分布式系统
Posted 凌寒花开
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式系统相关的知识,希望对你有一定的参考价值。
Distributed systems: for fun and profit (http://book.mixu.net/distsys/index.html)
链接:https://www.zhihu.com/question/23645117/answer/124708083
这篇文章主要试图回答以下两个个问题:
1. 近些年分布式系统领域都在做些什么。
2. 为什么现在投入分布式系统的学习和研究是值得的。
我会尽可能多的去介绍更 “实用” 的分布式系统知识。
什么是实用?例如:
Paxos 是分布式系统里一个重要而且实用的技术。
Consistent Hash 也是分布式系统里一个重要而且实用的技术。
MapReduce, Spark 等等都是很实用的系统。
什么不实用? 例如:
Paxos 算法的数学证明。(注意此处“不实用” 和 “不重要”的区别)
当然,分布式系统实在是一个太宽泛的话题,本人才疏学浅,回答也仅仅可能侧重于我所关心的领域和方向,很多地方都不能面面俱到。所以在此只能抛砖引玉, 蜻蜓点水,欢迎大家提出宝贵意见,我也会及时对文章进行修改和补充。
分布式系统近些年都在做些什么?
分布式系统是一个古老而宽泛的话题,而近几年因为 “大数据” 概念的兴起,又焕发出了新的青春与活力。除此之外,分布式系统也是一门理论模型与工程技法并重的学科内容。相比于机器学习这样的研究方向,学习分布式系统的同学往往会感觉:“入门容易,深入难”。的确,学习分布式系统几乎不需要太多数学知识(相比于机器学习),这也是为什么会造成 “入门容易” 的错觉。然而一旦深入下去,往往需要我们去体会 system 研究的 “简洁” 与 “美”,正如楼上 李沐 的回答中说的那样,系统工作是 “艺术” 而不是 “科学” ,这一点我觉得是系统研究工作最难,同时也是最精华的地方。总之把握一点原则:好的系统研究工作,尤其是分布式系统研究,一定是尽可能地用最简单、最直观的方法去解决实际的问题(看看 MapReduce 就知道了),因为简单就意味着实用。
总的来说,分布式系统要做的任务就是把多台机器有机的组合、连接起来,让其协同完成一件任务,可以是计算任务,也可以是存储任务。如果一定要给近些年的分布式系统研究做一个分类的话,我个人认为大概可以包括三大部分:
1. 分布式存储系统
2. 分布式计算系统
3. 分布式管理系统
近十年来在这三个方向上,毫无疑问, Google 都是开创者,甚至很多业内人士都说,这十年是外界追随谷歌技术的十年。我们之前说到,分布式系统的研究是一门由实际问题驱动的研究,而 google 则是最先需要面对这些实际问题的公司。下面我们分别看看这三个方面工业界以及学术界这几年都在做些什么。
分布式存储系统:
分布式存储系统是一个非常古老的话题,同时也是分布式系统里最难,最复杂,涉及面最广的问题。 往细了分,分布式存储系统大概可以分为四个子方向:
1. 结构化存储
2. 非结构化存储
3. 半结构化存储
4. In-memory 存储
除了这四个子方向之外,分布式存储系统还有一系列的理论、算法、技术作为支撑:例如 Paxos, CAP, ConsistentHash, Timing (时钟), 2PC, 3PC 等等,这些内容我们会在后面提到。现在,我们先来看看上述四个子方向大致都在干些什么。
结构化存储(structured storage systems)的历史非常古老,典型的场景就是事务处理系统或者关系型数据库(RDBMS)。传统的结构化存储都是从单机做起的,比如大家耳熟能详的 mysql。有句话说:MySQL的成长史就是互联网的成长史。这一点也不为过。除了 MySQL 之外,PostgreSQL 也是近几年来势头非常强劲的一个 RDBMS. 我们发现,传统的结构化存储系统强调的是:(1)结构化的数据(例如关系表)。(2)强一致性 (例如,银行系统,电商系统等场景)(3)随机访问(索引,增删查改,SQL 语言)。然而,正是由于这些性质和限制,结构化存储系统的可扩展性通常都不是很好,这在一定程度上限制了结构化存储在大数据环境下的表现。随着摩尔定律面临的瓶颈,传统的单机关系型数据库系统面临着巨大的挑战。不过真的没办法了吗?在此我们先埋下一个伏笔:)
非结构化存储 (no-structed storage systems). 和结构化存储不同的是,非结构化存储强调的是高可扩展性,典型的系统就是分布式文件系统。分布式文件系统也是一个古老的研究话题,比如 70 年代的 Xerox Alto, 80 年代的 NFS, AFS, 90 年代 xFS 等等。然而,这些早期的分布式文件系统只是起到了网络磁盘的作用, 其最大的问题就是不支持 容错 (fault tolerance)和 错误恢复 (fault recovery)。而 Google 在 2003 年 SOSP 上推出的 GFS (google file system) 则是做出了里程碑的一步,其开源实现对应为 HDFS. GFS 的主要思想包括:
(1)用 master 来管理 metadata。
(2)文件使用 64MB 的 chunks 来存储,并且在不同的 server 上保存多个副本。
(3)自动容错,自动错误恢复。
Google 设计 gfs 最初的目的是为了存储海量的日志文件以及网页等文本信息,并且对其进行批量处理(例如配合 mapreduce 为文档建立倒排索引,计算网页 PageRank 等)。和结构化存储系统相比,虽然分布式文件系统的可扩展性,吞吐率都非常好,但是几乎无法支持随机访问(random access)操作,通常只能进行文件进行追加(append)操作。而这样的限制使得非结构化存储系统很难面对那些低延时,实时性较强的应用。
半结构化存储 (semi-structure storage systems)的提出便是为了解决结非构化存储系统随机访问性能差的问题。我们通常会听到一些流行的名词,比如 NoSQL, Key-Value Store, 甚至包括对象存储,例如 protobuf,thrift 等等。这些都属于半结构化存储研究的领域,其中以 NoSQL 近几年的发展势头尤为强劲。NoSQL 系统既有分布式文件系统所具有的可扩展性,又有结构化存储系统的随机访问能力 (例如随机update, read 操作),系统在设计时通常选择简单键值(K-V)进行存储,抛弃了传统 RDBMS 里复杂 SQL 查询以及 ACID 事务。这样做可以换取系统最大的限度的可扩展性和灵活性。在 NoSQL 里比较有名系统包括:Google 的 Bigtable, Amazon 的 Dynamo, 以及开源界大名鼎鼎的 HBase,Cassandra 等. 通常这些 NoSQL 系统底层都是基于比较成熟的存储引擎,比如 Bigtable 就是基于 LevelDB ( jeff dean 写的,非常好的 C++ 源码教程) ,底层数据结构采用 LSM-Tree. 除了 LSM-Tree 之外 B-Tree (B+Tree)也是很成熟的存储引擎数据结构。
In-memory 存储。随着业务的并发越来越高,存储系统对低延迟的要求也越来越高。 同时由于摩尔定律以及内存的价格不断下降,基于内存的存储系统也开始普及。 In-memory 存储顾名思义就是将数据存储在内存中, 从而获得读写的高性能。比较有名的系统包括 memcahed ,以及 Redis。 这些基于 K-V 键值系统的主要目的是为基于磁盘的存储系统做 cache。还有一些偏向于内存计算的系统,比如可以追溯到普林斯顿 Kai Lee 教授早期的研究工作 distributed shared memory ( DSM ),斯坦福的 RamCloud, 以及最近比较火的基于 lineage 技术的 tachyon (Alluxio) 项目(Spark生态系统子项目)等等。
NewSQL. 我们在介绍结构化存储时说到,单机 RDBMS 系统在可扩展性上面临着巨大的挑战,然而 NoSQL 不能很好的支持关系模型。那是不是有一种系统能兼备 RDBMS 的特性(例如:完整的 SQL 支持,ACID 事务支持),又能像 NoSQL 系统那样具有强大的可扩展能力呢? 2012 年 Google 在 OSDI 上发表的 Spanner,以及 2013 年在 SIGMOD 发表的 F1, 让业界第一次看到了关系模型和 NoSQL 在超大规模数据中心上融合的可能性。不过由于这些系统都太过于黑科技了,没有大公司支持应该是做不出来的。比如 Spanner 里用了原子钟这样的黑科技来解决时钟同步问题,打破光速传输的限制。在这里只能对 google 表示膜拜。
我们在之前提到,分布式存储系统有一系列的理论、算法、技术作为支撑:例如 Paxos, CAP, Consistent Hash, Timing (时钟), 2PC, 3PC 等等。那么如何掌握好这些技术呢?以我个人的经验,掌握这些内容一定要理解其对应的上下文。什么意思呢?就是一定要去思考为什么在当下环境需要某项技术,如果没有这个技术用其它技术替代是否可行,而不是一味的陷入大量的细节之中。例如:如何掌握好 Paxos? Paxos本质上来说是一个三阶段提交,更 high level 讲是一个分布式锁。理解paxos必须一步一步从最简单的场景出发,比如从最简单的 master-backup 出发,发现不行,衍生出多数派读写,发现还是不行,再到 paxos. 之后再了解其变种,比如 fast paxos, multi-paxos. 同理为什么需要 Consistent Hash, 我们可以先思考如果用简单range partition 划分数据有什么问题。再比如学习 2pc, 3pc 这样的技术时,可以想想他们和paxos 有什么关系,能否替代 paxos。
以上是我关于分布式存储系统内容的一些总结,推荐一些相关的论文 ,有兴趣的读者可以看看:
The Google File System
Bigtable: A Distributed Storage System for Structured Data.
Dynamo: Amazon‘s Highly Available Key-value ...
Introduction to HBase Schema Design
Consistency Tradeoffs in Modern Distributed Database System Design
Spanner: Google’s Globally-Distributed Database
F1: A Distributed SQL Database That Scales
Tachyon: Reliable, Memory Speed Storage for Cluster Computing
RAMCloud and the Low- Latency DatacenterCassandra - A Decentralized Structured Storage System
MapReduce: A major step backwards
MapReduce and Parallel DBMSs: Friends or Foes?
A comparison of approaches to large scale data analysis
分布式计算系统
聊完了分布式存储系统,让我们来聊聊分布式计算系统 :) 首先解决一个很多初学分布式计算的同学的疑惑:分布式计算和并行计算是一回事吗?最初我也有这样的疑惑,而现在我的理解是这样的:
传统的并行计算要的是:投入更多机器,数据大小不变,计算速度更快。
分布式计算要求:投入更多的机器,能处理更大的数据。
换句话说二者的出发点从一开始就不同,一个强调 high performance, 一个强调 scalability. 举例来说,MapReduce 给业界带来的真正的思考是什么?其实是给我们普及了 google 这样级别的公司对真正意义上的「大数据」的理解。因为在 04 年论文出来之前,搞并行计算的人压根连 「容错」的概念都没有。换句话说,分布式计算最为核心的部分就是「容错」,没有容错,分布式计算根本无从谈起。MapReduce 统要做成这个样子(map + reduce),其实就是为了容错。
然而很多初学分布式计算的同学对容错的概念多多少少是有误解的。包括我在初学 mapreduce 的时候也会思考:好好的计算怎么就会出错了呢?一方面,由于硬件的老化,有可能会导致某台存储设备没有启动起来,某台机器的网卡坏了,甚至于计算运行过程中断电了,这些都是有可能的。然而最平凡发生的错误是计算进程被杀掉。因为 google 的运行环境是共有集群,任何一个权限更高的进程都可能 kill 掉你的计算进程。设想在一个拥有几千台机器的集群中运行,一个进程都不被 kill 掉的概率几乎为零。具体的容错机制我们会在后面介绍具体的系统时提到。
另一个有意思的话题是,随着机器学习技术的兴起,越来越多的分布式计算系统是为了机器学习这样的应用设计的,这也是我比较关注的研究领域,也会在后面重点谈到。
如同分布式存储系统一样,我对分布式计算系统也做了一个分类,如下:
1. 传统基于msg的系统
2. MapReduce-like 系统
3. 图计算系统
4. 基于状态(state)的系统
5. Streaming 系统
当然不同的人可能会有不同的分类方法,不过大同小异。我们接下来聊聊这些系统都在干些什么。
传统基于msg的系统 . 这类系统里比较有代表性的就是 MPI (message passing interface). 目前比较流行的两个 MPI 实现是 mpich2 和 openmpi . MPI 这个框架非常灵活,对程序的结构几乎没有太多约束,以至于大家有时把 MPI 称为一组接口 API, 而不是系统框架。在这些 API 里最常用的两个就是 send 和 recv 接口(还有一系列非阻塞扩展接口,例如:Isend, Irecv 等)。MPI 除了提供消息传递接口之外,其框架还实现了资源管理和分配,以及调度的功能。除此之外,MPI 在高性能计算里也被广泛使用,通常可以和 Infiniband 这样的高速网络无缝结合。
除了 send 和 recv 接口之外,MPI 中另一个接口也值得注意,那就是 AllReduce. 这个接口在很多机器学习系统开发里都很用。因为很多并行机器学习系统都是各个进程分别训练模型,然后再合适的时候(例如一轮迭代结束)大家同步一下答案,达成共识,然后继续迭代。这个 “达成共识” 的操作往往可以很方便的通过 AllReduce 来完成。 AllReduce 接口具有两个优点:1. 高效。 2. 实用简单。 先说说为什么使用简单。使用 AllReduce 通常只需要在单机核心源码里加入 AllReduce 一行代码,就能完成并行化的功能。说 AllReduce 高效的原因是因为其底层消息传递使用了 tree aggregation,尽可能的将计算分摊到每一个节点。
可是,既然 AllReduce 这么好,为什么在实际大大规模计算中很少看到呢?原因很简单,就是因为 MPI 不支持容错,所以很难扩展到大规模集群之上。不过最近陈天奇写了一个支持容错的 allreduce 接口,叫rabit,有兴趣的同学可以关注一下。 大名鼎鼎的 xgboost 底层的分布式接口就是 rabit.
MapReduce-like 系统. 这一类系统又叫作 dataflow 系统,其中以 MapReduce (Hadoop) 和 Spark 为代表。其实在学术界很有很多类似的系统例如 Dryad, FlumeJava, Twister 等等。这一类系统的特点是将计算抽象成为 high-level operator, 例如像 map,reduce,filter 这样的函数式算子,然后将算子组合成 DAG ,然后由后端的调度引擎进行并行化调度。其中,MapReduce 系统属于比较简单的 DAG,只有 map 和 reduce 两层节点。MapReduce 这样的系统之所以可以扩展到超大规模的集群上运行,就是因为其完备的容错机制。在 Hadoop 社区还有很多基于 mapreduce 框架的衍生产品,比如 Hive (并行数据库OLAP), Pig(交互式数据操作)等等。
MapReduce-like 的编程风格和 MPI 截然相反。MapReduce对程序的结构有严格的约束——计算过程必须能在两个函数中描述:map 和 reduce;输入和输出数据都必须是一个一个的 records;任务之间不能通信,整个计算过程中唯一的通信机会是 map phase 和 reduce phase 之间的 shuffuling phase,这是在框架控制下的,而不是应用代码控制的。因为有了严格的控制,系统框架在任何时候出错都可以从上一个状态恢复。Spark 的 RDD 则是利用 Lineage,可以让数据在内存中完成转换。
由于良好的扩展性,许多人都机器学习算法的并行化任务放在了这些平台之上。比较有名的库包括 Mahout (基于Hadoop), 以及 MLI (基于 Spark) . 然而这些系统最大缺点有两点:
1. 这些系统所能支持的机器学习模型通常都不是很大。导致这个问题的主要原因是这系统在 push back 机器学习模型时都是粗粒度的把整个模型进行回传,导致了网络通信的瓶颈。有些机器学习的模型可以大到无法想象,比如我们用 Field-aware factorization machine (FFM)做 criteo 的 ctr prediction 时模型大小可以达到100 GB.
2. 严格的 BSP 同步计算使得集群的效率变的很低。也就是说系统很容易受到straggle的影响。
图计算系统. 图计算系统是分布式计算里另一个分支,这些系统都是把计算过程抽象成图,然后在不同节点分布式执行,例如 PageRank 这样的任务,很适合用图计算系统来表示。最早成名的图计算系统当属 Google 的 pregel,该系统采用 BSP 模型,计算以 vectex 为中心。随后又有一系列图计算框架推出,例如:GPS (对 Pregel 做了优化,除了vectex-centric computation,还有 global computation,动态调整分区等等。)Giraph / Hama 都是基于 Hadoop 的 Apache 的开源 BSP 图计算项目。
除了同步(BSP)图计算系统之外,异步图计算系统里的佼佼者当属 GraphLab,该系统提出了 GAS 的编程模型。目前这个项目已经该名为 dato.,专门推广基于图的大规模机器学习系统。
基于状态(state)的系统. 这一类系统主要包括 2010 年 OSDI 上推出的 Piccolo, 以及后来 2012 年 nips 上 Google 推出的 distbelief,再到后来被机器系学习领域广泛应用的 Parameter Server 架构。这里我们重点介绍一下 Parameter Server 这个架构。
我们之前说,MPI 由于不支持容错所以很难扩展至大规模集群之中;MapReduce 系统无法支持大模型机器学习应用,并且节点同步效率较低。用图抽象来做机器学习任务,很多问题都不能很好的求解,比如深度学习中的多层结构。而 Parameter Server 这种 state-centric 模型则把机器学习的模型存储参数上升为主要组件,并且采用异步机制提升处理能力。参数服务器的概念最早来自于 Alex Smola 于 2010 年提出的并行 LDA 架构。它通过采用分布式的 memcached 作为存放参数的存储,这样就提供了有效的机制作用于不同worker节点同步模型参数。 Google 的 jeff dean 在 2012 年进一步提出了第一代 Google Brain 大规模神经网络的解决方案 Distbelief. 在后来的 CMU 的 Eric xing 以及百度少帅 李沐 都提出了更通用的 Parameter server 架构。
如果要深入 Parameter server 系统的设计,需要一些机器学习的背景,比如什么是 ssp 协议, 在此我们就不详细讨论了。
Streaming 系统. Streaming 系统听名字就能看出来是为流式数据提供服务的。其中比较有名的系统包括 Storm, Spark Streaming, Flink 等等。由于本人对这个领域并不是很熟,就不详细介绍了。
以上是我对分布式计算系统的一些介绍,其实每一个方向深入下去都是一个研究领域,在此推荐一些论文:
MapReduce: Simplified Data Processing on Large Clusters
Resilient Distributed Datasets
Scaling Distributed Machine Learning with the Parameter Server
Distributed GraphLab: A Framework for Machine Learning
Piccolo: Building Fast, Distributed Programs with Partitioned ..
Petuum: A New Platform for Distributed Machine Learning on Big Data
Spark Streaming
Dryad: Distributed Data-parallel Programs from Sequential Building ...
Large Scale Distributed Deep Networks - NIPS Proceedings
分布式管理系统:
CAP理论概述
一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项。
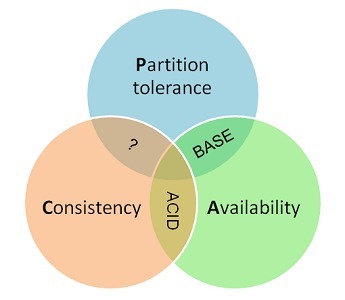
CAP的定义
Consistency 一致性
一致性指“all nodes see the same data at the same time”,即更新操作成功并返回客户端完成后,所有节点在同一时间的数据完全一致。分布式的一致性
对于一致性,可以分为从客户端和服务端两个不同的视角。从客户端来看,一致性主要指的是多并发访问时更新过的数据如何获取的问题。从服务端来看,则是更新如何复制分布到整个系统,以保证数据最终一致。一致性是因为有并发读写才有的问题,因此在理解一致性的问题时,一定要注意结合考虑并发读写的场景。
从客户端角度,多进程并发访问时,更新过的数据在不同进程如何获取的不同策略,决定了不同的一致性。对于关系型数据库,要求更新过的数据能被后续的访问都能看到,这是强一致性。如果能容忍后续的部分或者全部访问不到,则是弱一致性。如果经过一段时间后要求能访问到更新后的数据,则是最终一致性。
Availability 可用性
可用性指“Reads and writes always succeed”,即服务一直可用,而且是正常响应时间。
对于一个可用性的分布式系统,每一个非故障的节点必须对每一个请求作出响应。也就是,该系统使用的任何算法必须最终终止。当同时要求分区容忍性时,这是一个很强的定义:即使是严重的网络错误,每个请求必须终止。
好的可用性主要是指系统能够很好的为用户服务,不出现用户操作失败或者访问超时等用户体验不好的情况。可用性通常情况下可用性和分布式数据冗余,负载均衡等有着很大的关联。
Partition Tolerance分区容错性
分区容错性指“the system continues to operate despite arbitrary message loss or failure of part of the system”,即分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务。
分区容错性和扩展性紧密相关。在分布式应用中,可能因为一些分布式的原因导致系统无法正常运转。好的分区容错性要求能够使应用虽然是一个分布式系统,而看上去却好像是在一个可以运转正常的整体。比如现在的分布式系统中有某一个或者几个机器宕掉了,其他剩下的机器还能够正常运转满足系统需求,或者是机器之间有网络异常,将分布式系统分隔未独立的几个部分,各个部分还能维持分布式系统的运作,这样就具有好的分区容错性。
CAP的证明
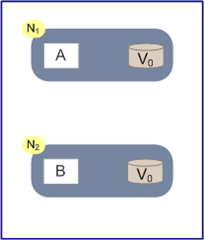
如上图,是我们证明CAP的基本场景,网络中有两个节点N1和N2,可以简单的理解N1和N2分别是两台计算机,他们之间网络可以连通,N1中有一个应用程序A,和一个数据库V,N2也有一个应用程序B2和一个数据库V。现在,A和B是分布式系统的两个部分,V是分布式系统的数据存储的两个子数据库。
在满足一致性的时候,N1和N2中的数据是一样的,V0=V0。在满足可用性的时候,用户不管是请求N1或者N2,都会得到立即响应。在满足分区容错性的情况下,N1和N2有任何一方宕机,或者网络不通的时候,都不会影响N1和N2彼此之间的正常运作。
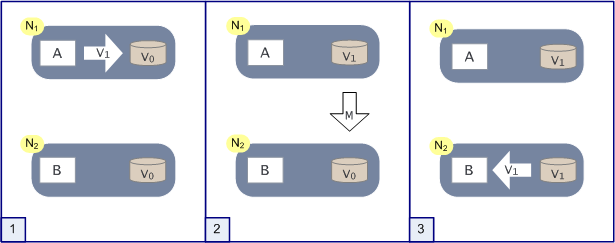
如上图,是分布式系统正常运转的流程,用户向N1机器请求数据更新,程序A更新数据库Vo为V1,分布式系统将数据进行同步操作M,将V1同步的N2中V0,使得N2中的数据V0也更新为V1,N2中的数据再响应N2的请求。
这里,可以定义N1和N2的数据库V之间的数据是否一样为一致性;外部对N1和N2的请求响应为可用行;N1和N2之间的网络环境为分区容错性。这是正常运作的场景,也是理想的场景,然而现实是残酷的,当错误发生的时候,一致性和可用性还有分区容错性,是否能同时满足,还是说要进行取舍呢?
作为一个分布式系统,它和单机系统的最大区别,就在于网络,现在假设一种极端情况,N1和N2之间的网络断开了,我们要支持这种网络异常,相当于要满足分区容错性,能不能同时满足一致性和响应性呢?还是说要对他们进行取舍。
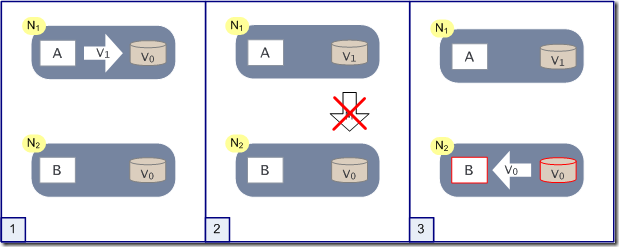
假设在N1和N2之间网络断开的时候,有用户向N1发送数据更新请求,那N1中的数据V0将被更新为V1,由于网络是断开的,所以分布式系统同步操作M,所以N2中的数据依旧是V0;这个时候,有用户向N2发送数据读取请求,由于数据还没有进行同步,应用程序没办法立即给用户返回最新的数据V1,怎么办呢?有二种选择,第一,牺牲数据一致性,响应旧的数据V0给用户;第二,牺牲可用性,阻塞等待,直到网络连接恢复,数据更新操作M完成之后,再给用户响应最新的数据V1。
这个过程,证明了要满足分区容错性的分布式系统,只能在一致性和可用性两者中,选择其中一个。
CAP权衡
通过CAP理论,我们知道无法同时满足一致性、可用性和分区容错性这三个特性,那要舍弃哪个呢?
CA without P:如果不要求P(不允许分区),则C(强一致性)和A(可用性)是可以保证的。但其实分区不是你想不想的问题,而是始终会存在,因此CA的系统更多的是允许分区后各子系统依然保持CA。
CP without A:如果不要求A(可用),相当于每个请求都需要在Server之间强一致,而P(分区)会导致同步时间无限延长,如此CP也是可以保证的。很多传统的数据库分布式事务都属于这种模式。
AP wihtout C:要高可用并允许分区,则需放弃一致性。一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。现在众多的NoSQL都属于此类。
对于多数大型互联网应用的场景,主机众多、部署分散,而且现在的集群规模越来越大,所以节点故障、网络故障是常态,而且要保证服务可用性达到N个9,即保证P和A,舍弃C(退而求其次保证最终一致性)。虽然某些地方会影响客户体验,但没达到造成用户流程的严重程度。
对于涉及到钱财这样不能有一丝让步的场景,C必须保证。网络发生故障宁可停止服务,这是保证CA,舍弃P。貌似这几年国内银行业发生了不下10起事故,但影响面不大,报到也不多,广大群众知道的少。还有一种是保证CP,舍弃A。例如网络故障事只读不写。
孰优孰略,没有定论,只能根据场景定夺,适合的才是最好的。
. BASE理论
eBay的架构师Dan Pritchett源于对大规模分布式系统的实践总结,在ACM上发表文章提出BASE理论,BASE理论是对CAP理论的延伸,核心思想是即使无法做到强一致性(Strong Consistency,CAP的一致性就是强一致性),但应用可以采用适合的方式达到最终一致性(Eventual Consitency)。
BASE是指基本可用(Basically Available)、软状态( Soft State)、最终一致性( Eventual Consistency)。
3.1 基本可用(Basically Available)
基本可用是指分布式系统在出现故障的时候,允许损失部分可用性,即保证核心可用。电商大促时,为了应对访问量激增,部分用户可能会被引导到降级页面,服务层也可能只提供降级服务。这就是损失部分可用性的体现。
3.2 软状态( Soft State)
软状态是指允许系统存在中间状态,而该中间状态不会影响系统整体可用性。分布式存储中一般一份数据至少会有三个副本,允许不同节点间副本同步的延时就是软状态的体现。mysql replication的异步复制也是一种体现。
3.3 最终一致性( Eventual Consistency)
最终一致性是指系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。弱一致性和强一致性相反,最终一致性是弱一致性的一种特殊情况。4. ACID和BASE的区别与联系
ACID是传统数据库常用的设计理念,追求强一致性模型。BASE支持的是大型分布式系统,提出通过牺牲强一致性获得高可用性。
ACID和BASE代表了两种截然相反的设计哲学
在分布式系统设计的场景中,系统组件对一致性要求是不同的,因此ACID和BASE又会结合使用。
以上是关于分布式系统的主要内容,如果未能解决你的问题,请参考以下文章