XML引入,DOM 方式解析XML 原理,SAX 方式解析XML
Posted 梦碎轻抚尘埃
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了XML引入,DOM 方式解析XML 原理,SAX 方式解析XML相关的知识,希望对你有一定的参考价值。
XML 简介
Xml(eXtensible Markup Language) 即可扩展标记语言。
提供了一套跨平台、跨网络、跨程序的语言的数据描述方式,使用XML 可以方便地实现数据交换、系统配置、
内容管理等常见功能。
元素VS 节点
节点包括元素节点、属性节点、文本节点;
元素一定是节点,但是节点不一定是元素;
<?xml version="1.0" encoding="UTF-8"?> <emp> <empName empNo="10050">Allen</empName> <job>办事员</job> <addr>波士顿</addr> </emp>
DOM 方式解析XML 原理
基于DOM(Document Object Model,文档对象模型)解析方式,是把整个XML 文档加载到内存,转化成
DOM 树,因此应用程序可以随机的访问DOM 树的任何数据;
优点:灵活性强,速度快;
缺点:消耗资源比较多;
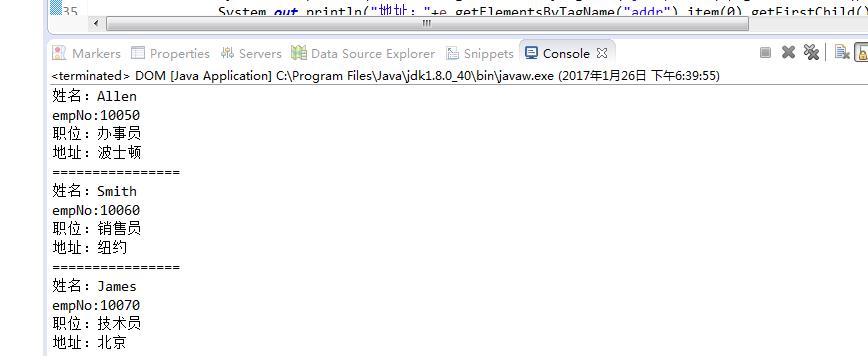
DOM 方式解析XML 示例
<?xml version="1.0" encoding="UTF-8"?> <emps> <emp> <empName empNo="10050">Allen</empName> <job>办事员</job> <addr>波士顿</addr> </emp> <emp> <empName empNo="10060">Smith</empName> <job>销售员</job> <addr>纽约</addr> </emp> <emp> <empName empNo="10070">James</empName> <job>技术员</job> <addr>北京</addr> </emp> </emps>
package com.zhiqi.test;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
public class DOM {
public static void printNodeAttr(Node node){
NamedNodeMap namedNodeMap=node.getAttributes();
for(int i=0;i<namedNodeMap.getLength();i++){
Node attrNode=namedNodeMap.item(i);
System.out.println(attrNode.getNodeName()+":"+attrNode.getFirstChild().getNodeValue());
}
}
public static void main(String[] args) {
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
try {
DocumentBuilder builder=factory.newDocumentBuilder();
Document doc=builder.parse("src/emp.xml");
NodeList nodeList=doc.getElementsByTagName("emps");
Element element=(Element)nodeList.item(0);
NodeList studentsNodeList=element.getElementsByTagName("emp");
for(int i=0;i<studentsNodeList.getLength();i++){
Element e=(Element)studentsNodeList.item(i);
System.out.println("姓名:"+e.getElementsByTagName("empName").item(0).getFirstChild().getNodeValue());
printNodeAttr(e.getElementsByTagName("empName").item(0));
System.out.println("职位:"+e.getElementsByTagName("job").item(0).getFirstChild().getNodeValue());
System.out.println("地址:"+e.getElementsByTagName("addr").item(0).getFirstChild().getNodeValue());
System.out.println("================");
}
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
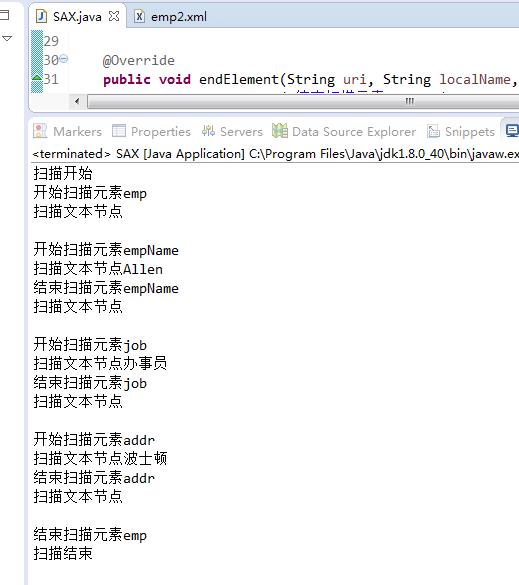
SAX 方式解析XML
<?xml version="1.0" encoding="UTF-8"?> <emp> <empName empNo="10050">Allen</empName> <job>办事员</job> <addr>波士顿</addr> </emp>
package com.zhiqi.test;
import java.io.IOException;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class SAX extends DefaultHandler{
@Override
public void startDocument() throws SAXException {
System.out.println("扫描开始");
}
@Override
public void endDocument() throws SAXException {
System.out.println("扫描结束");
}
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
System.out.println("开始扫描元素"+qName);
}
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
System.out.println("结束扫描元素"+qName);
}
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
System.out.println("扫描文本节点"+new String(ch,start,length));
}
public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException {
SAXParserFactory factory=SAXParserFactory.newInstance();
SAXParser parser=factory.newSAXParser();
parser.parse("src/emp2.xml", new SAX());
}
}
aaa
以上是关于XML引入,DOM 方式解析XML 原理,SAX 方式解析XML的主要内容,如果未能解决你的问题,请参考以下文章