Volatile从入门到放弃
Posted w329636271
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Volatile从入门到放弃相关的知识,希望对你有一定的参考价值。
1.引言
如果你对java的volatile有着疑虑请阅读本文,如果你想对volatile想有一个更深的了解,请阅读本文.本文主要讲的是volatile的写happen-before在volatile读之前所涉及相关的原理,以及在Hotspot中相关代码的实现.
首先从一段代码开始讲起,如下
初始化
int a = 0, int b = 0;
void foo(void)
{
a= 1;
b= 1;
}
void bar(void)
{
while (b == 0) continue;
If(a == 1) {
System.out.println(“true”);
};
}
以上的代码,threadA运行foo方法,threadB运行bar方法;在threadB中,能否在while循环跳出之后,即b=1的情况下,得到a一定等于1呢?答案是否定的.因为存在着编译器的乱序和cpu指令的乱序,程序没有按照我们所写的顺序执行.
2.1编译器乱序
编译器是如何乱序的?编译器在不改变单线程语义的前提之下,为了提高程序的运行速度,可以对指令进行乱序.
编译器按照一个原则,进行乱序:不能改变单线程程序的行为.
在不改变单线程运行的结果,以上foo函数就有可能有两种编译结果:
第一种:
a = 1;
b= 1;
第二种:
b = 1;
a = 1;
如上,如果cpu按照第二种编译结果执行,那么就不能正确的输出”true”.虽然乱序了,但是并没有改变单线程threadA执行foo的语义,所以上面的重排是允许的.
2.2.cpu乱序
2.2.1 cpu的结构与cpu乱序: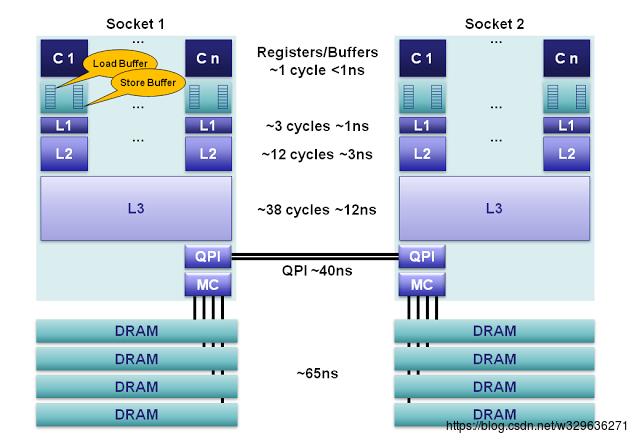
首先来了解一下x86 cpu的结构:
c1,c2,c3 .. cn是160个用于整数和144个用于浮点的寄存器单元,用于存储本地变量和函数参数.cpu访问寄存器的需要1cycle< 1ns,cpu访问寄存器是最快的.
LoadBuffer,storeBuffer合称排序缓冲(Memoryordering Buffers (MOB)),Load缓冲有64长度,store缓冲有36长度.buffer与L1进行数据传输,cpu无须等待.
L1是本地核心内的缓存,被分成独立的32K的数据缓存和32k指令缓存.访问L1需要3cycles ~1ns.
L2缓存是本地核心内的缓存,被设计为L1缓存与共享的L3缓存之间的缓冲,L2缓存大小为256K.访问L2需要12cycles-3ns.
L3:在同插槽的所有核心共享L3缓存,L3缓存被分为数个2M的段,访问L3需要38cycles~12ns.
DRAM:就是我们通常说的内存,访问内存一般需要65ns.
cpu加载不同缓存级别的数据,从上往下,需要的时间是越来越多的,而等待对cpu来说是极大的浪费;对于不同的插槽的cpu所拥有的一级二级缓存是不共享的,而不同的缓存之间需要保证一致性,主要通过MESI协议,为了保证不同缓存的一致性也是需要付出时间的,因为不同状态之间的转换需要等待消息的回复,这个等待过程往往是阻塞的.
根据MESI协议,变量要从S状态变为M状态,本cpu要执行read andmodify ,需要发出Invalidate消息,然后等待,待收到所有其它cpu的回复之后才执行更新状态,其他操作也是如此,都有会等待的过程。这些过程都是阻塞的动作,无疑会给cpu的性能带来巨大的损耗。
经过不断地改进,在寄存器与cache之间加上loadbuffer、storebuffer,来减小这些阻塞的时间。cpu要读取数据时,先把读请求发到loadbuffer中,无需等待其他cpu的响应,就可以先进行下一步操作。直到其他cpu的响应结果达到之后,再处理这个读请求的结果。cpu写数据时,就把数据写到storebuffer中,此时cpu认为已经把数据写出去了,待到某个适合的时间点(cpu空闲时间),在把storebuffer的数据刷到主存中去。
根据以上的描述,可知在storebuffer中的数据有临时可见性问题。即在storebuffer中的数据对本cpu是可见的(本cpu读取数据时,可以直接从storebuffer中进行读取),其它槽的cpu对storebuffer中的数据不可见。loadbuffer中的请求无法取到其他cpu修改的最新数据,因为最新数据在其他cpu的storebuffer中。同时,在loadbuffer、storebuffer中的"请求"的完成都是异步的,即表现为它们完成的顺序是不确定的,指令的乱序。
2.2.2 cpu乱序
cpu乱序的一种情况:
Processor 0
Processor 1
mov [ _x], 1
mov [ _y], 1
mov r1, [ _y]
mov r2, [_x]
Initially x == y == 0
解释一下:x,y表示内存中的变量,r1,r2表示寄存器, mov [_x],1,表示把1赋值给x变量,从顺序执行的角度来说,结果肯定是r1=1,或r2 =1;然而r1=0并且r2=0是存在的.
cpu实际执行的情况可能如下
Processor 0
Processor 1
mov r1, [ _y] // (1)
mov r2, [_x] // (2)
mov [ _x], 1 // (3)
mov [ _y], 1 // (4)
如上(1),(2),(3),(4)的顺序执行,便会得到r1=0,r2=0.可以这么理解,大部分的处理器,在保证单线程执行语义正确的基础上,会根据一定的规则对指令进行重排.
为什么会出现上面的情况?
因为cpu会将写放入storebuffer中,然后立刻返回不会等待,会将读放入load buffer中,然后立刻返回,这两个队列都是异步的,他们写读的是不同地址,不存在依赖,两者谁先完成是不知道的,如果读指令先完成了,就出现上面的重排的情况.
3. 编译器屏障与内存屏障
由于存在着编译器对程序指令的重排,这个需要编译器屏障来保证程序的正确执行,cpu也会对指令进行重排,这个需要内存屏障来保证.所以屏障需要对编译器和内存同时起作用,来保证程序可以正确执行.
因为我们大部分的软件主要都是在x86_linux上运行的,所以我们主要研究的是x86的相关编译器屏障和内存屏障.
3.1 编译屏障
Open jdk9中x86_linux的栅栏指令编写如下:
static inline void compiler_barrier() {
__asm__ volatile ("" : : : "memory"); /*编译器屏障*/
}
此处 __asm__ volatile("" : : : "memory"); 是内嵌汇编.
解释:
__asm__ :代表汇编代码开始.
__volatile__:禁止编译器对代码进行某些优化.
memory: memory代表是内存;这边用”memory”,来通知编译器内存的内容已经发生了修改,要重新生成加载指令(不可以从缓存寄存器中取).因为存在着内存的改变,不可以将前后的代码进行乱序.
asm volatile("" :::"memory"),这句内嵌汇编作为编译器屏障,可以防止编译器对相邻指令进行乱序,但是它无法阻止CPU的乱序;也就是说它仅仅禁止了编译器的乱序优化,不会阻止CPU的乱序执行。
以下利用asm volatile("" ::: "memory")来验证,对于屏障之后的读,都是读取的主存,而不是从寄存器中读取的.当然如果您不懂汇编和c++这部分您可以跳过.
实验一:
#include <stdio.h> int foo = 10; int bar = 15; int main(void) { int ss = foo + 1; __asm__ __volatile__("":::"memory"); int foo1 = foo + 2; printf("ss=%d\\n", ss); printf("foo1=%d\\n", foo1); return0; }
编译命令:
g++ -S -O2 test1.cpp
编译结果的部分汇编:
main:
.LFB30:
.cfi_startproc
movl foo(%rip), %eax //将foo变量从内存加载到寄存器eax中
pushq %rbx
.cfi_def_cfa_offset 16
.cfi_offset 3, -16
leal 1(%rax), %edx //将rax变量加1赋值给edx寄存器也是ss变量. //rax是64位寄存器,它的低32位是eax寄存器.
movl foo(%rip), %eax//将foo变量从内存加载到寄存器eax中
movl $.LC0, %esi
movl $1, %edi
leal 2(%rax), %ebx//将rax变量加2赋值给edx寄存器也是foo1变量.
xorl %eax, %eax
call __printf_chk
movl %ebx, %edx
movl $.LC1, %esi
movl $1, %edi
xorl %eax, %eax
call __printf_chk
xorl %eax, %eax
popq %rbx
.cfi_def_cfa_offset 8
ret
.cfi_endproc
实验二:
#include <stdio.h>
int foo = 10;
int bar = 15;
int main(void)
{
int ss = foo + 1;
int foo1 = foo + 2;
printf("ss=%d\\n", ss);
printf("foo1=%d\\n", foo1);
return0;
}
编译命令:
g++ -S -O2 test2.cpp
编译结果的部分汇编:
main:
.LFB30:
.cfi_startproc
pushq %rbx
.cfi_def_cfa_offset 16
.cfi_offset 3, -16
movl foo(%rip), %ebx //将foo变量从内存加载到寄存器ebx中
movl $.LC0, %esi
movl $1, %edi
xorl %eax, %eax
leal 1(%rbx), %edx//将rbx寄存器加1赋值给edx寄存器也是ss变量. //rbx是64位寄存器,它的低32位是ebx寄存器.
call __printf_chk
leal 2(%rbx), %edx//直接取rbx寄存器,加2赋值给foo1变量
movl $.LC1, %esi
movl $1, %edi
xorl %eax, %eax
call __printf_chk
xorl %eax, %eax
popq %rbx
.cfi_def_cfa_offset 8
ret
.cfi_endproc
结论:第一实验加入了内存屏障中,两次分别从内存中加载foo变量到寄存器中,然后进行操作,第二个实验中取出了内存屏障,第一次将foo变量从内存中加载到了寄存器中,进行第一次操作,然后第二次并没有从内存中加载,而是直接去寄存器中的值去操作,由此可以看出屏障的后面是不可以缓存变量在寄存器中的,而是屏障后面的变量是需要重新从主存中加载的.
3.2 Java的内存屏障
从上文可知:一个load操作需要进入loadbuffer中的,然后在从内存中去加载,一个store操作需要进入storebuffer然后在写入内存.而两个buffer之间是异步,导致出现了不同的乱序(重排),java定义了一系列的内存屏障来指定指令的执行顺序.
Java中的内存中的内存屏障:
LoadLoad 屏障
StoreStore屏障
LoadStore 屏障
StoreLoad屏障
序列
Load1,Loadload,Load2
Store1,StoreStore,Store2
Load1,LoadStore,Store
Store1,StoreLoad,Load
作用
保证Load1所要读入的数据能够在被Load2和后续的load指令访问前读入。
保证Store1的数据在Store2以及后续Store指令操作相关数据之前对其它处理器可见
确保Load1的数据在Store2和后续Store指令被刷新之前读取。
确保Store1的数据在被Load2和后续的Load指令读取之前对其他处理器可见。
对buffer的影响
在Load buffer插入屏障,清空屏障之前的Load操作,然后才能执行屏障之后的Load操作.
在Store buffer插入屏障,清空屏障之前的Store操作,然后才能执行屏障之后的store操作.
在Load buffer插入屏障,清空屏障之前的Load操作,然后才能执行屏障之后的Store操作.
在Load buffer, Store buffer中都插入屏障,必须清空屏障之前的Load操作并且清空屏障之前的store操作,然后才能执行屏障之后的Load操作,或store操作.
StoreLoad屏障有可以同时获得其它三种屏障(loadload,loadstore,storestore)的的效果,但是StoreLoad是一个比较耗性能的屏障.因为StoreLoad屏障在Loadbuffer, Store buffer中都插入屏障,必须清空屏障之前的Load操作并且清空屏障之前的store操作,然后才能执行屏障之后的Load操作,或store操作.这使得之后的读指令不能从store buffer中直接获取,只能从缓存中获取,综合起来说,storeload屏障最耗性能。
3.2 Release 和Acquire,fence
Java中又定义了release和acquire,fence三种不同的语境的内存栅栏.
如上图,loadLoad和loadStore两种栅栏对应的都是acquire语境,,acquire语境一般定义在java的读之前;在编译器阶段和cpu执行的时候,acquire之后的所有的(读和写)操作不能越过acquire,重排到acquire之前,acquire指令之后所有的读都是具有可见性的.
如上图,StoreStore和LoadStore对应的是release语境,release语境一般定义在java的写之后,在编译器和cpu执行的时候,所有release之前的所有的(读和写)操作都不能越过release,重排到release之后,release指令之前所有的写都会刷新到主存中去,其他核的cpu可以看到刷新的最新值.
对于fence,是由storeload栅栏组成的,比较消耗性能.在编译器阶段和cpu执行时候,保证fence之前的任何操作不能重排到屏障之后,fence之后的任何操作不能重排到屏障之前.fence具有acquire和release这两个都有的语境,即可以将fence之前的写刷新到内存中,fence之后的读都是具有可见性的.
3.3 x86中的内存栅栏与实现
内存屏障,也称内存栅栏,内存栅障,屏障指令等,是一类同步屏障指令,是CPU或编译器在对内存随机访问的操作中的一个同步点,使得此点之前的所有读写操作都执行后才可以开始执行此点之后的操作。语义上,内存屏障之前的所有写操作都要写入主存;内存屏障之后的读操作,直接读取的主存,可以获得内存屏障之前的写操作的结果。
完全内存屏障(full memory barrier)保障了早于屏障的内存读写操作的结果提交到内存之后,再执行晚于屏障的读写操作,在loadbuffer和storebuffer中插入屏障,清空屏障之前的读和写操作。X86中对应MFence;
内存读屏障(read memory barrier)仅确保了内存读操作.在loadbuffe中插入屏障,清空屏障之前的读操作;LFence
内存写屏障(write memory barrier)仅保证了内存写操作.在storebuffer中插入屏障,清空屏障之的写操作; SFence
接下来我们看看在源码中如何实现,主要看open jdk1.9,为什么,jdk1.8里面对栅栏的实现千奇百怪,作者能力有限,不能全部了解jvm开发者当时为啥那么实现,而jdk1.9的实现相对比比较清晰.
在jdk1.9中对storestore,storeload,loadload,loadstore的实现如下:
static inline void compiler_barrier() {
__asm__ volatile ("" : : : "memory");
}
inline void OrderAccess::loadload() { compiler_barrier(); }
inline void OrderAccess::storestore() {compiler_barrier(); }
inline void OrderAccess::loadstore() { compiler_barrier(); }
inline void OrderAccess::storeload() { fence(); }
从上面我们可以看出对除了对loadstore使用了fence()函数,而loadload,loadstore, storestore都是使用的编译器屏障.查看jdk1.8,发现loadload,loadstore对应的acquire语境,storestore对应的是release语境,这与之前介绍的是一致.
在jdk1.9中对storestore,storeload,loadload,loadstore的实现如下:
inline void OrderAccess::acquire() { compiler_barrier(); }
inline void OrderAccess::release() { compiler_barrier(); }
inline void OrderAccess::fence() {
if(os::is_MP()) {
//always use locked addl since mfence is sometimes expensive
#ifdef AMD64
__asm__ volatile ("lock; addl $0,0(%%rsp)" : : :"cc", "memory");
#else
__asm__ volatile ("lock; addl $0,0(%%esp)" : : :"cc", "memory");
#endif
}
compiler_barrier();
}
可以发现acquire,release也是编译器屏障,而fence的实现好像比较复杂.
os::is_MP()判断是否是多核,如果是单核,那么就不存在内存不可见或者乱序的问题,只要保证编译器不乱序就好,所以使用编译器屏障.
__asm__ volatile ("lock; addl$0,0(%%esp)" : : : "cc", "memory");
解释一下:
__asm__ :代表汇编代码开始.
__volatile__:禁止编译器对代码进行某些优化.
Lock :汇编代码,让后面的操作是原子操作.lock指令会锁住操作的缓存行(cacheline),一般用于read-Modify-write的操作例如 addl.“cc”,”mmeory”:cc代表的是寄存器,memory代表是内存;这边同时用了”cc”和”memory”,来通知编译器内存或者寄存器内的内容已经发生了修改,要重新生成加载指令(不可以从缓存寄存器中取).
这边的read/write请求不能越过lock指令进行重排,那么所有带有lock prefix指令(lock ,xchgl等)都会构成一个天然的x86 Mfence(读写屏障),这里用lock指令作为内存屏障,然后利用asm volatile("" ::: "cc,memory")作为编译器屏障.
AMD64这边判断是否是64位,64位机器中使用rsp栈指针寄存器,32位机器中使用32位机器中使用esp栈指针寄存器.
可以看到jvm开发组没有使用x86的内存屏障指令(mfence,lfence,sfence),个人觉得有以下原因:
1.x86/64的Intel平台是强一致内存模型,(能够让所有的处理器在任何时候任何指定的内存地址上都可以看到完全相同的值).
2.x86/64的Intel平台能够保证读读,写写,读写这些是有序的.
基于以上两个原因hotSpot对loadload,loadstore,storestore,只要利用编译器屏障,保证程序不能重排就好.对于storeload屏障,利用了编译器屏障,还使用了lock addl作为内存屏障,原因是load,和store指令不能越过lock指令,形成了天然的MFence,没有使用MFence是因为在某些平台上,MFence的代价比较大.
4 浅析JVM中的volatile
4.1 c/c++的volatile
Java的volatile语义是从c/c++的volatile发展而来,并且进行增强,首先了解一下c/c++的volatile的语义.
c/c++中的volatile,能确保可见性。即:volatile变量的写操作,不会缓存到寄存器中,而是直接回写主存中去。而volatile变量的读取,也不会从寄存器中读取,而是从主存中读取。这就是说c/c++volatile的第一特性:易变性。
c/c++的volatile的第二特性:不可优化性。即不要对volatile变量进行各种激进的优化,保持变量原有的语义,不能被优化掉。
c/c++的volatile的第三特性:顺序性。基于前面的两个特性,让Volatile经常被解读为一个为多线程而生的关键词。但更要命的是很多程序员往往会忽略掉顺序性,这使得c/c++ volatile很难被正确使用的重要原因。同时,c/c+的volatile是不能完全保证顺序性的。
上面这段伪代码,b变量被声明为一个volatile的变量。在thread1去修改变量,而thread2去读取变量。由于b变量声明成一个volatile变量,在编译器编译时,不会从寄存器读取变量,而是主存中去读变量,同时也不会通过各种激进的优化。即保证volatile的易变性,不可优化行。即:thread1修改b变量,thread2就能读取到变化的b变量。那么问题来了,上面这段伪代码能否确保在b=1的情况下,a等于2。答案显然是否定的。因为编译器会对volatile变量与非volatile变量进行乱序优化。即b=1,有可能在a=2前先执行。
但是在a变量同时也申明成volatile,那么在编译阶段就能确保在thread1中a=2先执行,b=1后执行,不乱序。那么在thread2中,a能否确保看到等于2呢?答案是否定的。
因为即使c/c++volatile变量阻止了编译器对volatile变量间的乱序优化,但是终于生成的指令还是交给cpu来执行的。CPU本身为了提高代码运行的效率,也会对代码的执行顺序进行调整,即cpu级别的乱序优化。因此,即便把所有的变量全部都声明为volatile,杜绝了编译器的乱序优化,但是针对生成的汇编代码,CPU有可能仍旧会乱序执行指令,导致程序依赖的逻辑出错,c/c++的volatile对此无能为力。
其实,针对这个多线程的应用,真正正确的做法,是构建一个happens-before语义。也就是java对volatile的语义增强,可以防止volatile变量与普通变量或volatile变量之间的重排序,并且保证cpu执行的时候不会重排.
4.2 java中的volatile
jSR-133专家组增强volatile的内存语义:严格限制编译器和处理器对volatile变量和普通变量之间的重排序,确保volatile的写-读和监视器的释放-获取一样,具有相同的内存语义。
Java中的volatile在读写时候添加的内存屏障如下:
//初始化
Int a = 1; volatile int v = 9;
Volatile的写
Volatile的读
Storestore;
v= a;
Storeload;
a = v;
loadload;
loadstore;
即:
release();
v= a;
fence();
即:
a = v;
acquire();
解释一下,对volatile变量的写,在前面插入storestore屏障(release语义),这样就能保证所有在volatile变量写之前写的数据,可以在volatile变量写之前刷入主存,storeload这边的可以将volatile变量刷入主存,还可以防止volatile变量写之后又一个volatile变量的读,会越过这个volatile变量的写,保证volatile变量可以从内存中读数据,而不是从storebuffer中读取.
对于volatile变量的读,在后面插入了loadload,loadstore,这样就可以volatile变量之后的操作都不能重排到volatile变量的读之前,同时保证了volatile变量之后的变量的读,都是内存中的最新数据.
总结:
1. 有volatile的标识的变量具有可见性.对volatile变量的写会被刷到主存到去,对volatile变量的读,会直接从主存到读,不会对volatile的变量进行任何的(寄存器的)缓存.
2. 任何变量的写在volatile变量写之前,那么这个变量在volatile变量读之后可见的.
那样只要在第一个例程中对第二个变量b加入volatile的标识,那么就可以保证程序正确性了,这就是volatile变量的写happen-before在volatile变量读之前.
4.3 volatile与release_store_fence,release_store,load_acquire
release_store_fence,与load_acquire的具体代表什么意思?
\\openjdk-jdk9-jdk9\\hotspot\\src\\share\\vm\\runtime\\orderAccess.inline.hpp文件中的
release_store_fence
inline void OrderAccess::release_store_fence(volatilejbyte* p, jbyte v) { specialized_release_store_fence(p, v);}
调用得了
template<typename T> inline voidOrderAccess::specialized_release_store_fence(volatile T* p, T v) { ordered_store<T, RELEASE_X_FENCE>(p,v); }
RELEASE_X_FENCE,这个有点像是在操作x之前插入了release,在操作x之后插入了fence?具体是不是这样呢?
接着找到:
inline voidOrderAccess::ordered_store(volatile FieldType* p, FieldType v) {
ScopedFence<FenceType> f((void*)p);
store(p, v);
}
这段代码定义了一个变量,然后进行存储.神器之处就在于ScopedFence<FenceType>f((void*)p)的定义,
c++对一个类的变量的初始化,首先会调用构造函数,然后会在对变量进行回收的时候也就是调用结束的时候,调用析构函数.
可以看出构造函数调用了prefix函数,析构函数调用了post函数
然后对于RELEASE_X_FENCE的中prefix和postfix的定义:
template<> inline voidScopedFenceGeneral<RELEASE_X_FENCE>::prefix() { OrderAccess::release(); }
template<> inline voidScopedFenceGeneral<RELEASE_X_FENCE>::postfix() {OrderAccess::fence(); }
如上:在写之前调用了release即storestore,在写之后调用了fence即storeload.
对于load_acquire相关源码:
inline jbyte OrderAccess::load_acquire(volatilejbyte* p) { returnspecialized_load_acquire(p); } template<typename T> inline T OrderAccess::specialized_load_acquire (volatile T* p) { return ordered_load<T, X_ACQUIRE>(p); } template<> inline voidScopedFenceGeneral<X_ACQUIRE>::postfix() { OrderAccess::acquire(); } template <typename FieldType,ScopedFenceType FenceType> inline FieldTypeOrderAccess::ordered_load(volatile FieldType* p) { ScopedFence<FenceType> f((void*)p); return load(p); }
从上代码可知,load_acquire在读之前调用了acquire即loadload或loadstore.
inline void OrderAccess::release_store(volatilejbyte* p, jbyte v) { specialized_release_store(p, v); }
template<typename T> inline voidOrderAccess::specialized_release_store (volatile T* p, T v) {ordered_store<T, RELEASE_X>(p, v); }
template<> inline voidScopedFenceGeneral<RELEASE_X>::prefix() { OrderAccess::release(); }
从上面代码可知,releasestore只在store之前插入了release函数.而并没有插入storeload.
4.2 浅析volatile的源码
在hotSpot中对volatile的实现的地方有多处,这里主要看的是从oops中的实现.
找到oop中对volatile读写的实现:
\\openjdk-jdk9-jdk9\\hotspot\\src\\share\\vm\\oops\\oop.inline.hpp
voidoopDesc::obj_field_put_volatile(int offset, oop value) {
OrderAccess::release();
obj_field_put(offset, value);
OrderAccess::fence();
}
对volatile的字段写之前插入了release,写之后插入了fence,跟之前所描述是一致的.
jint oopDesc::int_field_acquire(intoffset) const
{ returnOrderAccess::load_acquire(int_field_addr(offset)); }
从上文可知,load_acquire在volatile的读之后插入acquire也就是loadload栅栏.
5.1 volatile与unsafe中的黑魔法
Unsafe.java里面有API类似getObjectVolatile,putObjectVolatile等,这两个api具体有什么用处?
可以从名称看出来这与volatile有关.但是具体有什么作用,我们还是来查看源码.
可以找到getObjectVolatile在unsafe.cpp中的实现:
UNSAFE_ENTRY(jobject,Unsafe_GetObjectVolatile(JNIEnv *env, jobject unsafe, jobject obj, jlongoffset))
UnsafeWrapper("Unsafe_GetObjectVolatile");
oop p = JNIHandles::resolve(obj);
void* addr =index_oop_from_field_offset_long(p, offset);
volatile oop v;
if (UseCompressedOops) {
volatile narrowOop n = *(volatilenarrowOop*) addr;
(void)const_cast<oop&>(v =oopDesc::decode_heap_oop(n));
} else {
(void)const_cast<oop&>(v =*(volatile oop*) addr);
}
OrderAccess::acquire();
return JNIHandles::make_local(env, v);
UNSAFE_END
我们来看看到代码volatile oopv; 定义了一个c++的volatile,进行一个读取操作;c++ volatile具有的语义是每次都能够从内存中看到的最新的,oop这个类是java中的对象类在c++中对应的实现类,即使用c++的语义读取了这个对象的引用地址,保证了可见性.而后是acquire指令.
OrderAccess::acquire();
从上文可知acquire是有loadload,和loadStore组成的这就是volatile变量所要插入的栅栏,并且可以保证,acquire之后的读都是具有可见性的,x86_64在jdk9中是有编译器栅栏实现的,可以推断出,任意的一个变量通过getObjectVolatile是可以获取javavolatile的读的语义的.
找到putObjectVolatile在unsafe.cpp中的具体实现,
UNSAFE_ENTRY(void,Unsafe_SetObjectVolatile(JNIEnv *env, jobject unsafe, jobject obj, jlongoffset, jobject x_h))
UnsafeWrapper("Unsafe_SetObjectVolatile");
oop x = JNIHandles::resolve(x_h);
oop p = JNIHandles::resolve(obj);
void* addr =index_oop_from_field_offset_long(p, offset);
OrderAccess::release();
if (UseCompressedOops) {
oop_store((narrowOop*)addr, x);
} else {
oop_store((oop*)addr, x);
}
OrderAccess::fence();
UNSAFE_END
opp_store是Java Object变量的写,在这之前插入了release,在之后插入了fence,这边又有了javavolatile写的语义,因为release对应的loadStore,storestore的两个栅栏;fence对应的是storeload栅栏,这与java volatile的写所需要的栅栏是一致的.
总结:一个引用要变成volatile的读的语义,只要用getObjectVolatile,一个引用要想有volatile写的语义,主要putObjectvolatile.
5.2 volatile的相关特性
5.2 volatile的写
从上文可知道,volatile的写所插入的storeLoad是一个耗时的操作,所以出现了一个对volatile写的升级版本.
AtomicIntegeri=new AtomicInteger(5);
i.lazySet(5);
如上利用laySet方法进行性能优化,在实现上对volatile的写只会在之前插入storestore栅栏,这样可以保证的volatile写之前的写都不能重排到volatile写之后,volatile之前的写都会在volatile变量写之前刷入主存,但是这个方法虽然提高了效率,但是volatile的写并不能被马上被其它线程看到,通常需要几纳秒才能被其它线程看到,这个时间比较短,所以代价是可以忍受的.
5.2.2 volatile的读
网上流传着volatile的读与普通变量是差不多的性能,但是如果你读了本文,你就知道,volatile的读其实也是有代价,而且相比普通的变量的读要慢的多.原因是,volatile的变量不仅要从内存中读,还使得它之后的所读的变量也是从内存中读的.
为此常常将循环中对volatile的变量的读,提取到循环之外.
Volatile int I= 0;
For(int j = 0;j < 100000;j++){
Int p = I;
}
优化为
Int p = I;
For(int j = 0;j < 100000;j++){
//直接操作p
}
如上,这样就可以使得volatile变量缓存在寄存器中,那么就不用每次都去从主存中去读取,这样就可以大大的提高性能.
5.2.3 volatile与原子性
Volatile标识的变量的纯粹的读和写都是原子,普通long变量,double变量的读写是不具有原子性的,但是对volatile的i++,i—操作都不是原子操作,这是volatile的不足.
Javap -c Test2
public class Test2
{
private staticvolatile int i=0;
i++;
public staticvoid main(java.lang.String[]);
Code:
0: getstatic #10// Field i:I
3: iconst_1
4: iadd
5: putstatic #10// Field i:I
8: return
如上面代码所示:i++是由4个操作组合而成,volatile的加一操作并没有保证原子操作,所以如果有多个线程对volatile进行操作,需要加锁,或者使用Atomic类.
转载请注明来源 http://blog.csdn.net/w329636271/article/details/54616543 老师:leader 合作者<wangzhancheng.com@qq.com>
以上是关于Volatile从入门到放弃的主要内容,如果未能解决你的问题,请参考以下文章