地解锁众多下游用例。

2.2、logstash安装与配置
真实主机新开一台虚拟机server7
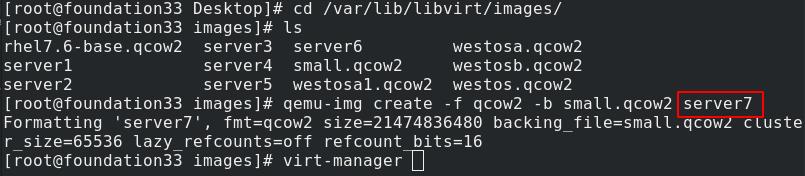
为server7添加域名解析
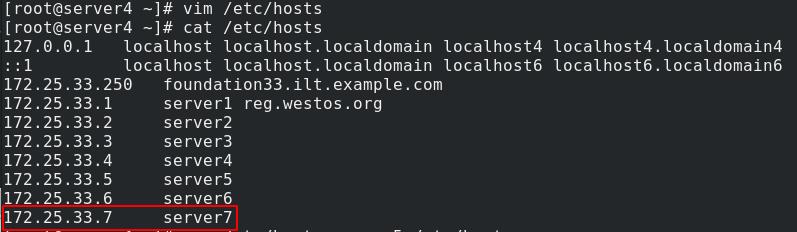
真实主机将logstash和jdk安装包发送给server7

server7安装jdk和logstash

先用命令行方式测试环境,方便调用可以作一个软连接
调用stdin(终端录入)和stdout(输出到终端屏幕)插件进行标准输入输出

输入输出测试
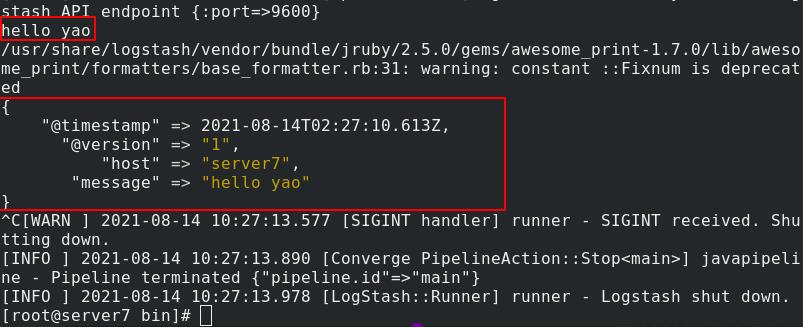
标准输出到文件(官方文档):可以在指定目录下编写.conf文件(path指定输出文件路径,codec定义文件格式),执行logstash命令-f指定读取文件

[root@server6 conf.d] cat test.conf
input
stdin
output
file
path => "/tmp/testfile"
codec => line format => "custom format: %message"
测试输出,可以看到输出到指定的文件中

输出到es:通过elasticsearch模块向es输出数据,指定es集群节点(可以写多个),要在es中创建索引index,使用默认索引logstash,但是写入es看不到回显,所以在output中加入stdout
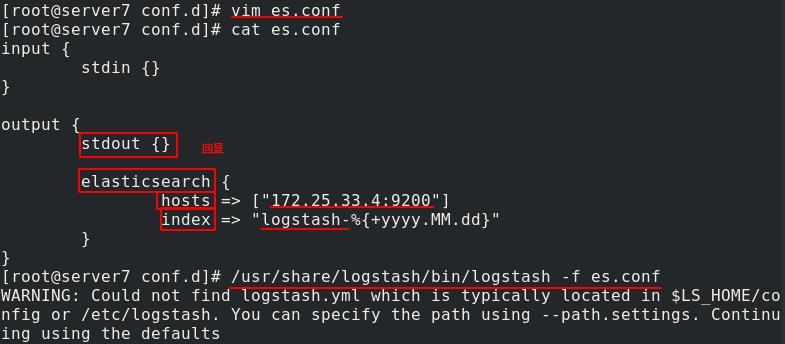
[root@server6 conf.d] cat es.conf
input
stdin
output
stdout
elasticsearch
hosts => ["172.25.0.3:9200"]
index => "logstash-%+yyyy.MM.dd"
测试输出消息到es

es管理界面点击Browser选项可以看到发来的消息

2.3、logstash采集系统日志
logstash在运行时是以logstash身份,要保证该用户对日志文件有权限

修改配置文件,将输入信息设置为日志文件,指定文件读取位置:从文件开头
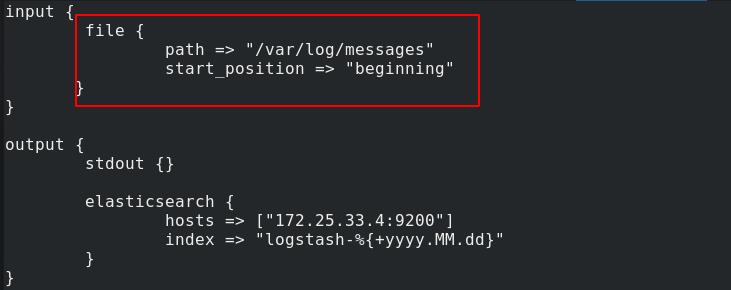
开始输出
在es界面中可以查看到输出的日志信息

将日志文件删除

再次执行es.conf,会发现没有数据输出了


真实主机ssh连接到server7,写入新的日志

可以看到logstash将日志进行输出

在es中可以查看到刚才的日志
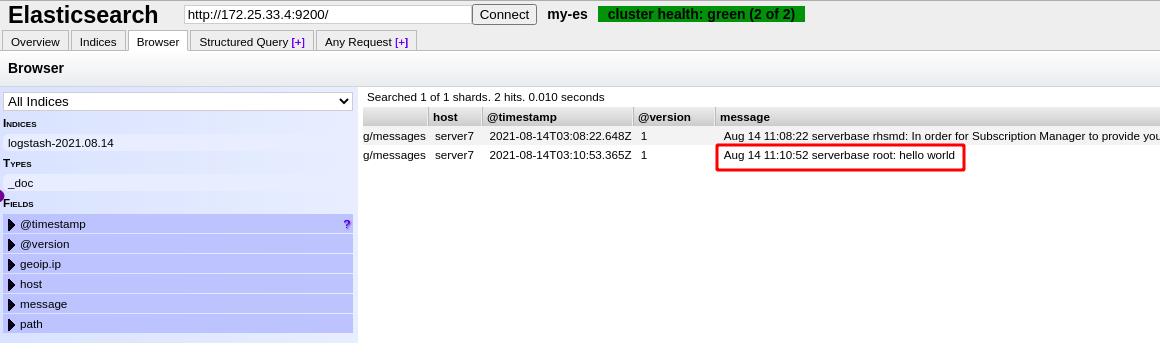
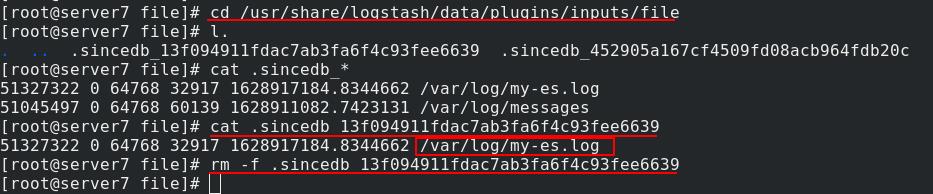
在图形界面删除es中这一文件后,再次执行,不会再重新写文件,文件只会写入变更(避免数据冗余),这是因为在指定目录下的.sincedb隐藏文件会实时变更记录文件的字节偏移量,删除这一隐藏文件,文件会重新从头写入

es界面中再次将所有日志文件删除

现在再执行es.conf

可以看到日志文件从头开始重新进行输出了

在es的管理界面可以查看到所有日志文件
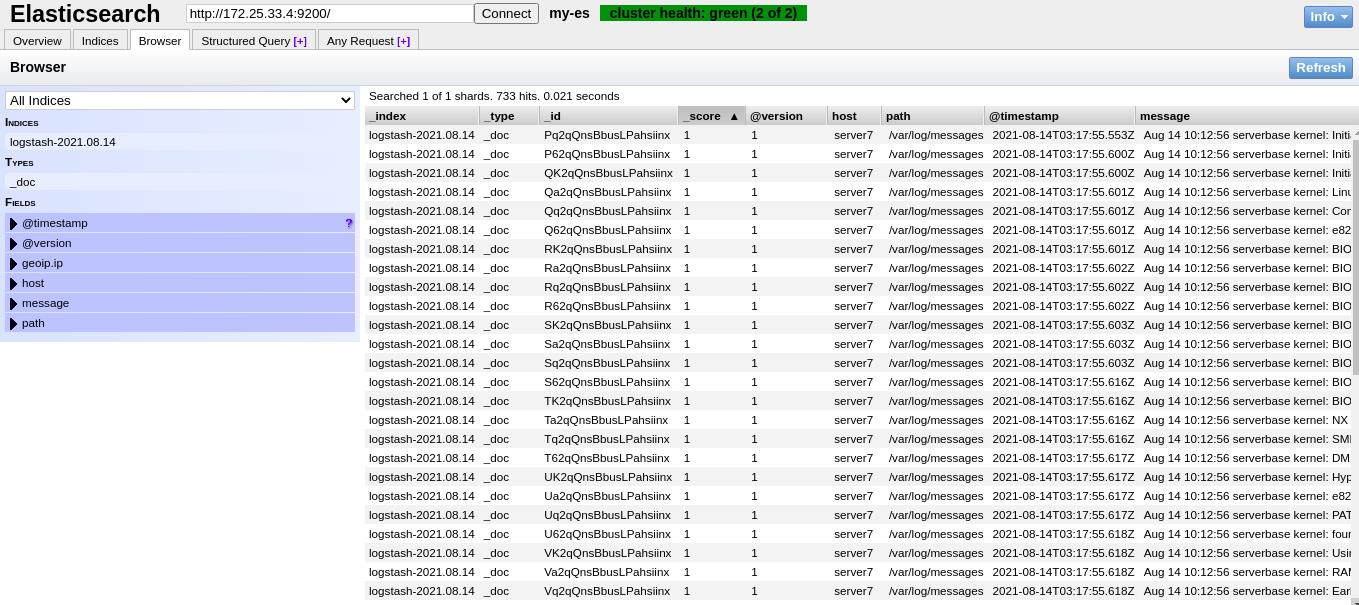
2.4、logstash伪装成日志服务器,直接接收远程日志
server7编辑es.conf文件,514是日志收集端口,server7监听514端口伪装成日志服务器
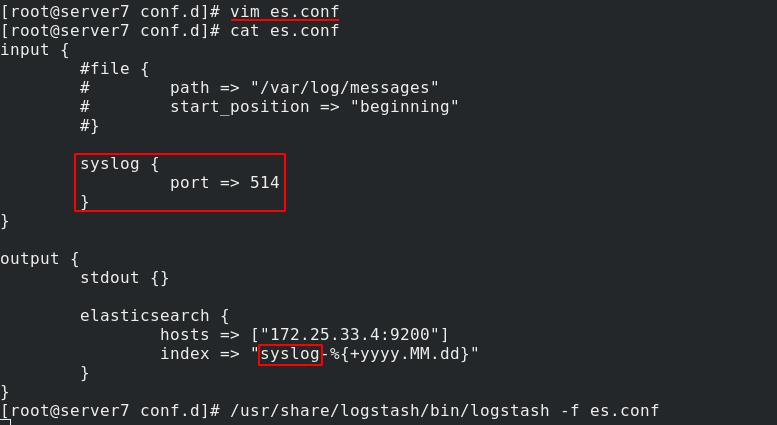
查看514端口状态为开放

server4编辑/etc/rsyslog.conf配置文件,打开514端口

所有日志都发送给server7的514端口

重新启动rsyslog服务

server7这里已经可以看到日志输入

server6编辑/etc/rsyslog.conf配置文件,打开514端口

所有日志都发送给server7的514端口

重新启动rsyslog服务

server7查看514端口状态可以看到已经与server4和server6的514端口建立连接

server7这里已经可以看到接收到server6的日志信息

在es管理界面中可以查看到

三、过滤插件
3.1、多行过滤插件
多行录入,当遇到预定义的关键字时,会向上合并输出(错误日志一般都是多行显示一条事件记录,所以需要用到多行输出)
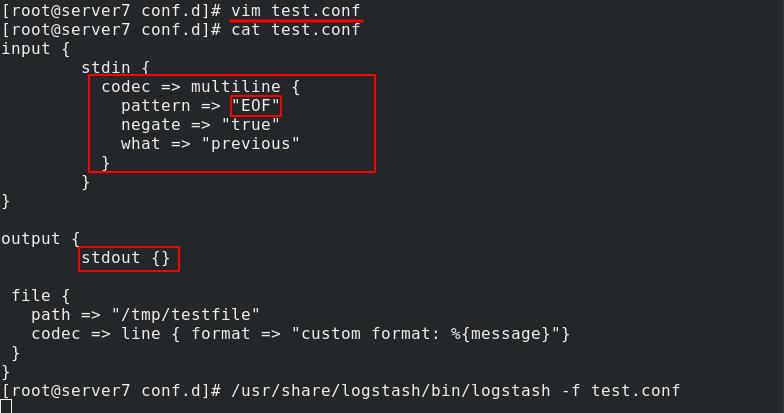
server7编辑test.conf,结束符为EOF,遇到定义的EOF时向上合并进行输出
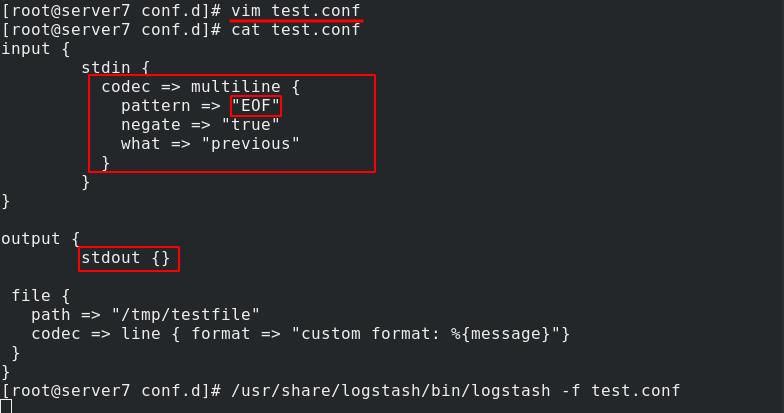
测试多行输出,可以看到在EOF处截止

正确的日志都以时间开头,而错误的日志会分为很多行,输出错误的日志时我们也需要将其正常处理
server4将my-es.log发送给server7

可以看到错误日志信息,分了很多行

server7编辑test.conf文件,以/var/log/my-es.log作为输入,从头开始输入,输出到es,先将多行输入模块注释起来,看看效果
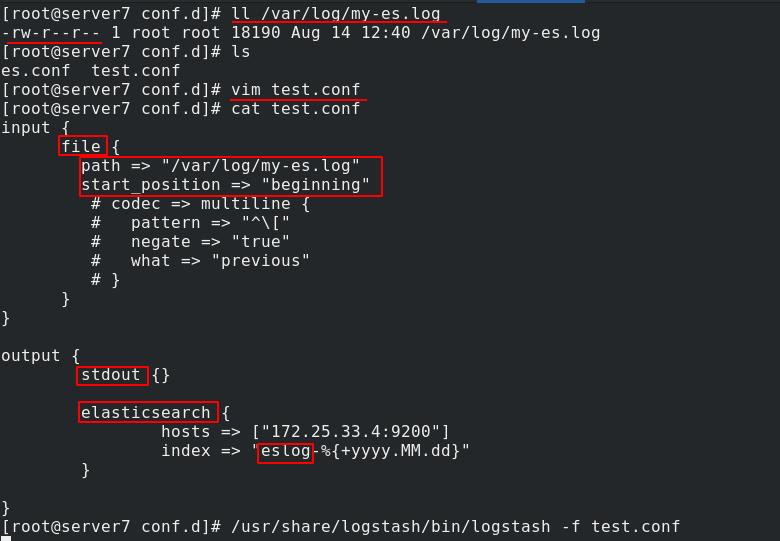
[root@server6 conf.d] cat test.conf
input
file
path => "/var/log/my-es.log"
start_position => "beginning"
# codec => multiline
# pattern => "EOF"
# negate => "true"
# what => "previous"
#
output
stdout
elasticsearch
hosts => ["172.25.0.3:9200"]
index => "eslog-%+yyyy.MM.dd"
可以看到输出了很多文件
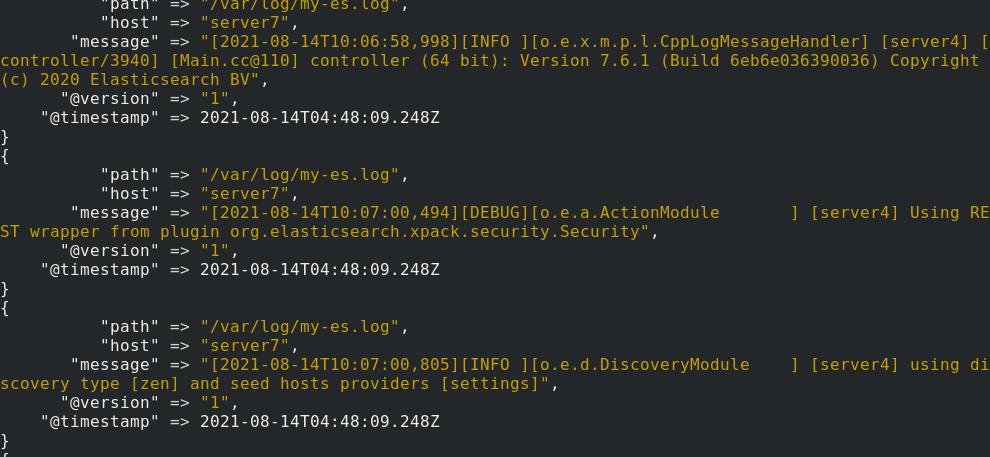
在es界面中查看可以发现错误日志中的每一行都被单独分成了一个文件


删除eslog日志

删除.sincedb文件以便我们重新输出
再次编辑test.conf文件,加入多行输出部分
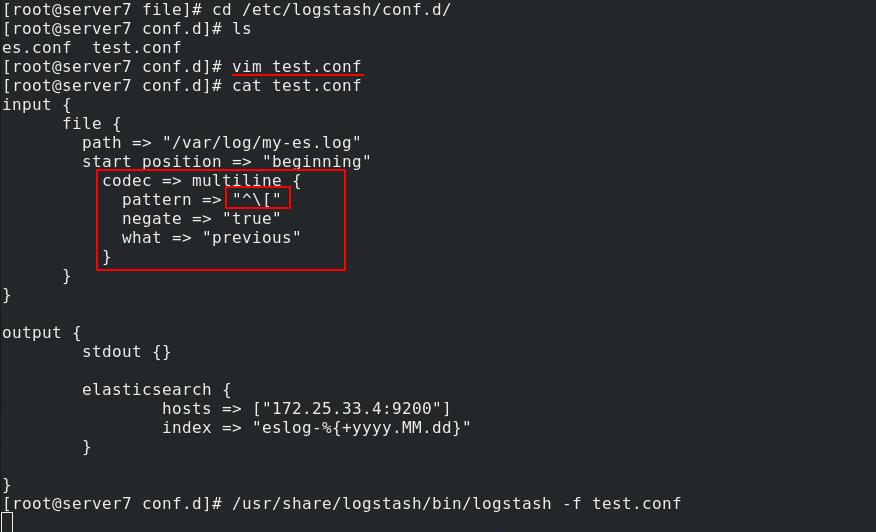
[root@server6 conf.d]# cat test.conf
input
file
path => "/var/log/my-es.log"
start_position => "beginning"
codec => multiline
pattern => "^\\[" (预定义关键字为以[开头的行,\\转译[)
negate => "true"
what => "previous"
output
stdout
elasticsearch
hosts => ["172.25.0.3:9200"]
index => "eslog-%+yyyy.MM.dd"
查看es管理界面,现在可以看到只有两个文件

错误日志被正确的处理到一个文件当中了

3.2、grok过滤插件
grok过滤插件:可以对输入信息进行切片,便于最后分析
server7在conf.d目录下创建并编辑grok.conf文件,将输入信息分成5块部分

[root@server6 conf.d] cat grok.conf
input
stdin
filter
grok
match => "message" => "%IP:client %WORD:method %URIPATHPARAM:request %NUMBER:bytes %NUMBER:duration"
output
stdout
测试输入,可以看到输入信息按配置文件中设定的被分成了5个部分

server7安装httpd

给index页面中添加一行内容

真实主机测试访问server7可以正常访问到web服务
查看/var/log/httpd/access_log内apache的日志格式内容,
在/usr/share/logstash/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.1.2/patterns目录下选择查看apache的日志输出格式
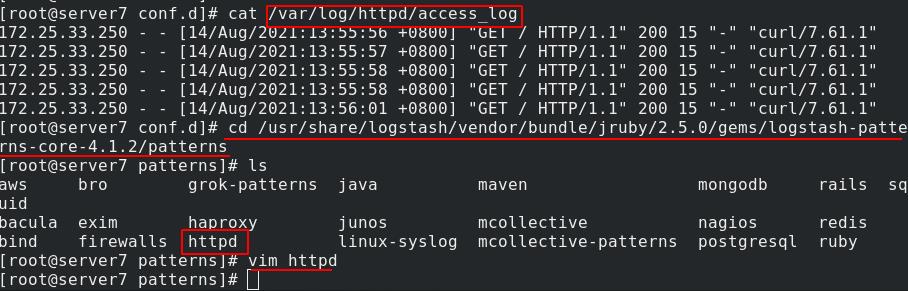
按照文件中的格式来规定grok切片

将apache的日志作为输入,因为操作时是以logstash用户身份,所以设置文件权限

server7编辑grok.conf文件,按照HTTPD_COMBINEDLOG方式切片

可以按到按照规定好的方式进行了切片
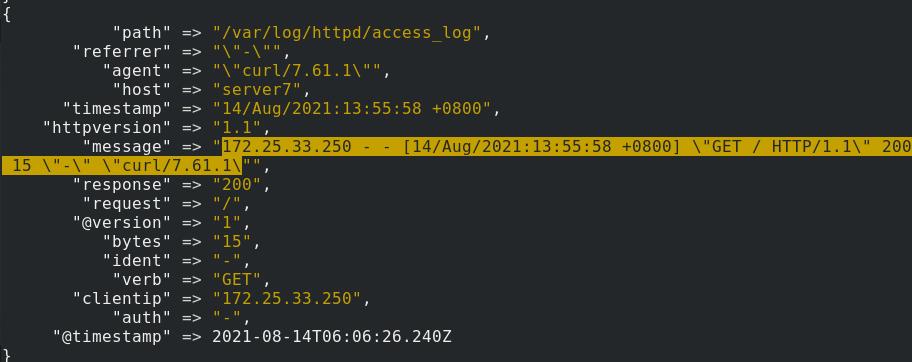
es界面查看到成功进行了切片
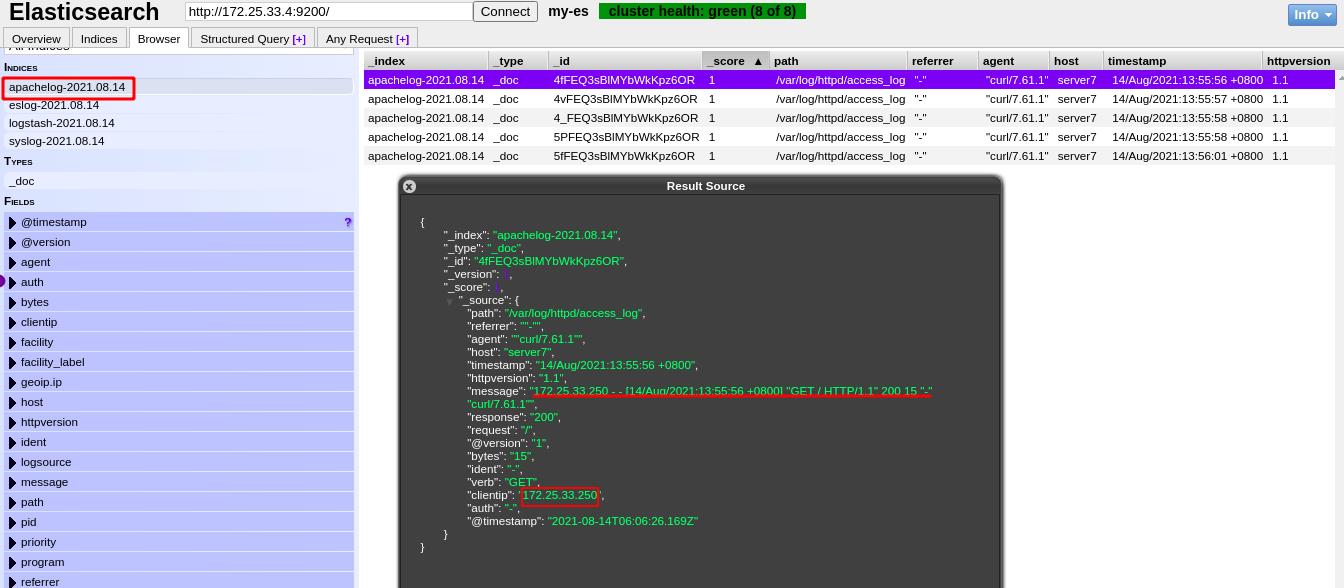
真实主机对server7的web页面进行压力测试

es页面中可以看到出现了很多日志信息,来自于真实主机的访问

以上是关于es 无日志,logstash 报错的主要内容,如果未能解决你的问题,请参考以下文章