openstack 装逼之路~keystone之HTTP协议
Posted 迎领启航
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了openstack 装逼之路~keystone之HTTP协议相关的知识,希望对你有一定的参考价值。
第一:为什么学习HTTP协议?
1.http协议就是通信的双方共同遵守的规则。无规矩不成方圆
2.openstack中各组件是基于restful api通信的,restful api可以单纯的理解为一个url地址:http://www.cnblogs.com/ylqh/p/6295088.html
因而不管研究openstack内的任何组件,都离不开http协议,要想成为一名合格的openstack架构师或者openstack开发工程师,这是必经之路
第二:用户通过浏览器上网过程
用户上网基于客户端-服务端架构。浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求。Web服务器根据接收到的请求后,向客户端发送响应信息。
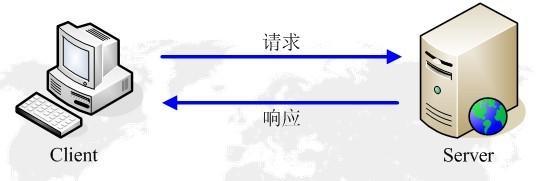
1.保证web Server运行,Client运行浏览器软件
2.用户在client的浏览器中输入http://www.cnblogs.com/
3.客户端浏览器处理http://www.cnblogs.com/,发起查询本地DNS操作,将www.cnblog.com解析为42.121.252.58
(穿插)DNS的过程是这样的:首先我们知道我们本地的机器上在配置网络时都会填写DNS,这样本机就会把这个url发给这个配置的DNS服务器,如果能够找到相应的url则返回其ip,否则该DNS将继续将该解析请求发送给上级DNS,整个DNS可以看做是一个树状结构,该请求将一直发送到根直到得到结果。现在已经拥有了目标ip和端口号,这样我们就可以打开socket连接了。
4.客户端浏览器发送http请求http://42.121.252.58/index.html (注意:80是web服务器的默认端口,index.html是默认的请求的资源)
5.服务端web服务收到该http的request请求头,从请求头中获取客户端的方法GET/POST.../index.html这个路径,及客户端请求的其他相关信息
6.服务端web服务根据取得的信息,回复respone响应头
响应头中包含:
响应代码:200表示成功,3xx表示重定向,4xx表示客户端发送的请求有错误,5xx表示服务器端处理时发生了错误;
响应类型:由Content-Type指定;
以及其他相关的Header;
通常服务器的HTTP响应会携带内容,也就是有一个Body,包含响应的内容,网页的HTML源码就在Body中,压缩后返回给客户端。
7.客户端浏览器收到服务端发来的数据,解压后解析html内容,用户就看到网页内容了
8.html内可能嵌套其他的链接,比方说图片、视频、javascript脚本,flash等,客户端浏览器会继续发起http请求来获取它们。这样来自图片和视频的压力就被分散到各个服务器,一个站点由无数个站点相互连接起来,就形成了World Wide Web,简称WWW。
综上,其实就是一次http请求-响应的流程
第三:HTTP协议详解
part1:http协议概述
协议是指计算机通信网络中两台计算机之间进行通信所必须共同遵守的规定或规则,超文本传输协议(HTTP)是一种通信协议,它允许将超文本标记语言(HTML)文档从Web服务器传送到客户端的浏览器。
HTTP协议,即超文本传输协议(Hypertext transfer protocol)。是一种详细规定了浏览器和万维网(WWW = World Wide Web)服务器之间互相通信的规则,通过因特网传送万维网文档的数据传送协议。
HTTP协议是用于从WWW服务器传输超文本到本地浏览器的传送协议。它可以使浏览器更加高效,使网络传输减少。它不仅保证计算机正确快速地传输超文本文档,还确定传输文档中的哪一部分,以及哪部分内容首先显示(如文本先于图形)等。
HTTP是一个应用层协议,由请求和响应构成,是一个标准的客户端服务器模型。HTTP是一个无状态的协议。
HTTP就是一个通信规则,通信规则规定了客户端发送给服务器的内容格式,也规定了服务器发送给客户端的内容格式。其实我们要学习的就是这个两个格式!客户端发送给服务器的格式叫“请求协议”;服务器发送给客户端的格式叫“响应协议”。
特点:
- HTTP叫超文本传输协议,基于请求/响应模式的!
- HTTP是无状态协议,FTP是有状态。
URL:统一资源定位符,就是一个网址:协议名://域名:端口/路径,例如:http://www.baidu.com:80/index.html
part2:http请求协议
根据HTTP标准,HTTP请求可以使用多种请求方法。
请求格式:
请求首行; // 请求方式 请求路径 协议和版本,例如:GET /index.html HTTP/1.1 请求头信息;// 请求头名称:请求头内容,即为key:value格式,例如:Host:localhost 空行; // 用来与请求体分隔开 请求体。 // GET没有请求体,只有POST有请求体。
浏览器发送给服务器的内容就这个格式的,如果不是这个格式服务器将无法解读!
HTTP1.0定义了三种请求方法: GET, POST 和 HEAD方法。
GET:请求指定的页面信息,并返回实体主体
HEAD:类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头
POST:向指定的资源提交数据进行处理请求(提交表单或者上传文件等)。数据被包含在请求体中。post请求可能会导致新的资源建立或已有的资源修改
HTTP1.1新增了五种请求方法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT 方法。
OPTIONS:允许客户端查看服务器的性能
PUT:从客户端向服务器传送的数据取代指定的文档内容
DELETE:请求服务器删除指定的页面
TRACE:回显服务器收到的请求,主要用于测试或者诊断
CONNECT:HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。
详细介绍get与post的
3.1:get请求
HTTP默认的请求方法就是GET
* 没有请求体
* 数据必须在1K之内!
* GET请求数据会暴露在浏览器的地址栏中
GET请求常用的操作:
1. 在浏览器的地址栏中直接给出URL,那么就一定是GET请求
2. 点击页面上的超链接也一定是GET请求
3. 提交表单时,表单默认使用GET请求,但可以设置为POST
GET / HTTP/1.1 GET请求,请求服务器路径 http://www.cnblog.com/,协议为1.1 Host: www.cnblogs.com 请求主机名为www.cnblogs.com; Connection: keep-alive 客户端支持的链接方式,保持一段时间的链接,默认为3000ms; Cache-Control: no-cache 设置网页缓存的使用方法,no-cache Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8 告诉服务器,当前客户端可以接收的文档类型,其实这里包含*/*,就表示什么都可以接收
Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.86 Safari/537.36 与浏览器和OS相关的信息。有些网站会显示用户的系统版本和浏览器版本信息,这些都是通过获取User-Agent头信息而来的 Accept-Encoding: gzip, deflate, sdch 支持的压缩格式。数据在网络中传递时,可能服务器会把数据压缩后再发送; Accept-Language: zh-CN,zh;q=0.8 当前客户端支持的语言,可以在浏览器的工具口选项中找到语言相关信息 Cookie: AJSTAT_ok_times=2; __gads=ID=a8d50d555d273ea1:T=1471706765:S=ALNI_MYq_N5OuQbl1g04h0K_EB2dkbuDGg; CNZZDATA1257933522=462904915-1474644595-http%253A%252F%252Fzzk.cnblogs.com%252F%7C1474644595; Hm_lvt_88e110cc097c67c394f60bd3cf28fe1d=1480609307,1480690239; CNZZDATA3820487=cnzz_eid%3D769726809-1480609172-null%26ntime%3D1480690318; bdshare_firstime=1482637005632; sc_is_visitor_unique=rx9614694.1482854505.4BB3B56595534F38D9FB4F9D4E7F00A7.1.1.1.1.1.1.1.1.1; SyntaxHighlighter=python; .CNBlogsCookie=83971A2955426E5058FE012AA26E9962B77107E9131631A3CF4F83AF75841F628FE521A8EFD5884DB85BDE3AC07BE5744B4BED650DC98B7276B94E5B091D1D0915D9B882C3F06DFDF275FDC90343827300FA7160; _ga=GA1.2.1053365510.1445657028; CNZZDATA1684828=cnzz_eid%3D151763049-1485872317-null%26ntime%3D1485872337; __utma=226521935.1053365510.1445657028.1485873377.1485873377.1; __utmc=226521935; __utmz=226521935.1485873377.1.1.utmcsr=baidu|utmccn=(organic)|utmcmd=organic
3.2:post请求
(1) 数据不会出现在地址栏中
(2) 数据的大小没有上限
(3) 有请求体
(4) 请求体中如果存在中文,会使用URL编码!
<!DOCTYPE html> <html> <body> <form method="post"> 用户名:<br> <input type="text" name="username"> <br> 密码:<br> <input type="text" name="password"> <input type="submit" value="登录"> </form> </body> </html>
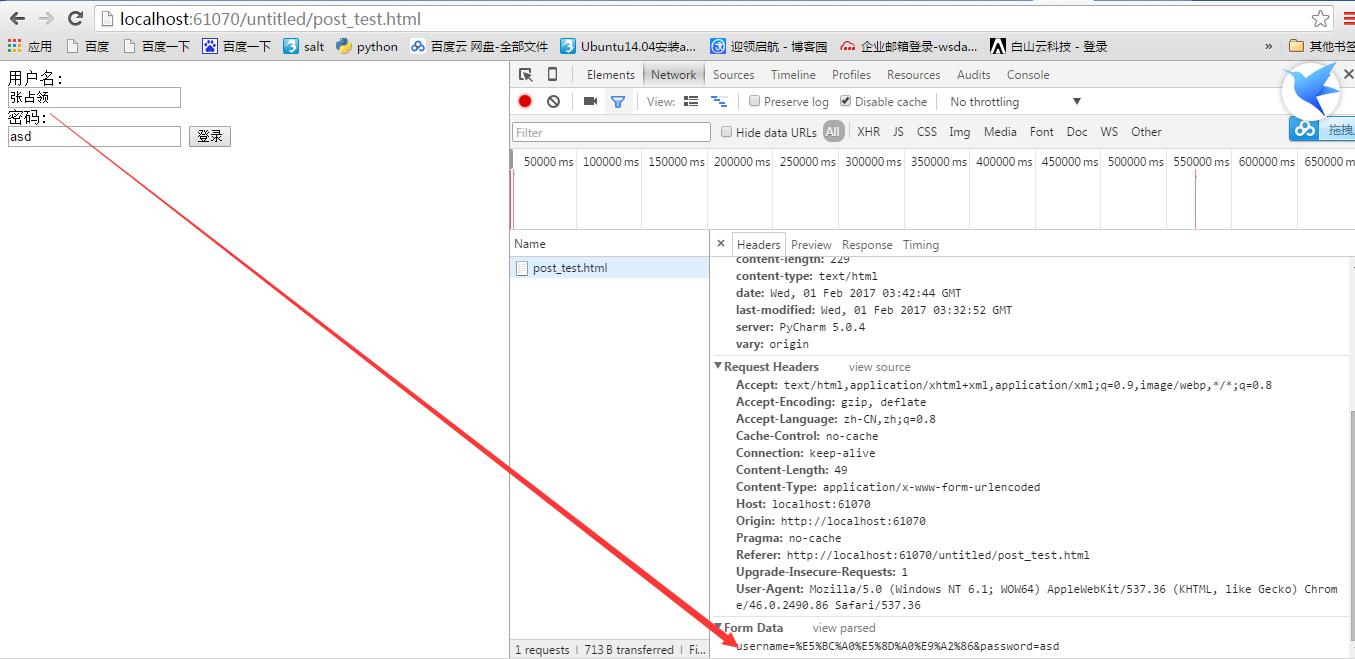
我们都知道Http协议中参数的传输是"key=value"这种简直对形式的,如果要传多个参数就需要用“&”符号对键值对进行分割。如"?name1=value1&name2=value2",这样在服务端在收到这种字符串的时候,会用“&”分割出每一个参数,然后再用“=”来分割出参数值。
针对“name1=value1&name2=value2”我们来说一下客户端到服务端的概念上解析过程: 上述字符串在计算机中用ASCII吗表示为: 6E616D6531 3D 76616C756531 26 6E616D6532 3D 76616C756532。 6E616D6531:name1 3D:= 76616C756531:value1 26:& 6E616D6532:name2 3D:= 76616C756532:value2 服务端在接收到该数据后就可以遍历该字节流,首先一个字节一个字节的吃,当吃到3D这字节后,服务端就知道前面吃得字节表示一个key,再想后吃,如果遇到26,说明从刚才吃的3D到26子节之间的是上一个key的value,以此类推就可以解析出客户端传过来的参数。 现在有这样一个问题,如果我的参数值中就包含=或&这种特殊字符的时候该怎么办。 比如说“name1=value1”,其中value1的值是“va&lu=e1”字符串,那么实际在传输过程中就会变成这样“name1=va&lu=e1”。我们的本意是就只有一个键值对,但是服务端会解析成两个键值对,这样就产生了奇异。
如何解决上述问题带来的歧义呢?解决的办法就是对参数进行URL编码 URL编码只是简单的在特殊字符的各个字节前加上%,例如,我们对上述会产生奇异的字符进行URL编码后结果:“name1=va%26lu%3D”,这样服务端会把紧跟在“%”后的字节当成普通的字节,就是不会把它当成各个参数或键值对的分隔符。
POST请求是可以有体的,而GET请求不能有请求体。

- Referer: http://localhost:61070/untitled/post_test.html:请求来自哪个页面,例如你在博客园上点击链接到了这里,那么Referer:http://www.cnbolgs.com;如果你是在浏览器的地址栏中直接输入的地址,那么就没有Referer这个请求头了;
- Content-Type: application/x-www-form-urlencoded:表单的数据类型,说明会使用url格式编码数据;url编码的数据都是以“%”为前缀,后面跟随两位的16进制。
- Content-Length:49:请求体的长度,这里表示13个字节。
- username=‘张占领’:请求体内容!
part4:响应协议
4.1:响应内容:
消息协议的版本、成功或者错误编码、服务器信息、实体元信息以及必要的实体内容。根据响应类别的类别,服务器响应里可以含实体内容,但不是所有的响应都有实体内容

第一行为状态行:HTTP-Version 空格 Status-Code 空格 Reason-Phrase CRLF
HTTP- Version表示HTTP版本,例如为HTTP/1.1。Status- Code是结果代码,用三个数字表示。Reason-Phrase是个简单的文本描述,解释Status-Code的具体原因。Status-Code用于机器自动识别,Reason-Phrase用于人工理解。Status-Code的第一个数字代表响应类别,可能取5个不同的值。后两个数字没有分类作用。Status-Code的第一个数字代表响应的类别,后续两位描述在该类响应下发生的具体状况,具体请参见:HTTP状态码
content-type: text/html 返回时文本格式、html文件
- Server:Pycharm 5.0.4:服务器的版本信息
- date: Wed, 01 Feb 2017 04:11:17 GMT:响应的时间,这可能会有8小时的时区差;
- cache-control:private,must-revalidate 详细介绍:
-
 View Code
View Code网页的缓存是由HTTP消息头中的“Cache-control”来控制的,常见的取值有private、no-cache、max-age、must-revalidate等,默认为private。其作用根据不同的重新浏览方式分为以下几种情况: (1) 打开新窗口 值为private、no-cache、must-revalidate,那么打开新窗口访问时都会重新访问服务器。 而如果指定了max-age值,那么在此值内的时间里就不会重新访问服务器,例如: Cache-control: max-age=5(表示当访问此网页后的5秒内再次访问不会去服务器) (2) 在地址栏回车 值为private或must-revalidate则只有第一次访问时会访问服务器,以后就不再访问。 值为no-cache,那么每次都会访问。 值为max-age,则在过期之前不会重复访问。 (3) 按后退按扭 值为private、must-revalidate、max-age,则不会重访问, 值为no-cache,则每次都重复访问 (4) 按刷新按扭 无论为何值,都会重复访问 Cache-control值为“no-cache”时,访问此页面不会在Internet临时文章夹留下页面备份。
- Content-Type: text/html;charset=UTF-8:响应体使用的编码为UTF-8;
- last-modified:Wed,01 Feb 2017 04:10:40 上次修改的时间
- Content-Length: 209:响应体为209字节

4.2:状态码
100: 客户端应当继续发送请求。这个临时响应是用来通知客户端它的部分请求已经被服务器接收,且仍未被拒绝。客户端应当继续发送请求的剩余部分,或者如果请求已经完成,忽略这个响应。服务器必须在请求完成后向客户端发送一个最终响应。
101: 服务器已经理解了客户端的请求,并将通过Upgrade 消息头通知客户端采用不同的协议来完成这个请求。在发送完这个响应最后的空行后,服务器将会切换到在Upgrade 消息头中定义的那些协议。 只有在切换新的协议更有好处的时候才应该采取类似措施。例如,切换到新的HTTP 版本比旧版本更有优势,或者切换到一个实时且同步的协议以传送利用此类特性的资源。
200:请求成功,浏览器会把响应体内容(通常是html)显示在浏览器中;
404:请求的资源没有找到,说明客户端错误的请求了不存在的资源;
500:请求资源找到了,但服务器内部出现了错误;
302:重定向,当响应码为302时,表示服务器要求浏览器重新再发一个请求,服务器会发送一个响应头Location,它指定了新请求的URL地址;
304:如果客户端发送了一个带条件的 GET 请求且该请求已被允许,而文档的内容(自上次访问以来或者根据请求的条件)并没有改变,则服务器应当返回这个状态码。304响应禁止包含消息体,因此始终以消息头后的第一个空行结尾。 该响应必须包含以下的头信息: Date,除非这个服务器没有时钟。假如没有时钟的服务器也遵守这些规则,那么代理服务器以及客户端可以自行将 Date 字段添加到接收到的响应头中去(正如RFC 2068中规定的一样),缓存机制将会正常工作。 ETag 和/或 Content-Location,假如同样的请求本应返回200响应。 Expires, Cache-Control,和/或Vary,假如其值可能与之前相同变量的其他响应对应的值不同的话。 假如本响应请求使用了强缓存验证,那么本次响应不应该包含其他实体头;否则(例如,某个带条件的 GET 请求使用了弱缓存验证),本次响应禁止包含其他实体头;这避免了缓存了的实体内容和更新了的实体头信息之间的不一致。 假如某个304响应指明了当前某个实体没有缓存,那么缓存系统必须忽视这个响应,并且重复发送不包含限制条件的请求。 假如接收到一个要求更新某个缓存条目的304响应,那么缓存系统必须更新整个条目以反映所有在响应中被更新的字段的值。

4.3:其他相应头
告诉浏览器不要缓存的响应头:
- Expires: -1;
- Cache-Control: no-cache;
- Pragma: no-cache;
自动刷新响应头,浏览器会在3秒之后请求http://www.baidu.com:
- Refresh: 3;url=http://www.baidu.com
详解:
Expires是个好玩意,如果服务器上的网页经常变化,就把它设置为-1,表示立即过期。如果一个网页每天凌晨1点更新,可以把Expires设置为第二天的凌晨1点。 当HTTP1.1服务器指定CacheControl = no-cache时,浏览器就不会缓存该网页。 旧式 HTTP 1.0 服务器不能使用 Cache-Control 标题。 所以为了向后兼容 HTTP 1.0 服务器,IE使用Pragma:no-cache 标题对 HTTP 提供特殊支持。 如果客户端通过安全连接 (https://)/与服务器通讯,且服务器在响应中返回 Pragma:no-cache 标题, 则 Internet Explorer不会缓存此响应。注意:Pragma:no-cache 仅当在安全连接中使用时才防止缓存,如果在非安全页中使用,处理方式与 Expires:-1相同,该页将被缓存,但被标记为立即过期 header常用指令 header分为三部分: 第一部分为HTTP协议的版本(HTTP-Version); 第二部分为状态代码(Status); 第三部分为原因短语(Reason-Phrase)。 // fix 404 pages: 用这个header指令来解决URL重写产生的404 header header(\'HTTP/1.1 200 OK\'); // set 404 header: 页面没找到 header(\'HTTP/1.1 404 Not Found\'); //页面被永久删除,可以告诉搜索引擎更新它们的urls // set Moved Permanently header (good for redrictions) // use with location header header(\'HTTP/1.1 301 Moved Permanently\'); // 访问受限 header(\'HTTP/1.1 403 Forbidden\'); // 服务器错误 header(\'HTTP/1.1 500 Internal Server Error\'); // 重定向到一个新的位置 // redirect to a new location: header(\'Location: http://www.sina.com.cn); 延迟一段时间后重定向 // redrict with delay: header(\'Refresh: 10; url=http://www.sina.com.cn\'); print \'You will be redirected in 10 seconds\'; // 覆盖 X-Powered-By value // override X-Powered-By: php: header(\'X-Powered-By: PHP/4.4.0\'); header(\'X-Powered-By: Brain/0.6b\'); // 内容语言 (en = English) // content language (en = English) header(\'Content-language: en\'); //最后修改时间(在缓存的时候可以用到) // last modified (good for caching) $time = time() - 60; // or filemtime($fn), etc header(\'Last-Modified: \'.gmdate(\'D, d M Y H:i:s\', $time).\' GMT\'); // 告诉浏览器要获取的内容还没有更新 // header for telling the browser that the content // did not get changed header(\'HTTP/1.1 304 Not Modified\'); // 设置内容的长度 (缓存的时候可以用到): // set content length (good for caching): header(\'Content-Length: 1234\'); // 用来下载文件: // Headers for an download: header(\'Content-Type: application/octet-stream\'); header(\'Content-Disposition: attachment; filename="example.zip"\'); header(\'Content-Transfer-Encoding: binary\'); // 禁止缓存当前文档: // load the file to send:readfile(\'example.zip\'); // Disable caching of the current document: header(\'Cache-Control: no-cache, no-store, max-age=0, must-revalidate\'); header(\'Expires: Mon, 26 Jul 1997 05:00:00 GMT\'); // 设置内容类型: // Date in the pastheader(\'Pragma: no-cache\'); // set content type: header(\'Content-Type: text/html; charset=iso-8859-1\'); header(\'Content-Type: text/html; charset=utf-8\'); header(\'Content-Type: text/plain\'); // plain text file header(\'Content-Type: image/jpeg\'); // JPG picture header(\'Content-Type: application/zip\'); // ZIP file header(\'Content-Type: application/pdf\'); // PDF file header(\'Content-Type: audio/mpeg\'); // Audio MPEG (MP3,...) file header(\'Content-Type: application/x-shockwave-flash\'); // 显示登录对话框,可以用来进行HTTP认证 // Flash animation// show sign in box header(\'HTTP/1.1 401 Unauthorized\'); header(\'WWW-Authenticate: Basic realm="Top Secret"\'); print \'Text that will be displayed if the user hits cancel or \'; print \'enters wrong login data\';?>
4.4:html中指定相应头
在HTMl页面中可以使用<meta http-equiv="" content="">来指定响应头,例如在index.html页面中给出<meta http-equiv="Refresh" content="3;url=http://www.baidu.com">,表示浏览器只会显示index.html页面3秒,然后自动跳转到http://www.baidu.com.
第四:HTTP之URI、URL、URN
首先要弄清楚:URL和URN都是URI的子集。
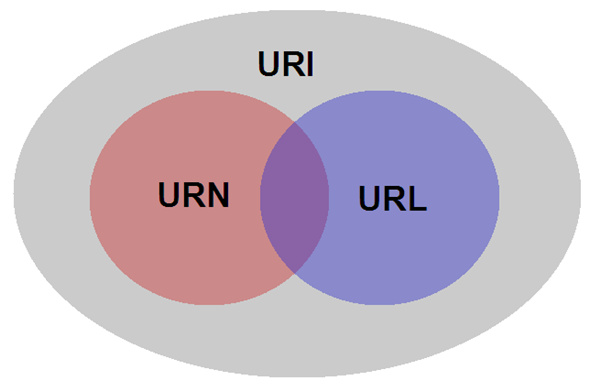
何为URI?
uniform resource identifier,统一资源标识符,用来唯一的标识一个资源
何为URL?
uniform resource locator,统一资源定位器
何为URN?
uniform resource name,统一资源命名,是通过名字来标识资源
URI、URL、URN的区分:
例如:http://www.cnblogs.com/ylqh/p/6359207.html举例来说
URI:http://www.cnblogs.com/ylqh/p/6359207.html
URN:www.cnblogs.com/ylqh/p/6359207.html
第五:抓包分析HTTP协议
用谷歌浏览器抓包示例:
web服务器收到的客户端发来的请求头:
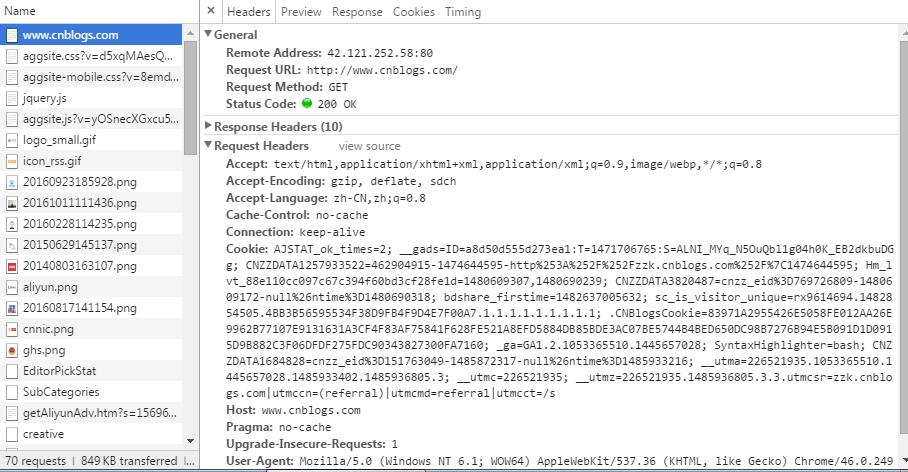
web服务器发给客户端的响应头(返回body就是html了)

以上是关于openstack 装逼之路~keystone之HTTP协议的主要内容,如果未能解决你的问题,请参考以下文章