使用beanstalkd实现定制化持续集成过程中pipeline - 持续集成系列
Posted 扎心了老铁
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用beanstalkd实现定制化持续集成过程中pipeline - 持续集成系列相关的知识,希望对你有一定的参考价值。
持续集成是一种项目管理和流程模型,依赖于团队中各个角色的配合。各个角色的意识和配合不是一朝一夕能练就的,我们的工作只是提供一种方案和能力,这就是持续集成能力的服务化。而在做持续集成能力服务化的过程中,最核心的一点就是,如何实现一个可定制化的任务流,即所谓的pipeline。
在传统的持续集成工具实现了pipeline功能,以供串联上下游job,并把多个job联系成一次完整的构建,例如jenkins的pipeline插件。
但是各种持续集成工具,或多或少都有自己的短板,总结起来如下:
1、配置并不方便,上下游job配置并不能点击即可用;
2、上下游job之间参数的传递无法很方便的实现;
3、一次完整构建链路如何trace并收集各个job的执行情况;
4、根据3实现问题的快速定位。
我们先说一下,beanstalkd实现可定制化pipeline的方法吧。
一、先通过概念让大家了解Beanstalkd的特性和工作场景。
Beanstalkd 是一个轻量级消息中间件,它最大特点是将自己定位为基于管道 (tube) 和任务 (job) 的工作队列 (work-queue):
Beanstalkd 支持任务优先级 (priority), 延时 (delay), 超时重发 (time-to-run) 和预留 (buried), 能够很好的支持分布式的后台任务和定时任务处理。
它的内部实现采用 libevent, 服务器-客户端之间用类似 memcached 的轻量级通讯协议,具有有很高的性能。
尽管是内存队列, beanstalkd 提供了 binlog 机制, 当重启 beanstalkd 时,当前任务状态能够从纪录的本地 binlog 中恢复。
管道 (tube):
管道类似于消息主题 (topic), 在一个 Beanstalkd 中可以支持多个管道, 每个管道都有自己的发布者 (producer) 和消费者 (consumer). 管道之间互相不影响。
任务 (job):
READY- 需要立即处理的任务,当延时 (DELAYED) 任务到期后会自动成为当前任务;
DELAYED- 延迟执行的任务, 当消费者处理任务后, 可以用将消息再次放回 DELAYED 队列延迟执行;
RESERVED- 已经被消费者获取, 正在执行的任务。Beanstalkd 负责检查任务是否在 TTR(time-to-run) 内完成;
BURIED- 保留的任务: 任务不会被执行,也不会消失,除非有人把它 "踢" 回队列;
DELETED- 消息被彻底删除。Beanstalkd 不再维持这些消息。
Beanstalkd 用任务 (job) 代替消息 (message) 的概念。与消息不同,任务有一系列状态:
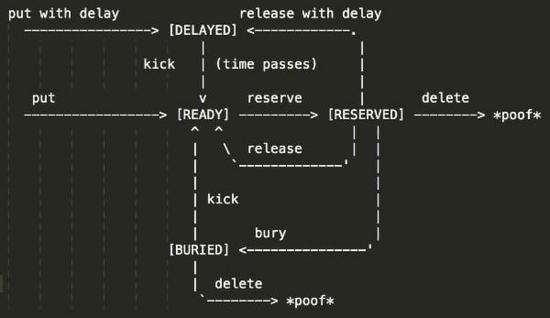
任务优先级 (priority):
任务 (job) 可以有 0~2^32 个优先级, 0 代表最高优先级。 beanstalkd 采用最大最小堆 (Min-max heap) 处理任务优先级排序, 任何时刻调用 reserve 命令的消费者总是能拿到当前优先级最高的任务, 时间复杂度为 O(logn).
延时任务 (delay):
有两种方式可以延时执行任务 (job): 生产者发布任务时指定延时;或者当任务处理完毕后, 消费者再次将任务放入队列延时执行 (RELEASE with <delay>)。这种机制可以实现分布式的 Java.util.Timer,这种分布式定时任务的优势是:如果某个消费者节点故障,任务超时重发 (time-to-run) 能够保证任务转移到另外的节点执行。
任务超时重发 (time-to-run):
Beanstalkd 把任务返回给消费者以后:消费者必须在预设的 TTR (time-to-run) 时间内发送 delete / release/ bury 改变任务状态;否则 Beanstalkd 会认为消息处理失败,然后把任务交给另外的消费者节点执行。如果消费者预计在 TTR (time-to-run) 时间内无法完成任务, 也可以发送 touch 命令, 它的作用是让 Beanstalkd 从系统时间重新计算 TTR (time-to-run).
任务预留 (buried):
如果任务因为某些原因无法执行, 消费者可以把任务置为 buried 状态让 Beanstalkd 保留这些任务。管理员可以通过 peek buried 命令查询被保留的任务,并且进行人工干预。简单的, kick <n> 能够一次性把 n 条被保留的任务踢回队列。
Beanstalkd 协议:
Beanstalkd 采用类 memcached 协议, 客户端通过文本命令与服务器交互。这些命令可以简单的分成三组:
生产类 - use <tube> / put <priority> <delay> <ttr> [bytes]:
生产者用 use 选择一个管道 (tube), 然后用 put 命令向管道发布任务 (job).
消费类 - watch <tubes> / reserve / delete <id> / release <id> <priority> <delay> / bury <id> / touch <id>
消费者用 watch 选择多个管道 (tube), 然后用 reserve 命令获取待执行的任务,这个命令是阻塞的。客户端直到有任务可执行才返回。当任务处理完毕后, 消费者可以彻底删除任务 (DELETE), 释放任务让别人处理 (RELEASE), 或者保留 (BURY) 任务。
维护类 - peek job / peek delayed / peek ready / peek buried / kick <n>
用于维护管道内的任务状态, 在不改变任务状态的条件下获取任务。可以用消费类命令改变这些任务的状态。
被保留 (buried) 的任务可以用 kick 命令 "踢" 回队列。
二、python对beanstalkd的封装
import beanstalkc class BstkManager(object): __doc__ = \'beanstalk封装类,这里只封装了用到的方法\' def __init__(self, config): self.config = config self.conn = self.__createConnection(self.config) def __createConnection(self, config): try: conn = beanstalkc.Connection(host=config.get(\'host\'), port=int(config.get(\'port\'))) return conn except Exception, ex: raise Exception(\'beanstalkd connection can not be established!\', ex) def getConnection(self): return self.conn def put(self, message, tube=None): try: tube = self.config.get(\'topic\') if tube == None else tube self.conn.use(tube) self.conn.ignore(\'default\') self.conn.put(message) except Exception, ex: raise Exception(\'put message to %s failure!\' % tube, ex) def reserve(self, tube=None, timeout=None): try: tube = self.config.get(\'topic\') if tube == None else tube self.conn.ignore(\'default\') self.conn.watch(tube) msg = self.conn.reserve(timeout=timeout) message_body = msg.body msg.delete() return message_body except Exception, ex: raise Exception(\'reserve message from %s failure!\' % tube, ex) def clean(self, tube=None): try: while True: tube = self.config.get(\'topic\') if tube == None else tube msg = self.conn.reserve(tube, timeout=1) # 如果超时 return if msg == None: return msg.delete() except Exception, ex: raise Exception(\'clean tube %s failure!\' % tube, ex)
在持续集成中,使用tube或者说topic区分不同的业务线,不同的业务人员通过向系统注册管道topic。这样做的收益是:
1、所有的业务在环境和流程上被隔离,互补干扰。
2、每个topic是一个独立的pipeline,每个pipeline之间是串行,但是topic之间是并行。这样保证一个业务线上的job是串行执行的,独占测试环境,而不用担心测试环境占用冲突。
import logging import os import sys import traceback import time from django.conf import settings from django.core.management.base import BaseCommand from beanstalkd_client import connect_beanstalkd, BeanstalkError from beanstalkc import SocketError logger = logging.getLogger(\'beanstalkd_client\') logger.addHandler(logging.StreamHandler()) class Command(BaseCommand): help = "Start a Beanstalk worker serving all registered Beanstalk jobs" __doc__ = help def add_arguments(self, parser): parser.add_argument( \'-w\', \'--workers\', action=\'store\', dest=\'worker_count\', default=\'1\', help=\'Number of workers to spawn.\', ) parser.add_argument( \'-l\', \'--log-level\', action=\'store\', dest=\'log_level\', default=\'info\', help=\'Log level of worker process (one of \' \'"debug", "info", "warning", "error"\', ) children = [] # list of worker processes jobs = {} def handle(self, *args, **options): # set log level logger.setLevel(getattr(logging, options[\'log_level\'].upper())) # find beanstalk job modules bs_modules = [] for app in settings.INSTALLED_APPS: try: modname = "%s.beanstalk_jobs" % app __import__(modname) bs_modules.append(sys.modules[modname]) except ImportError: pass if not bs_modules: logger.error("No beanstalk_jobs modules found!") return # find all jobs jobs = [] for bs_module in bs_modules: try: jobs += bs_module.beanstalk_job_list except AttributeError: pass if not jobs: logger.error("No beanstalk jobs found!") return logger.info("Available jobs:") for job in jobs: # determine right name to register function with app = job.app jobname = job.__name__ try: func = settings.BEANSTALK_JOB_NAME % { \'app\': app, \'job\': jobname, } except AttributeError: func = \'%s.%s\' % (app, jobname) self.jobs[func] = job logger.info("* %s" % func) # spawn all workers and register all jobs try: worker_count = int(options[\'worker_count\']) assert(worker_count > 0) except (ValueError, AssertionError): worker_count = 1 self.spawn_workers(worker_count) # start working logger.info("Starting to work... (press ^C to exit)") try: for child in self.children: os.waitpid(child, 0) except KeyboardInterrupt: sys.exit(0) def spawn_workers(self, worker_count): """ Spawn as many workers as desired (at least 1). Accepts: - worker_count, positive int """ # no need for forking if there\'s only one worker if worker_count == 1: return self.work() logger.info("Spawning %s worker(s)" % worker_count) # spawn children and make them work (hello, 19th century!) for i in range(worker_count): child = os.fork() if child: self.children.append(child) continue else: self.work() break def work(self): """children only: watch tubes for all jobs, start working""" try: while True: try: # Reattempt Beanstalk connection if connection attempt fails or is dropped beanstalk = connect_beanstalkd() for job in self.jobs.keys(): beanstalk.watch(job) beanstalk.ignore(\'default\') # Connected to Beanstalk queue, continually process jobs until an error occurs self.process_jobs(beanstalk) except (BeanstalkError, SocketError) as e: logger.info("Beanstalk connection error: " + str(e)) time.sleep(2.0) logger.info("retrying Beanstalk connection...") except KeyboardInterrupt: sys.exit(0) def process_jobs(self, beanstalk): while True: logger.debug("Beanstalk connection established, waiting for jobs") job = beanstalk.reserve() job_name = job.stats()[\'tube\'] if job_name in self.jobs: logger.debug("Calling %s with arg: %s" % (job_name, job.body)) try: self.jobs[job_name](job.body) except Exception, e: tp, value, tb = sys.exc_info() logger.error(\'Error while calling "%s" with arg "%s": \' \'%s\' % ( job_name, job.body, e, ) ) logger.debug("%s:%s" % (tp.__name__, value)) logger.debug("\\n".join(traceback.format_tb(tb))) job.bury() else: job.delete() else: job.release()
以上是关于使用beanstalkd实现定制化持续集成过程中pipeline - 持续集成系列的主要内容,如果未能解决你的问题,请参考以下文章
gitlab+jenkins+maven+docker持续集成——参数化构建过程之多环境tag构建
ML.NET机器学习API容器化与Azure DevOps实践:持续集成与k8s持续部署