神经网络模型种类
Posted 把全盛的爱都活过
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了神经网络模型种类相关的知识,希望对你有一定的参考价值。
神经网络模型种类
一般地,CNN的基本结构包括两层,其一为特征提取层,每个神经元的输入与前一层的局部接受域相连,并提取该局部的特征。一旦该局部特征被提取后,它与其它特征间的位置关系也随之确定下来;其二是特征映射层,网络的每个计算层由多个特征映射组成,每个特征映射是一个平面,平面上所有神经元的权值相等。特征映射结构采用影响函数核小的sigmoid函数作为卷积网络的激活函数,使得特征映射具有位移不变性。此外,由于一个映射面上的神经元共享权值,因而减少了网络自由参数的个数。卷积神经网络中的每一个卷积层都紧跟着一个用来求局部平均与二次提取的计算层,这种特有的两次特征提取结构减小了特征分辨率。
CNN主要用来识别位移、缩放及其他形式扭曲不变性的二维图形。由于CNN的特征检测层通过训练数据进行学习,所以在使用CNN时,避免了显示的特征抽取,而隐式地从训练数据中进行学习;再者由于同一特征映射面上的神经元权值相同,所以网络可以并行学习,这也是卷积网络相对于神经元彼此相连网络的一大优势。卷积神经网络以其局部权值共享的特殊结构在语音识别和图像处理方面有着独特的优越性,其布局更接近于实际的生物神经网络,权值共享降低了网络的复杂性,特别是多维输入向量的图像可以直接输入网络这一特点避免了特征提取和分类过程中数据重建的复杂度。(http://www.36dsj.com/archives/24006 )
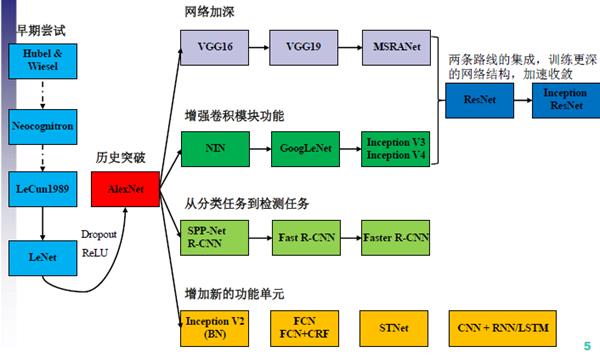
可以说,2012年CNN在ImageNet竞赛中的表现直接奠定了它的重要地位,两个第一,正确率超出第二近10%,确实让人大跌眼镜,掀起了人们对深度学习技术研究的狂潮。从此,深度学习在人脸识别、物体检测、图像分割、光学字符识别等计算机视觉领域发挥了巨大的作用。随着卷积神经网络模型在众多应用领域所取得重要的突破,越来越多的卷积网络模型出现在大家的视野中。(北医补充材料)
(http://blog.csdn.net/u010402786/article/details/52433324 )
http://blog.csdn.net/qiaofangjie/article/details/16826849(CSDN:LeNet-5参数的个人理解)
http://yann.lecun.com/exdb/lenet/index.html(LeNet-5效果与Paper)
卷积神经网络是近年发展起来,并引起广泛重视的一种高效识别方法。20世纪60年代,Hubel和Wiesel在研究猫脑皮层中用于局部敏感和方向选择的神经元时发现其独特的网络结构可以有效地降低反馈神经网络的复杂性,继而提出了卷积神经网络(Convolutional Neural Networks-简称CNN)。现在,CNN已经成为众多科学领域的研究热点之一,特别是在模式分类领域,由于该网络避免了对图像的复杂前期预处理,可以直接输入原始图像,因而得到了更为广泛的应用。

第一个被正式提出来的卷积网络模型Lenet-5
LeCun,文章《Gradient-based learning applied to document recognition》,引用量4832次。 (http://blog.csdn.net/sunfoot001/article/details/51126360 )
(http://www.ithao123.cn/content-8359874.html )
vgg和googlenet是2014年imagenet竞赛的双雄,这两类模型结构有一个共同特点是更深的网络结构。VGG-Net同样也是一种CNN,它来自 Andrew Zisserman 教授的组 (Oxford),VGG-Net 在2014年的 ILSVRC localization and classification 两个问题上分别取得了第一名和第二名,VGG-Net不同于AlexNet的地方是:VGG-Net使用更多的层,通常有16-19层,而AlexNet只有8层。虽然,随着网络层数的增加,网络模型的准确率有所提升,但是,通过加深卷积层数也已经到达准确率提升的瓶颈了。(http://blog.csdn.net/sunbaigui/article/details/46713483 )
直到GoogLeNet出来之前,主流的网络结构突破大致是网络更深(层数),网络更宽(神经元数)。以大家调侃深度学习为"深度调参",但是纯粹的增大网络的缺点:1.参数太多,容易过拟合,若训练数据集有限;2.网络越大计算复杂度越大,难以应用;3.网络越深,梯度越往后穿越容易消失(梯度弥散),难以优化模型。(http://blog.csdn.net/u010402786/article/details/52433324 )
GoogLeNet除了增加了网络的深度之外,更增加了网络的宽度,增加了卷积模块的数量。通过增加不同尺度的卷积模板,增加了网络对于不同尺度的适用性。在池化(max pooling)层后,卷积层前,分别加上了1x1的卷积核起到了降低特征图厚度的作用,降低了计算的复杂度。(http://blog.csdn.net/u010402786/article/details/52433324 )
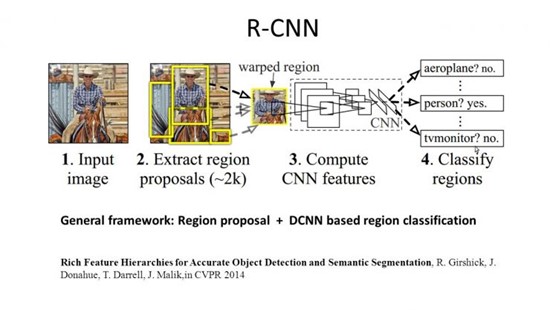
R-CNN
网络模型的另外一个发展方向就是从单纯的分类任务扩展到其他形式的任务。目标分割,应该是Target Segmentation,应该是data/image segmentation的一种。这里假定数据是图像,就如楼上说的,任务是把目标对应的部分分割出来。对于一般的光学图像而言,分割像素是一个比较常见的目标,就是要提取哪一些像素是用于表述已知目标的。2014年的Region CNN算法,基本思想是首先用一个非深度的方法,在图像中提取可能是物体的图形块,然后深度学习算法根据这些图像块,判断属性和一个具体物体的位置。(https://www.zhihu.com/question/36500536/answer/67957864 )
Faster R-CNN
在15年提出一种Faster R-CNN方法,一个超级加速版R-CNN方法。它的速度达到了每秒七帧,即一秒钟可以处理七张图片。除了在目标检测任务中的发展,在面对更加广泛和复杂的任务如目标跟踪、目标匹配等,深度神经网络都有很强的发展潜力。(放射学影像处理调研)
FCN
除了面对不同的任务之外,神经网络中还可以添加不同的功能模块。CVPR 2015拿到best paper候选的论文。FCN对图像进行像素级的分类,从而解决了语义级别的图像分割(semantic segmentation)问题。与经典的CNN在卷积层之后使用全连接层得到固定长度的特征向量进行分类(全联接层+softmax输出)不同,FCN可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的feature map进行上采样, 使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息, 最后在上采样的特征图上进行逐像素分类。(http://www.cnblogs.com/gujianhan/p/6030639.html )
在现在,卷积神经网络的模型已经是五花八门,但是,从最根本上来讲,无论神经网络的如何变化,其最终目标一定是要更加准确、快速地处理更多的任务。
ResNet
以上是关于神经网络模型种类的主要内容,如果未能解决你的问题,请参考以下文章