Web 开发后端缓存思路
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Web 开发后端缓存思路相关的知识,希望对你有一定的参考价值。
数据写入缓存:
在数据库与服务端之间利用 redis
这是一个很常见的场景。比如文章的浏览数,每次文章被浏览时,浏览数都 +1。如果每次都回写数据库,不免数据量太大。加上数据库看似简单,其实做了不少关于一致性(请看官了解一下所谓【一致性】,【base】,【acid】)的检查。 而同时,浏览数并不要求保证一致性,只要大概准确就行了。 所以这时候,我们可以先将浏览数写入 redis,满足一定条件后,再回写数据库。 比如,在 controller 中,让每次浏览都在 redis 上 +1,+1 完成后,检查浏览数是否除以 10 后余数为 0(count % 10 === 0),是的话,则回写数据库,并将缓存置为 0。
缓存过期策略
可以通过过期时间来控制内容新鲜期
那么就设置设缓存过期时间。比如在一个网站上,总会有一些每日之星用户,或者今日推荐文章。
这些内容的新鲜期都很长,比如每日之星的数据,如果 20 分钟更新一次,用户也不会有异议。那么,我们在查询出这些用户后,可以将结果集存入缓存中,并设置过期时间为 20 分钟。待自动失效后,再重新查询。
无法通过过期时间来控制内容新鲜期
这时,又有两个策略了。一个是【主动过期】策略,一个是【被动过期】策略。比如想要缓存一篇文章的内容 html,但文章的页面中包含了评论信息。一些老文章被大量访问而无人添加评论时,缓存的效果杠杠的。但一些近期文章会被用户添加评论, 我们无法判断用户何时会添加评论,所以无法得到一个最佳实践的文章过期时间。
主动过期
顾名思义,主动地去 delete 缓存。还是上面的文章例子。我们可以在评论的 model 中,设置一个回调逻辑。每当评论被更新时,同时去删除评论所对应的文章的缓存内容。
被动过期
被动过期也不是完全不需要回调逻辑,只是相对主动过期来说。它不必理解缓存层的存在。
还是上面的例子,当我们缓存一个文章页面时,不仅以文章的 id 为 cache key,还在 cache key 中拼入文章的 update_at 字段。 当评论更新时,让评论去 touch 一下对应的文章,更新文章的最后修改日期。那么当用户再次访问文章时,由于 cache key 变动,过期的内容就不会被展现,从而实现了被动过期。
同样的例子还有,一篇文章是以 markdown 写成,每次输出的时候,都要进行 markdown 渲染,这是个耗时操作。于是我们可以将 ‘markdown_result_‘ + artical.id + artical.updated_at 作为 key,来缓存 markdown 的渲染结果。每当文章更新时,被动地废弃旧有的缓存结果。
当然,这里不能说主动过期好,还是被动过期好。细心的看客也许在上面两个例子中发现了问题,那就是,当文章的内容没有进行改变,而评论添加时,文章却要重新渲染 markdown,可渲染结果其实是一样的。
HTML 片段缓存
resource: https://ruby-china.org/topics/21488
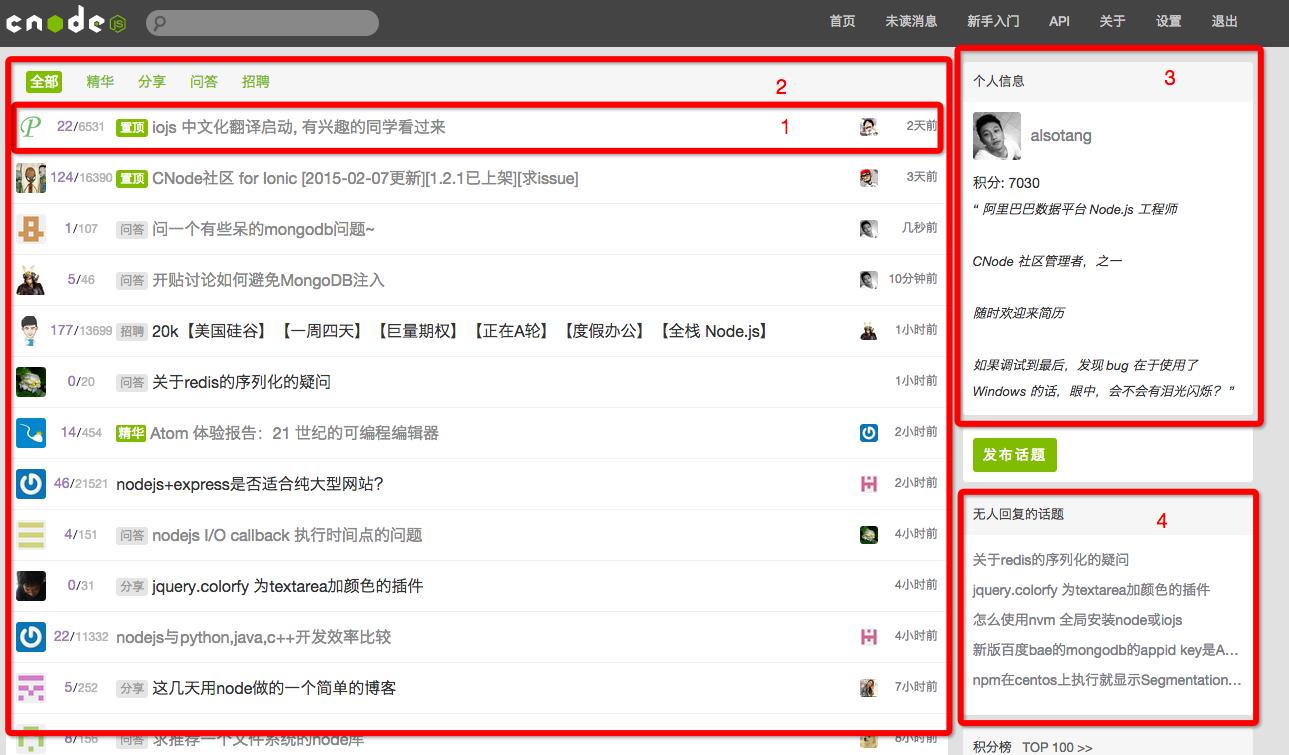
以 CNode 为例,我简单地划分了 1 2 3 4 四个部分。每个部分在逻辑上都是一个相对独立的 setion,它们使用不同的数据进行渲染。在代码组织上,这些部分也是属于不同的 view 文件来负责。
4 的部分就是我们所说的,可以通过过期时间来管理的片段。这个部分 10 分钟更新一次没有问题。
3 的部分类似上面 markdown 的例子,渲染是耗时的,而数据是经常不变的。所以我们可以通过类似 ‘user_profile‘ + user.id + user.updated_at 的 cache key 来将其缓存。
而 1 和 2 的部分,就类似上面【被动过期】的例子。1 中,不仅有帖子的标题,还有帖子的作者信息,还有帖子的最后回复者信息,粗略一算,这都是 3 条查询。如果能缓存起来,那是大大滴有用。而 2,包含了所有 1 类似的部分,也可以被缓存。但如果 1 动了,2 怎么办?所以在缓存 2 时,我们可以使用所有 1 中最新的那个帖子的更新时间来作为 key,当有帖子更新后,更新时间对不上,缓存就被动过期了。
如果是个大型站点,1 的内容频繁动,那么会导致 2 的缓存命中率很低。这时,从业务上,我们判断,主页的新鲜期是可以在 5s 内不变的。这时,缓存策略可以改为,最新的帖子的更新时间,如果离现在的时间不超过 5s,则返回之前缓存的内容。我们一下就从【被动过期】的策略,变回【过期时间】的策略了。
所以具体采用什么策略,根据业务场景可以灵活选择。
【被动过期】策略时,切记要让上层片段的缓存 key 可以被下层 touch 更新。【过期时间】策略时,需要我们判断一下内容的新鲜期。
并且有一点比较深入的知识点是,不同的 touch 策略,会对缓存命中率产生影响。这个知识点请参照本小节 resource 部分的链接去看看 Tower 在面对这个情况时的方案。
如果你要问我 CNode 在片段缓存上是怎么选择的,我可以负责任并潇洒地告诉你:目前没有这方面的缓存~~~~
说起来啊,一是访问量比较小,懒得做。二是,从技术上说,渲染是同步的,而在 Node.js 中,数据查询是异步的。我思考了一下,做这个片段缓存不是简单的事情。而 Rails 中做起来就简单多了,虽然玩 Node 的人总是觉得 Node 可以原生异步并发取数据是一件优越的事情。但同步 io 模型在这个地方带来的好处就是【惰性求值】 。Rails 在渲染时,可以判断一下到底是【查询 + 渲染】还是【直接取缓存】。而 Node 由于异步查询和同步渲染之间的冲突,要解决这个问题,必须有个方便地支持异步渲染的模板方案出现。
last_modified 和 etag
resource: http://robbinfan.com/blog/13/http-cache-implement
这节我们讨论的是静态页面在浏览器中的缓存思路。所以不是 max-age 和 cache-control 那套针对静态资源的方案,而是 last_modified 和 etag 这一套。
上面的内容,一直在说数据库,缓存数据库。但有一点不可忽视的是,浏览器中其实也缓存了我们页面的副本,这部分的缓存,也应该有效地利用起来。 最简单利用方式,就是让服务器判断一下最终页面生成的 etag 与浏览器 header 中传来的 etag 是否相同的,相同的话,则返回 304,省去网络传输的带宽开销。
注意,最简单的方式是判断最终内容生成的 etag!其实我们可以自定义 etag。在这里,etag 也可以理解成一定意义上上述的 cache key,只是这回,储存介质变成了用户的浏览器。
还是上面那个文章内容页面的例子,我们文章页面由 文章内容 + 评论 内容决定是否缓存。这时,我们可以把文章内容的更新时间和最新评论的更新时间拼成一个 etag,返回给用户。下次用户再访问时,如果 etag 对得上,服务端根本都不需要再去缓存数据库中取 HTML 片段数据,直接告诉用户一个 304,【内容与上次一样,没变化】。这时浏览器就直接从自己的缓存中取出页面进行展示了。既节省了宽带占用,又节省了查询开销。
etag as cookie
这里说点题外话,etag 在一定意义上是可以拿来当 cookie 用的。首先我们要了解,浏览器针对每一个 url(包括 querystring 部分)都可以存储一个 etag 值。
比如我是一个广告服务商,我的广告页面是 https://cnodejs.org/ads。每当不同的用户访问这个页面时,我都根据大数据黑魔法定位到这个匿名用户到底是谁,然后返回他感兴趣的内容。可如果用户禁用了 cookie 的话,我该怎么定位用户呢?这时候可以使用 etag。每当用户不带 etag 访问时,都生成一个不冲突的 etag 给它,那么下次他再访问我 url 时,etag 就回来了。
以上是关于Web 开发后端缓存思路的主要内容,如果未能解决你的问题,请参考以下文章