《机器学习基石》---Linear Models for Classification
Posted coldyan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《机器学习基石》---Linear Models for Classification相关的知识,希望对你有一定的参考价值。
1 用回归来做分类
到目前为止,我们学习了线性分类,线性回归,逻辑回归这三种模型。以下是它们的pointwise损失函数对比(为了更容易对比,都把它们写作s和y的函数,s是wTx,表示线性打分的分数):

把这几个损失函数画在一张图上:

如果把逻辑回归的损失函数ce做一个适当的放缩,则可以得到下图:
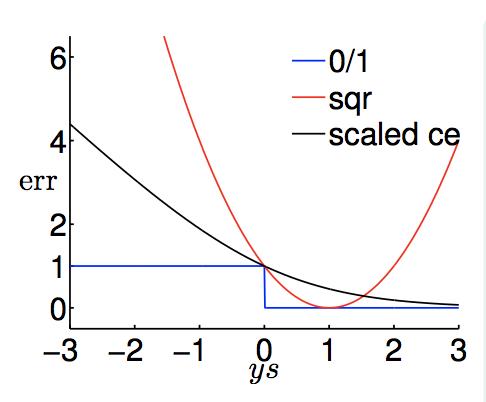
可以看出,平方误差和放缩后的交叉熵误差是0/1误差的上限,这里以放缩后的ce举例,由于对于每个点的error均成立不等式,则不论是对于Ein还是Eout仍然有不等式成立,因为它们是数据集上每个点error的期望:

应用到VCbound,就有:

可以看出,只要把训练集上的交叉熵误差做到低,则就能保证真实的0/1错误也比较低。
因此线性回归和逻辑回归都可以用来做分类:

正如之前在《噪声与错误》一节中所说,我们这里用平方错误或交叉熵错误来代替01错误,作为errhat。
通常,我们会使用线性回归的结果作为逻辑回归,PLA,pocket算法的初始值。
2 随机梯度下降法
(注:课程里面并没有证明为什么SGD能work,直接说这样替代是可行的。)
使用随机选取一个点的梯度来代替真实的梯度,计算代价明显降低,同时能保证效果是近似的。(收敛速度会变慢,因为最快的收敛方向一定是真实的梯度方向)。
PLA和逻辑回归的联系:
当逻辑回归使用SGD时,与PLA形式上很类似,可以看作是一种soft-PLA。因为PLA是要么更新,要么不更新,而使用SGD的逻辑回归则是每次更新一定的值:

注意,对于随机梯度下降法来说,停止的条件一般是足够的迭代次数,而不是看梯度是否为0。否则再去算梯度是否为0,就没有必要用SGD了。
3 用逻辑回归做多元分类
先介绍一种简单的方法,OVA:
要做k元分类,我们相当于对同一个训练数据集训练k个二元逻辑回归模型。训练第k个模型时,标签做一定的修改,类别是k就把标签记为1,不是k就记为-1。
在做预测时,就是对这k个模型都算一遍,选择打分最大的作为预测类别:

上面的算法的一个缺点是,当k很大且每个类别的样本数量均匀时,对每个训练来说就是不均衡的。可以使用下面的算法OVO来解决这个问题:
训练C(k,2)个二分类模型,每个模型训练只使用两个类的数据,显然这样就是均衡的。做预测时,每个模型投票给一个类,最终选用得票数最多的类作为预测结果:

另外一种方法,是使用soft-max回归。事实上,逻辑斯蒂函数是soft-max函数的一个特例。
以上是关于《机器学习基石》---Linear Models for Classification的主要内容,如果未能解决你的问题,请参考以下文章