正则引擎在数据包匹配中的工程分析
Posted broler
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正则引擎在数据包匹配中的工程分析相关的知识,希望对你有一定的参考价值。
匹配
常见的通用匹配算法有字符串匹配和正则匹配。字符串匹配常见的算法有Boyer-Moore算法、orspool算法、unday算法、MP算法、R算法、AC自动机。Boyer-Moore、Horspool、Sunday算法都是基于后缀数组的匹配算法,区别在于移动的方式不一样。MP是前缀匹配算法,R算法是hash匹配,AC自动机可以同时匹配多个pattern。正则匹配有两种NFA和DFA,都是基于有穷自动机。NFA支持回朔,DFA的效率比NFA高很多,但支持的情况受限。
正则引擎
正则引擎包括NFA和DFA两种。两种都是基于有穷自动机,DFA是NFA的一种极限形式。
有穷自动机
有穷自动机(Finite Automate)是用来模拟实物系统的数学模型,它包括如下五个部分:
有穷状态集States
输入字符集Input symbols
转移函数Transitions
起始状态Start state
接受状态Accepting state(s)
下图为一台有穷自动机
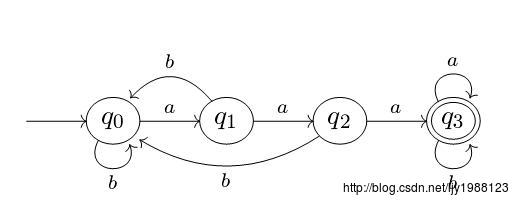
可以看到,该自动机包含四个状态q0, q1, q2, q3,两个输入字符a, b,转移函数如图所示,起始状态为q0,接受状态为q3。
有穷自动机,按照转移函数的不同,又可分为确定型有穷自动机(Determinism Finite Automate, DFA),与非确定型有穷自动机(Non-determinism Finite Automate, NFA)。
非确定有穷自动机容许转移函数不确定,换句话说,对任意状态,输入任意一个字符,可以转移到0个,1个或者多个状态。
下图是一台非确定有穷自动机,可以看到,对状态q0输入字符a,既可以转移到q0,也可以转移到q1,这就是“非确定”的意义所在。

对某个自动机来说,如果从起始状态,接受一系列输入字符,可以转移到接受状态,即认为这一系列字符可以被自动机接受。
如果两台自动机能够接受的输入字符串(或者叫做“正则语言”Regular Language)完全相同,则这两台自动机是等价的。可以证明,对于每一个非确定有穷自动机,都存在与之等价的确定型有穷自动机(证明略)。
正则表达式就是建立在自动机的理论基础上的:用户写完正则表达式之后,正则引擎会按照这个表达式构建相应的自动机(可能是NFA,也可能是DFA,但它们必定是等价的),若输入一串文本之后,自动机抵达了接受状态,则这串文本可以“匹配”用户指定的正则表达式。
下面是同一个正则表达式 a|ab 对应的NFA和DFA。其中双圆表示可行的结束状态,可以看到NFA中在第一个分支表示了两条路径或的关系,而DFA则是一条路径可以在两个点结束都算匹配。
NFA

DFA

在 Mastering Regular Expression中,Friedl首先分析了NFA和DFA的区别,DFA比较快,但不提供Backtrack(回溯)功能,NFA比较慢,但提供了Backtrack功能。
传统的NFA匹配算法是带回溯的深度优先搜索(backtracking depth-first search,就是上文所说的Regex-Based过程),而新的PCRE算法提供了效率更高的广度优先搜索,可以同时保持所有可能的NFA状态(请参考 http://www.cl.cam.ac.uk/Teaching/current/RLFA/,尤其是Lecture Notes的section 2.2)。
但即使应用PCRE算法,NFA的速度仍然低于DFA,这是由NFA需要同时保存多种可能的性质决定的。从理论上说,如果我们不需要应用 Backtrack,完全可以从NFA构造出等价的DFA,再进行匹配,这样能大大提高速度——代价是,DFA需要更多的空间。
NFA匹配的过程就是吃入字符,尝试匹配,如果通过,再吃入尝试;如果不通过,就吐出,回到上一个状态,因为同一个字符串在正则中可能存在一种状态不同转化路径,这时正则引擎换一个转化状态进行尝试,如果通过,继续吃入字符,否则继续吐出字符,回到再上一个状态。这种尝试不成功就返回上一状态的过程,我们称为回溯。正则匹配的性能好坏,就看回溯的情况,回溯越多,性能越差。而DFA就是一条路走到黑。所以,凡是在正则中需要引用之前的变量的特性都属于NFA,例如捕获组,引用。正则表达式的大部分性能问题都是出于回溯,一般的高效正则都是尽量减少回溯的。
常见的工业引擎种类
l 经典NFA:就是搜索加回溯的方式,搜索到第一个match就退出。经典NFA的空间复杂度(即状态数和转移数)是O(m),但匹配的时间复杂度最坏情况下是指数级的,即O(2^n)。
l POSIX NFA: 和传统NFA差不多,不同是只有找到最长的match才会退出,所以理论上会比经典NFA更慢。C的regex库就是POSIX NFA。
l Thompson NFA:上个世纪60年代,由Ken Thompson提出,空间复杂度仍然是O(m),但匹配的时间复杂度可以降到O(nm), 算法可以参考Regular Expression Matching: the Virtual Machine Approach。当然构造NFA的方法还有很多,比如Glushkov NFA,这里不一一列举了
l DFA:NFA和DFA的表达能力有等价的,而且任何一个NFA都可以转化为一个DFA。DFA匹配的时间复杂度是线性的,即O(n), 但因为对于某些复杂的正则表达式,会导致DFA的状态爆炸,所以最坏情况下,转化需要的空间复杂度和时间复杂度是O(2^m)。可见相比NFA,DFA算是用空间来换时间了。有的引擎,例如yara,处于效率考虑就会自己建立专用正则引擎,这种引擎一般是不支持很多NFA回溯特性。其目的就是为了效率。
DFA对于文本串里的每一个字符只需扫描一次,比较快,但特性较少;NFA要翻来覆去吃字符、吐字符,速度慢,但是特性丰富,所以反而应用广泛。当今主要的正则表达式引擎,如Perl、Ruby、Python的re模块、Java和.NET的regex库,都是NFA的。只有NFA支持lazy、backtracking、backreference,NFA缺省应用greedy模式,NFA可能会陷入递归险境导致性能极差。
DFA只包含有穷状态,匹对相配过程中无法捕获子表达式(分组)的匹对相配结果,因此也无法支持backreference。DFA不能支持捕获括号和反向引用。一般来说,DFA的速度与正则表达式无关,而NFA中两者直接相关。
正则库对比
目前使用DFA引擎的程序主要有:awk,egrep,flex,lex,mysql,Procmail等;
使用传统型NFA引擎的程序主要有:GNU Emacs,Java,less,more,.NET语言,PCRE library,Perl,php,Python,Ruby,sed,vi,boost
使用POSIX NFA引擎的程序主要有:mawk,Mortice Kern System utilities,GNU Emacs(使用时可以明确指定);
也有使用DFA/NFA混合的引擎:GNU awk,GNU grep/egrep,Tcl,pcre扩展。GNU grep采取了一种简单但有效的策略。它尽可能多地使用DFA,在需要反向引用的时候,才切换到NFA。GNU awk的办法也差不多——在进行“是否匹配”的检查时,它采用GNU grep的DFA引擎,如果需要知道具体的匹配文本的内容,就采用不同的引擎。这里的“不同的引擎”就是NFA,利用自己的gensub函数,GNU awk能够很方便地提供捕获括号。
C/C++/boost正则库对比:
http://www.cnblogs.com/pmars/archive/2012/10/24/2736831.html
业内知名正则库对比:PCRE/PCRE-DFA/TRE/ Onig-uruma/RE2/ PCRE-JIT
http://sljit.sourceforge.net/regex_perf.html
我们可以看到在匹配不同类型的字符串时,各种算法的效率是不同的,甚至windows还是linux对匹配效率也是有影响的。
http://sljit.sourceforge.net/pcre.html
现代的正则库大都会同时融合一个NFA和DFA的特点,有的甚至针对不同的应用进行优化。例如PCRE又有POSIX NFA(默认),又有PCRE-DFA,还有PCRE-JIT,谷歌的RE2实现了几乎所有Perl和PCRE特点,和语法糖,有一个POSIX模式,仅接受POSIX egrep算子。
其中RE2是DFA类型,也是golang的默认正则引擎。
PCRE是一个轻量级的函数库,比Boost之中的正则表达式库小得多。PCRE十分易用,同时功能也很强大,性能超过了POSIX正则表达式库和一些经典的正则表达式库。
和Boost正则表达式库的比较显示,双方的性能相差无几,PCRE在匹配简单字符串时更快,Boost则在匹配较长字符串时胜出。PCRE被广泛使用在许多开源软件之中,最著名的莫过于Apache HTTP服务器和PHP脚本语言、R脚本语言,此外,正如从其名字所能看到的,PCRE也是perl语言的缺省正则库。
sregex是openresty项目下专为大数据流匹配定制的正则引擎,借鉴pcre,但尚未有足够多的产业应用。有待成熟后可以考量其效率。
字符串匹配
Aho-Corasick算法
Aho-Corasick算法又叫AC自动机算法,是一种多模式匹配算法。Aho-Corasick算法可以在目标串查找多个模式串,出现次数以及出现的位置。
Aho-Corasick算法主要是应用有限自动机的状态转移来模拟字符的比较,下面对有限状态机做几点说明:

上图是由多模式串{he,she,his,hers}构成的一个有限状态机:
1.该状态当字符匹配是按实线标注的状态进行转换,当所有实线路径都不满足(即下一个字符都不匹配时)按虚线状态进行转换。
2.对ushers匹配过程如下图所示:

当转移到红色结点时表示已经匹配并且获得模式串
其他厂商
腾讯
腾讯的大眼使用的DFA型正则引擎。对于多数正则表达式都可以直接支持,个别的需要人为去优化正则表达式的编写,实际中完全能满足功能需要。各个规则都需要明确指定应用的请求类型,如GET/POST或者所有类型,以及应用的范围,比如只匹配参数字段,或者全包匹配等。然后对请求类型和应用范围都相同的规则再进行进一步的组合,字符串类型的规则采用AC多模匹配算法一次匹配,而对于正则类型的规则,则从中提取固定的字符串部分,和字符串规则合并进行一次匹配,对于命中固定部分的数据,再去进行正则匹配,以此来减少正则表达式匹配的次数,显著提高规则匹配的效率。匹配流程如下图所示:

intel
intel官方Intel® Open Network Platform Server team有实现一个包过滤器hyperscan,使用PCRE语法,DFA。但是是intel的实现,专门为32-bit or 64-bit Intel® Xeon™ 处理器优化。
这里有一个性能说明。
但是获取不到源代码,网上也几乎没有相关的使用案例,其具体性能和可用性未知。
Wind river
知名系统公司风河(已被intel收购),针对dpdk有发布商用的数据包过滤引擎:content inspection engine。因为intel血统,所以可以看成是官方的dpdk配套内容检测引擎。其关于包过滤的描述与intel官方的hyperscan很像,并且intel有说明hyperscan属于wind river,鉴于两者同源,可以认为是同一个实现。
http://www.windriver.com/products/product-overviews/PO_Wind-River-Content-Inspection-Engine.pdf
选型
所以在通用匹配引擎的选择上,我们与腾讯大眼一致,使用固定字符串(AC多模匹配)+DFA正则引擎的模式。PCRE支持NFA、DFA和jit,开源社区广泛,所以主要使用PCRE库,但RE2在某些情况下明显优于PCRE,所以可以辅助使用RE2库。
由于数据包处理的并行特性,后续可以考虑使用显卡计算CUDA来提高性能。
专用包处理机:BPF
eBPF是内核用于数据包过滤的新型虚拟机,与真实的计算机寄存器直接映射,显著提高效率,并且内嵌在内核网络协议栈数据包处理的各个环节,在内核中进行过滤引擎是不二选择。但是我们使用dpdk在用户端进行过滤,一个很好的思路是是将正则表达式编译成eBPF虚拟代码再进行优化,但是目前没有相关的实现。pcre的jit使用的自己定义的虚拟代码。在用户空间实现eBPF也是有相关的项目:https://github.com/iovisor/ubpf 。但是这主要为测试方便而开发,对于效率没有太多考量,所以eBPF虚拟代码在用户端不应使用。
专门针对数据包过滤的自实现引擎
虽然eBPF的使用被排除,但是其设计思想确实非常有价值的。其前身cBPF会内含特定的数据包的特定位置,只要取相关的变量就可以直接拿到数据包的对应值。而正则引擎由于其通用性,没有专门针对数据包进行优化。最近兴起的使用jit动态运行时优化编译正则代码则也是利用了与具体业务相关的特性来提高效率。
倘若我们抛弃正则的书写,转而使用我们自己专为数据包定义的过滤方式的书写方式,理论上可以做到性能的最优。
总结
对于生产应用,在初始阶段应该使用AC多模匹配与成熟的PCRE-DFA、PCRE-JIT和RE2进行数据包的正则匹配。针对不同的正则表达式择优选择不同的引擎。
后续的提高可以考虑使用CUDA等PCI-E高并行硬件方案来完成AC多模匹配和正则过滤,或者向intel索要hyperscan进行测试看是否可以满足需求,当性能仍然出现瓶颈,应当考虑自己实现专有的数据包过滤引擎。最后才采用自己实现的原因是自己实现的不确定性较多,并且没有对已有的方案的使用经验,难以评价优劣。
以上是关于正则引擎在数据包匹配中的工程分析的主要内容,如果未能解决你的问题,请参考以下文章