Spark安装
Posted 踏叶乘风
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark安装相关的知识,希望对你有一定的参考价值。
spark的安装
-
先到官网下载安装包
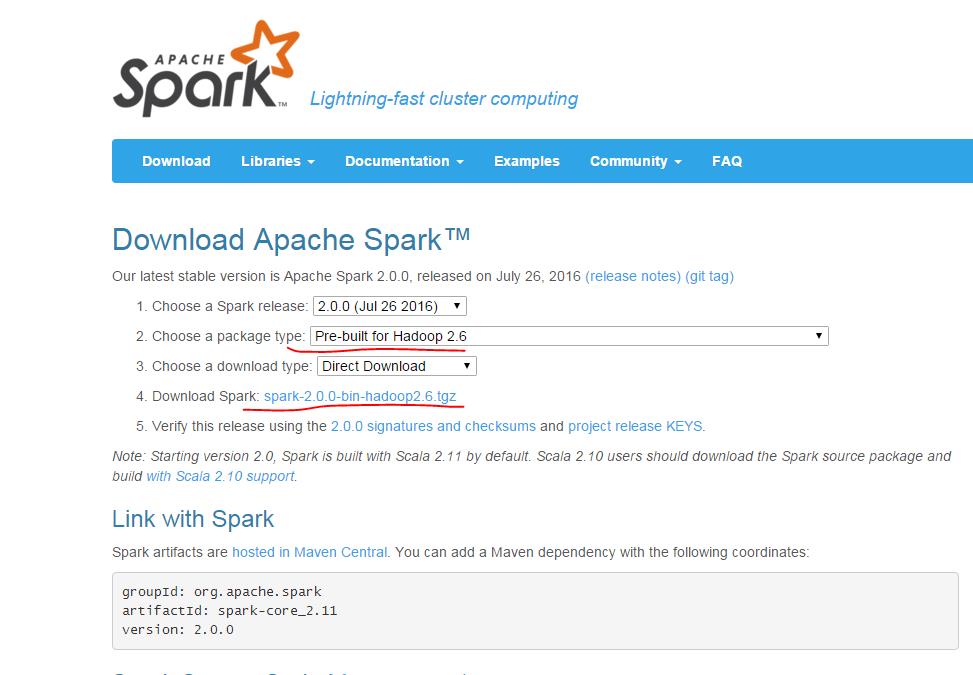
注意第二项要选择和自己hadoop版本相匹配的spark版本,然后在第4项点击下载。若无图形界面,可用windows系统下载完成后传送到centos中。
本例中安装文件的存放目录为:/home/demo/src
注:这里的demo为安装大数据系统工具的专用账号。
-
安装spark
解压压缩包
cd /home/demo/bd tar -zxf /home/demo/src/spark-2.1.0-bin-hadoop2.7.tgz
mv ./spark-2.1.0-bin-hadoop2.7/ ./spark
-
配置spark
安装后,需要在 ./conf/spark-env.sh 中修改 Spark 的 Classpath,执行如下命令拷贝一个配置文件:
cd conf
mv spark-env.sh.template spark-env.sh
编辑 spark-env.sh(vim spark-env.sh) ,在最后面加上如下一行:
export SPARK_DIST_CLASSPATH=$(/home/demo/bd/hadoop/bin/hadoop classpath)
括号里的是hadoop的安装目录
-
spark的简单使用
在 ./examples/src/main 目录下有一些 Spark 的示例程序,有 Scala、Java、Python、R 等语言的版本。我们可以先运行一个示例程序 SparkPi(即计算 π 的近似值),执行如下命令:
cd /home/demo/bd/spark
./bin/run-example SparkPi
执行时会输出非常多的运行信息,输出结果不容易找到,可以通过 grep 命令进行过滤(命令中的 2>&1 可以将所有的信息都输出到 stdout 中,否则由于输出日志的性质,还是会输出到屏幕中):
cd /home/demo/bd/spark
./bin/run-example SparkPi 2>&1 | grep "Pi is roughly"
过滤后的运行结果如下图所示,可以得到 π 的 近似值 :

如果是Python 版本的 SparkPi, 则需要通过 spark-submit 运行:
./bin/spark-submit examples/src/main/python/pi.py
5.spark的交互模式
a.启动spark shell
Spark shell 提供了简单的方式来学习 API,也提供了交互的方式来分析数据。Spark Shell 支持 Scala 和 Python,本文中选择使用 Scala 来进行介绍。
Scala 是一门现代的多范式编程语言,志在以简练、优雅及类型安全的方式来表达常用编程模式。它平滑地集成了面向对象和函数语言的特性。Scala 运行于 Java 平台(JVM,Java 虚拟机),并兼容现有的 Java 程序。
Scala 是 Spark 的主要编程语言,如果仅仅是写 Spark 应用,并非一定要用 Scala,用 Java、Python 都是可以的。使用 Scala 的优势是开发效率更高,代码更精简,并且可以通过 Spark Shell 进行交互式实时查询,方便排查问题。
cd /home/demo/bd/spark
./bin/spark-shell
b.spark shell使用小例子
Spark 的主要抽象是分布式的元素集合(distributed collection of items),称为RDD(Resilient Distributed Dataset,弹性分布式数据集),它可被分发到集群各个节点上,进行并行操作。RDDs 可以通过 Hadoop InputFormats 创建(如 HDFS),或者从其他 RDDs 转化而来。
我们从 ./README 文件新建一个 RDD,代码如下(本文出现的 Spark 交互式命令代码中,与位于同一行的注释内容为该命令的说明,命令之后的注释内容表示交互式输出结果):
val textFile = sc.textFile("file:///usr/local/spark/README.md")

代码中通过 “file://” 前缀指定读取本地文件。Spark shell 默认是读取 HDFS 中的文件,需要先上传文件到 HDFS 中,否则会报错。
RDDs 支持两种类型的操作
actions: 在数据集上运行计算后返回值
transformations: 转换, 从现有数据集创建一个新的数据集
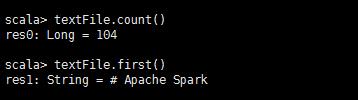
下面我们就来演示 count() 和 first() 操作:
textFile.count() // RDD 中的 item 数量,对于文本文件,就是总行数 textFile.first() //RDD 中的第一个 item,对于文本文件,就是第一行内容
接着演示 transformation,通过 filter transformation 来返回一个新的 RDD,代码如下:
val linesWithSpark = textFile.filter(line => line.contains("Spark")) // 筛选出包含 Spark 的行 linesWithSpark.count() // 统计行数

action 和 transformation 可以用链式操作的方式结合使用,使代码更为简洁:
textFile.filter(line => line.contains("Spark")).count() // 统计包含 Spark 的行数

以上是关于Spark安装的主要内容,如果未能解决你的问题,请参考以下文章