caffe扩展实验
Posted welcome_home
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了caffe扩展实验相关的知识,希望对你有一定的参考价值。
caffe实现caltech101图像分类
这里讲述如何用自己的数据集,在caffe平台一步步实现的过程[新手参考];
主要分为下面3个环节:
- 数据集准备 Dataset preparation
- caffe网络准备 Caffe network files preparation
- 从零开始训练和微调 From scratch training and finetuning
复制imagenet项目到MyNet,修改内容完成caltech101数据集分类网络
数据集准备:
caltech101(加利福尼亚理工学院101类图像数据库)数据集:
数据集地址: http://www.vision.caltech.edu/Image_Datasets/Caltech101/Caltech101.html
直接下载: 101_ObjectCategories.tar.gz (131Mbytes)
简介:
文件夹包含属于101类别的图片对象,一个文件夹包含一类图片。 每类约40至800张图像。 大多数类别都有大约50张图片。 2003年9月由Fei-Fei Li,Marco Andreetto和Marc\'Aurelio Ranzato收集。 每个图像的大小约为300×200像素。图片总量过8000张。
caffe数据集的创建需要两个文件: train.txt 和 val.txt, 格式为 图片路径+所属类别编号,内容片段如下
... caltech101/windsor_chair/image_0005.jpg 98 caltech101/windsor_chair/image_0023.jpg 98 caltech101/windsor_chair/image_0043.jpg 98 caltech101/wrench/image_0009.jpg 99 caltech101/wrench/image_0018.jpg 99 ...
需要注意的是类别编号从0开始.
下面给出python实现的程序getlist.py,自动生成train.txt和val.txt
import os
root = os.getcwd() #获取当前路径
data = \'caltech101\'
path = os.listdir(root+\'/\'+ data) #显示该路径下所有文件
path.sort()
vp = 0.105 #测试集合取总数据前10%
file = open(\'train.txt\',\'w\')
fv = open(\'val.txt\',\'w\')
i = 0
for line in path:
subdir = root+\'/\'+ data +\'/\'+line
childpath = os.listdir(subdir)
mid = int(vp*len(childpath))
for child in childpath[:mid]:
subpath = data+\'/\'+line+\'/\'+child;
d = \' %s\' %(i)
t = subpath + d
fv.write(t +\'\\n\')
for child in childpath[mid:]:
subpath = data+\'/\'+line+\'/\'+child;
d = \' %s\' %(i)
t = subpath + d
file.write(t +\'\\n\')
i=i+1
file.close()
fv.close()
执行命令生成[在caffe-master/data/目录下执行]
ipython getlist.py
转换成lmdb格式
caffe-master/examples/imagenet目录下create_imagenet.sh可以方便的实现转换,需要简单修改如下配置项
EXAMPLE=examples/MyNet # 指定存储LMDB数据位置
DATA=data/ # 存放train.txt和val.txt文件的文件夹
TRAIN_DATA_ROOT=data/ # train图片文件夹
VAL_DATA_ROOT=data/ # val图片文件夹(一般都同上)
RESIZE=true # 讲所有的图片统一大小
# 下面的代码片段
GLOG_logtostderr=1 $TOOLS/convert_imageset \\
--resize_height=$RESIZE_HEIGHT \\
--resize_width=$RESIZE_WIDTH \\
--shuffle \\
$TRAIN_DATA_ROOT \\
$DATA/train.txt \\
$EXAMPLE/MyNet_train_lmdb
GLOG_logtostderr=1 $TOOLS/convert_imageset \\
--resize_height=$RESIZE_HEIGHT \\
--resize_width=$RESIZE_WIDTH \\
--shuffle \\
$VAL_DATA_ROOT \\
$DATA/val.txt \\
$EXAMPLE/MyNet_val_lmdb
修改完毕之后,执行shell命令,得生成训练和测试的lmdb数据
./examples/MyNet/create_imagenet.sh
结果如下
imagenet/make_imagenet_mean.sh 会根据lmdb文件生成一个均值文件, 修改对应参数来生成二进制均值文件,在运算时可以大大加快运算速度,但不是必须
$TOOLS/compute_image_mean $EXAMPLE/MyNet_train_lmdb \\ # train数据lmdb文件夹路径 $DATA/mean.binaryproto # 保存均值文件的路径
caffe网络文件
caffe网络文件可以根据caffe-master/models/bvlc_reference_caffenet/下的两个文件修改: solver.protoxt 和 train_val.protoxt[DAG网络]
将两个文件拷贝到examples/MyNet目录下,首先修改examples/MyNet/train_caffenet.sh
./build/tools/caffe train \\
--solver=examples/MyNet/solver.prototxt $@
修改solver参数,指向当前目录下的solver.protoxt文件,然后修改solver.protoxt文件内容
net: "examples/MyNet/train_val.prototxt" # 网络文件路径 test_iter: 100 # 迭代n*batch_size需要覆盖所有数据 test_interval: 300 # 每迭代300次后输出测试结果 base_lr: 0.01 lr_policy: "step" gamma: 0.1 stepsize: 100 display: 100 # 每迭代100次训练数据输出一次结果 max_iter: 5000 # 最大迭代次数 momentum: 0.9 weight_decay: 0.0005 snapshot: 4000 snapshot_prefix: "examples/MyNet/caffenet_train" solver_mode: GPU
修改train_val.prototxt文件内容,四项内容, 文件片段如下
name: "CaffeNet"
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: true
crop_size: 60
mean_file: "examples/MyNet/mean.binaryproto" # 01
}
data_param {
source: "examples/MyNet/MyNet_train_lmdb" # 02
batch_size: 256
backend: LMDB
}
}
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
mirror: false
crop_size: 60
mean_file: "examples/MyNet/mean.binaryproto" # 03
}
data_param {
source: "examples/MyNet/MyNet_val_lmdb" # 04
batch_size: 50
backend: LMDB
}
}
从0开始训练和微调
开始训练
./examples/MyNet/train_caffenet.sh
结果[准确率9.7%]
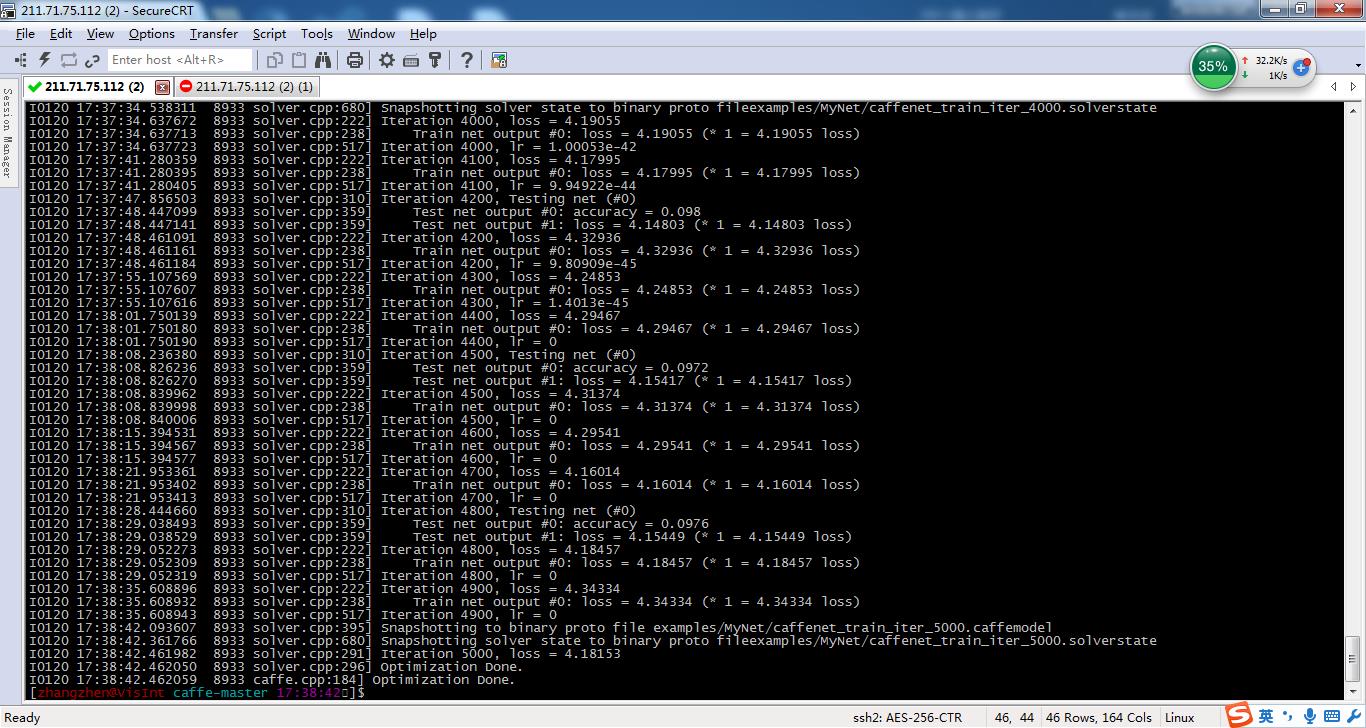
总结:因为训练数据很少,总共8000张左右,其中随机去10%用于测试,只有7000张左右图片可以用来训练,虽然实验现在没有取得理想的结果,但是一步步实验的过程,依旧让人收获很多。
微调
......
未完待续
iiiiiiii
以上是关于caffe扩展实验的主要内容,如果未能解决你的问题,请参考以下文章